Download as PDF, PPTX







![Sequential File Implementation
● #include <iostream.h>
● #include <fstream.h>
● #include <stdlib.h>
●
● Void main() {
● Int i, Roll[N] = { 171,717, 834, 394, 475 };
● float Percentage[N]= {45.3, 84.5, 95.0,
48.2, 39.2 };
● Char* Name[N] = {“wajid”, “Aashir”,
“Luqman”, “Tushar”, “Waseem” };
● // Step1: Create ofstream and ifstream
objects
● Ofstream outFile; ifstream inFile;
● // Step 2: Open file for output
● outFile.open(“percent.dat”, ios::out);
● // Step 3 Test weather open operation is
successful
● If (!outFile) {
– cout<<”File could not open “;
– Exit(1);
● Else
– Cout<<”n File open successfullyn”;
● //Step 4: Write to file
● For( i=0; i<N; i++)
– OutFile <<Name[i]<<' '<<Roll[i]<< ' '
<<Percentage[i]<<endl;
● cout<<”n File write successfully. n”;
● // Step 5: Close file
● outFile.close();](https://image.slidesharecdn.com/filesanddatastorage-150528091411-lva1-app6892/75/Files-and-data-storage-12-2048.jpg)





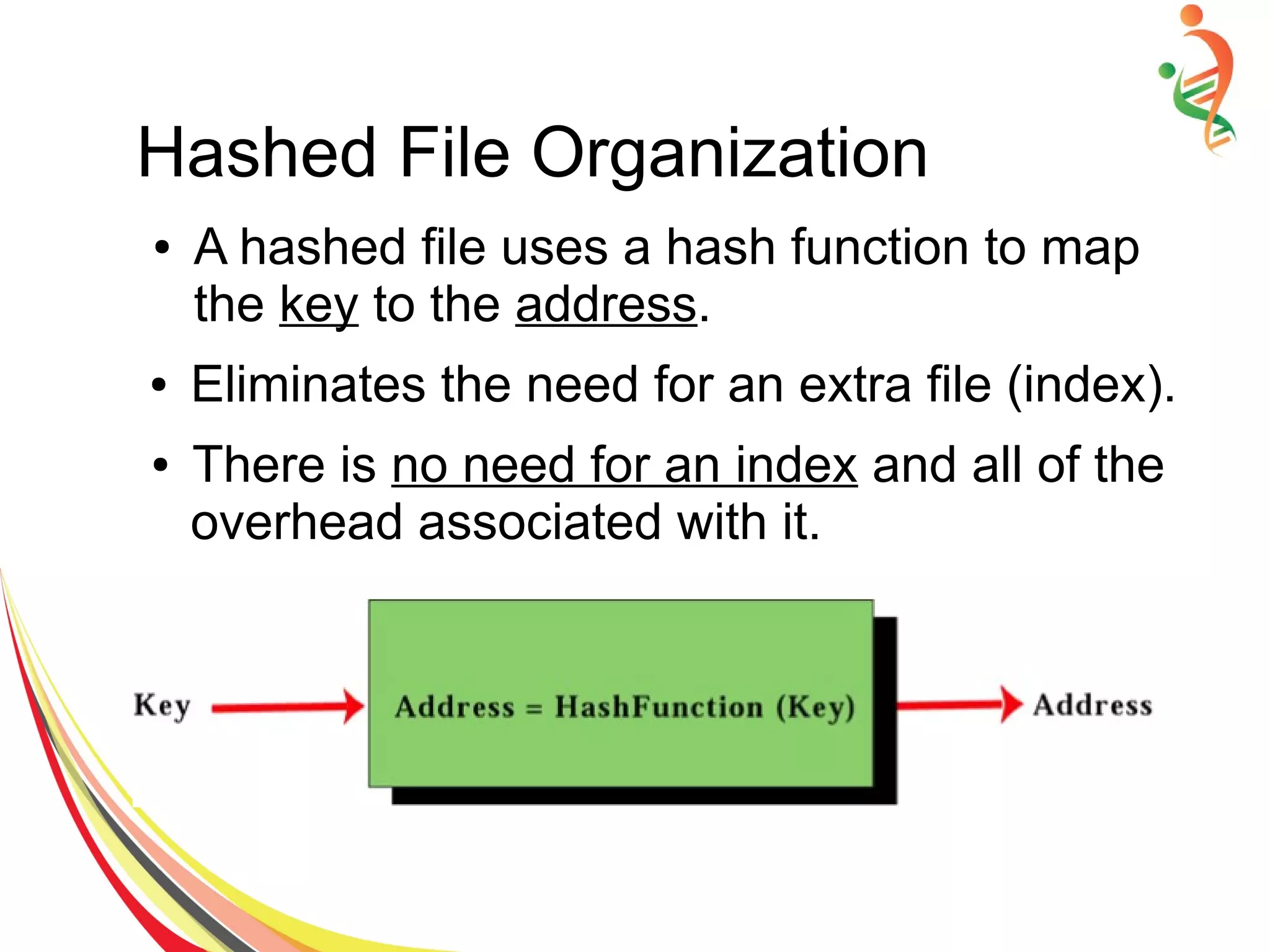








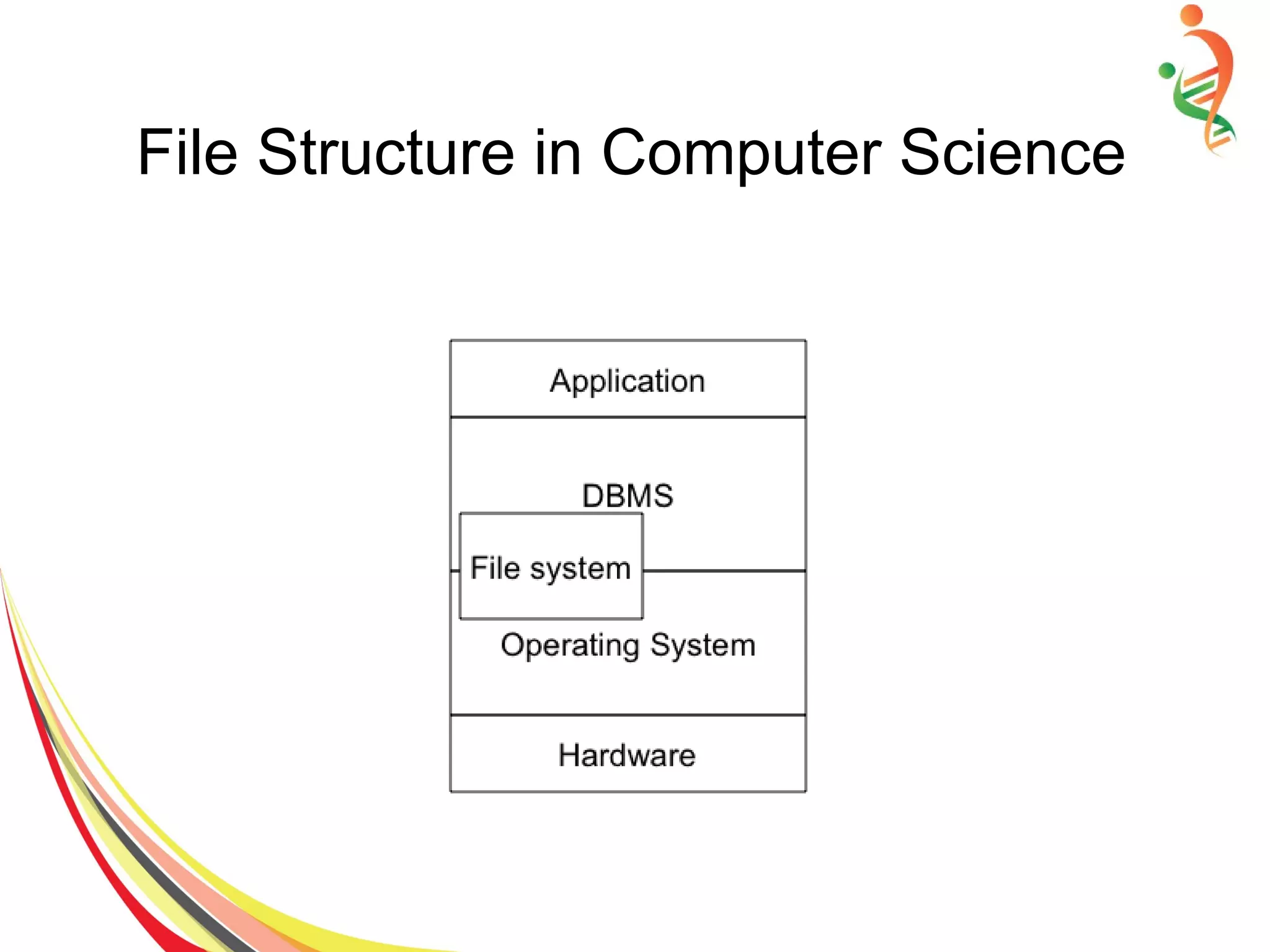
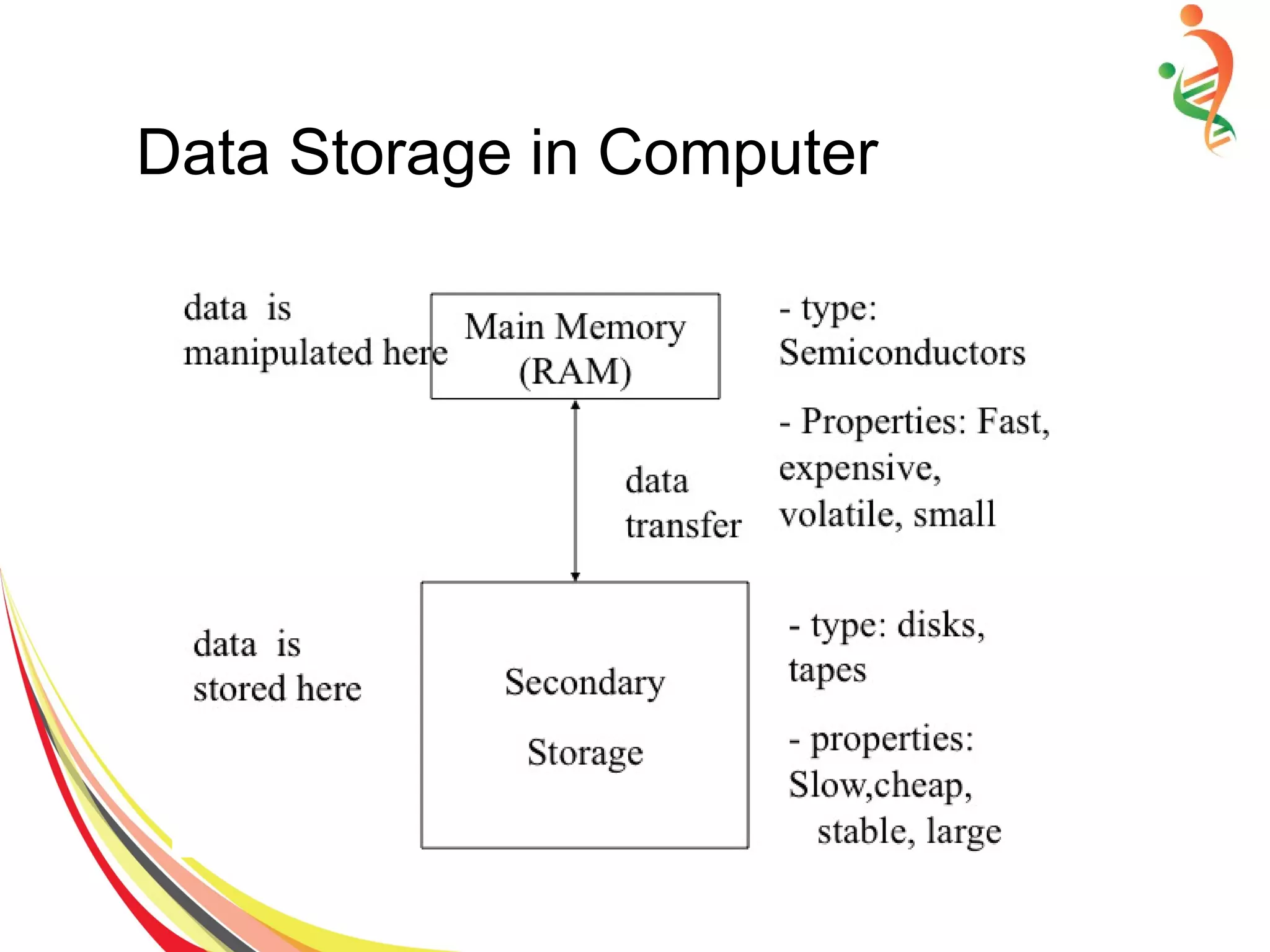
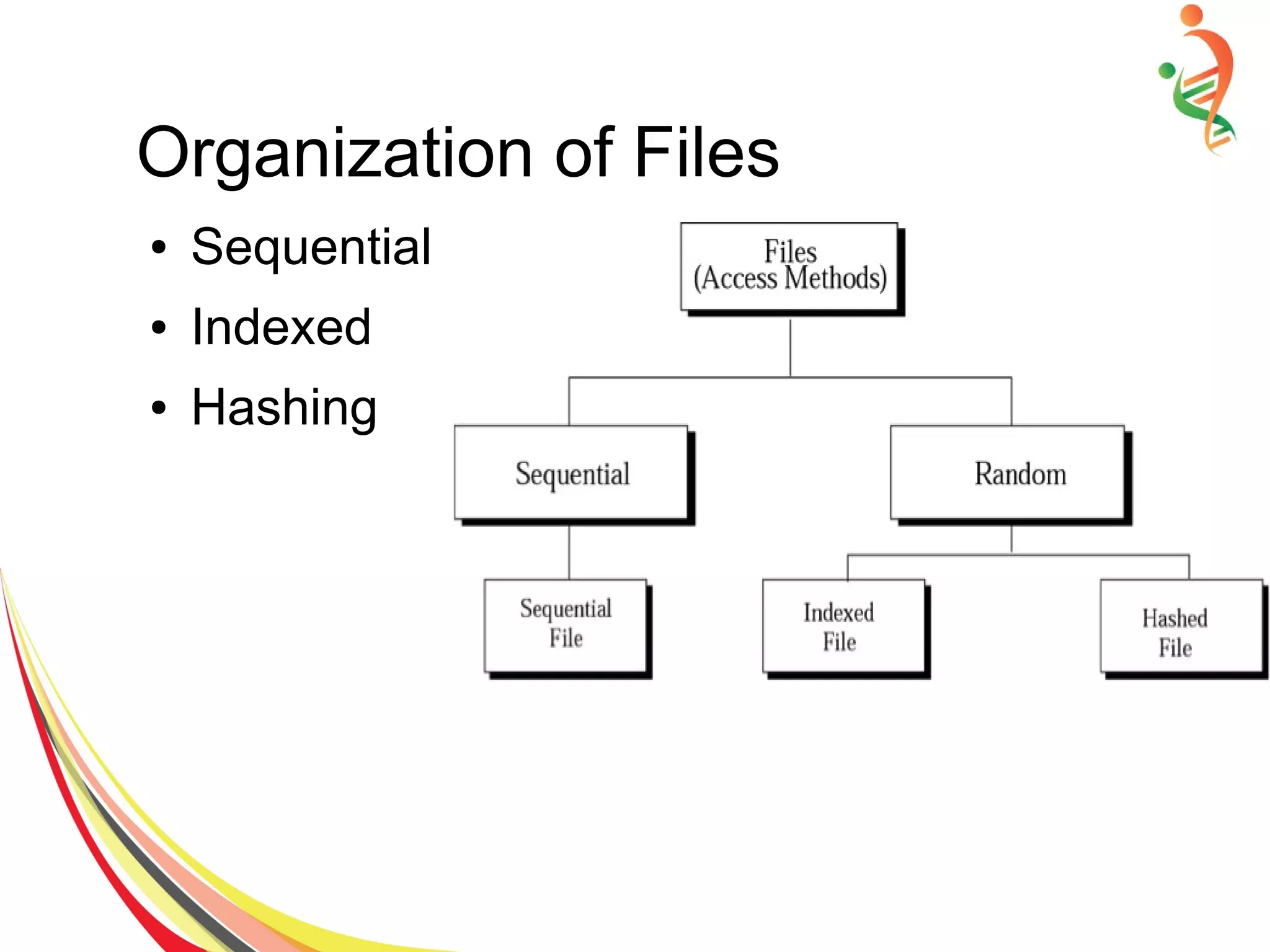
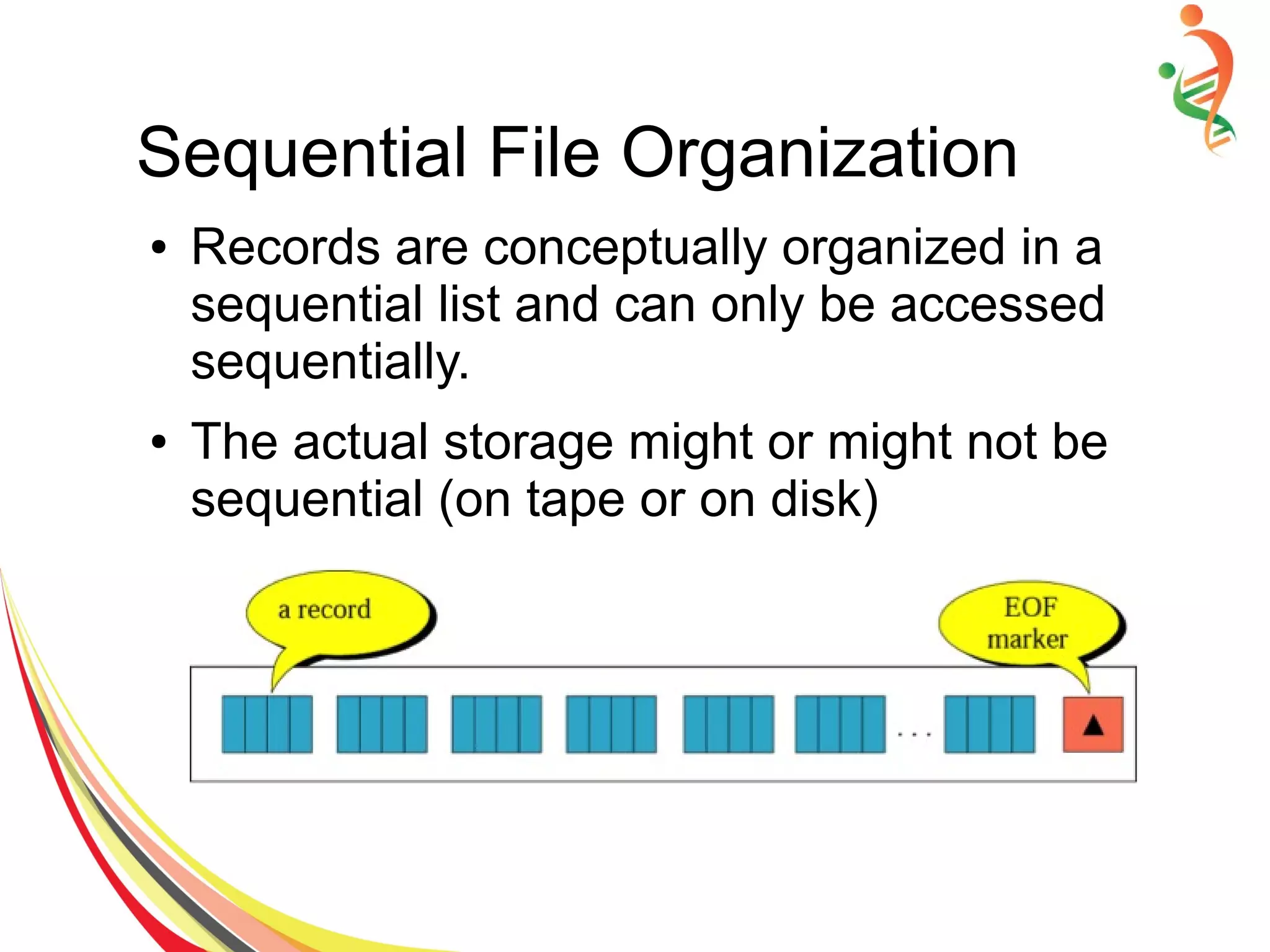
The document discusses different methods of file and data storage in computers. It describes how data is organized and stored in both main memory and secondary storage. There are three main file organization structures - sequential, indexed, and hashed. Sequential files store records sequentially and can only be accessed in order. Indexed files use an index to map keys to record locations for faster retrieval. Hashed files apply a hash function to map keys directly to storage locations.





























































































