Recommended
PPTX
PPTX
PPTX
Estimating conversionrateindisplayadvertisingfrompastperformancedata
PDF
Fingind the right consumer - optimizing for conversion in display advertising...
PDF
PPT
クリック課金型広告における、統計的入札単価決定法に関する一般論
PDF
Towards a robust modeling of temporal interest change patterns for behavioral...
PPTX
PDF
[読会]Causal transfer random forest combining logged data and randomized expe...
PDF
PDF
[読会]Logistic regression models for aggregated data
PDF
[読会]A critical review of lasso and its derivatives for variable selection und...
PDF
finite time analysis of the multiarmed bandit problem
PDF
PDF
logistic regression in rare events data
PDF
Nmp for quantum_chemistry
PDF
Introduction of introduction_to_group_theory
PDF
Squeeze and-excitation networks
PDF
[読会]Long tail learning via logit adjustment
PDF
Real time bid optimization with smooth budget delivery in online advertising
PDF
Real time bidding algorithms for performance-based display ad allocation
PDF
Joint optimization of bid and budget allocation in sponsored search
PDF
PDF
[読会]Themis decentralized and trustless ad platform with reporting integrity
PDF
[読会]P qk means-_ billion-scale clustering for product-quantized codes
PDF
Dynamic filters in graph convolutional network
PDF
Dl study g_learning_to_remember_rare_events
PDF
normalized online learning
PDF
slideshare_ナハトエース会社説明資料_2025/12/11_SlideShare.pdf
PDF
SNS_Marketing_Company_ナハトエース会社説明資料_2025/12/10_SlideShare.pdf
More Related Content
PPTX
PPTX
PPTX
Estimating conversionrateindisplayadvertisingfrompastperformancedata
PDF
Fingind the right consumer - optimizing for conversion in display advertising...
PDF
PPT
クリック課金型広告における、統計的入札単価決定法に関する一般論
PDF
Towards a robust modeling of temporal interest change patterns for behavioral...
PPTX
More from shima o
PDF
[読会]Causal transfer random forest combining logged data and randomized expe...
PDF
PDF
[読会]Logistic regression models for aggregated data
PDF
[読会]A critical review of lasso and its derivatives for variable selection und...
PDF
finite time analysis of the multiarmed bandit problem
PDF
PDF
logistic regression in rare events data
PDF
Nmp for quantum_chemistry
PDF
Introduction of introduction_to_group_theory
PDF
Squeeze and-excitation networks
PDF
[読会]Long tail learning via logit adjustment
PDF
Real time bid optimization with smooth budget delivery in online advertising
PDF
Real time bidding algorithms for performance-based display ad allocation
PDF
Joint optimization of bid and budget allocation in sponsored search
PDF
PDF
[読会]Themis decentralized and trustless ad platform with reporting integrity
PDF
[読会]P qk means-_ billion-scale clustering for product-quantized codes
PDF
Dynamic filters in graph convolutional network
PDF
Dl study g_learning_to_remember_rare_events
PDF
normalized online learning
Recently uploaded
PDF
slideshare_ナハトエース会社説明資料_2025/12/11_SlideShare.pdf
PDF
SNS_Marketing_Company_ナハトエース会社説明資料_2025/12/10_SlideShare.pdf
PDF
2026magazine tour tabisentsunagu たびせんつなぐ
PDF
動画『【続報】新税率は35%超!M&Aの税金が大幅増税|3.5億円から対象に』で投影した資料
PDF
【会社紹介資料】 株式会社カンゲンエージェント [ 11 月 30 日作成資料公開 ].pdf
PDF
1ページでわかるTAPP_20251211________________
PDF
Estimating conversion rate in display advertising from past performance data 1. Estimating Conversion Rate in
Display Advertising from Past
Performance Data
Kuang-chin Lee, Burkay Orten, Ali Dasdan, Wentong Li
Turn Inc., Redwood City, CA, USA
(KDD 2012)
2. 3. Overview of Ad Call Flow
・本論文の貢献
- 広告出稿者側が出稿すべき広告の選定が可能になる
- 入札価格の決定に利用できる ← 後述の論文を参照
4. Problem Setup and Formulation
・最適な広告の選定
・CVを確率的に発生するイベントと捉える
・最適な広告の選定
(1)
(2)
(3)
ベルヌーイ分布を仮定ベルヌーイ分布を仮定ベルヌーイ分布を仮定ベルヌーイ分布を仮定
5. Problem Setup and Formulation
・ユーザ個人のCVRを見積もらずにクラスタリングして最尤推定で計算
(4)
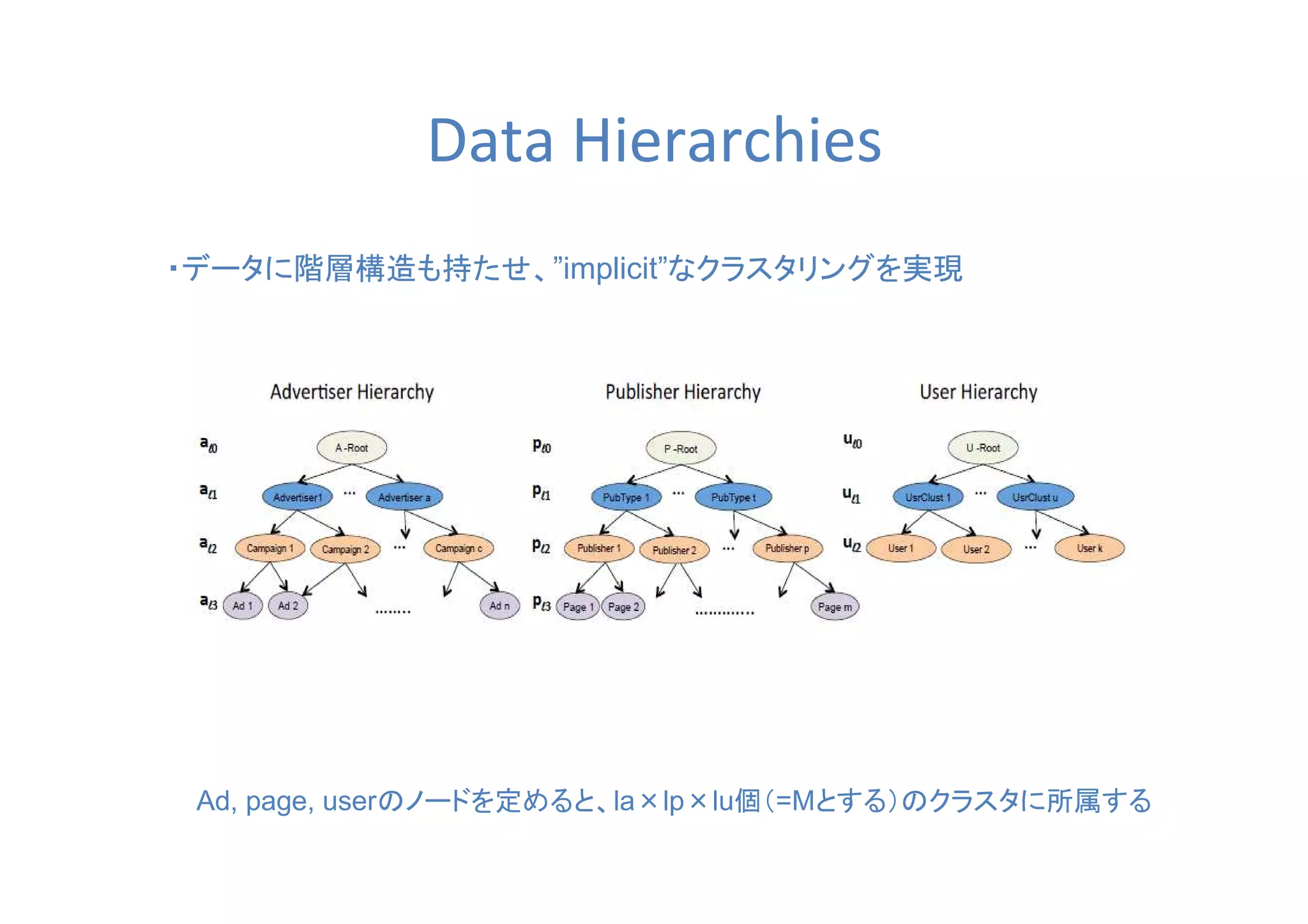
User, page, adの組み合わせでのデータスパースネスを
データに階層構造を持たせることで解決
Impression数数数数Impression数数数数
CV数数数数CV数数数数
6. 7. Past Performance at Different
Hierarchical Levels
・CV率の再定義
提案) 1つ1つのCVR予測器は弱いが、組み合わせることで強力にできる
・データの階層によってM個のpi,j,kが定義できる
- Ex.)
(8)
userと同じくと同じくと同じくと同じくpageとととと
adもグループ化もグループ化もグループ化もグループ化
8. Combining Estimators using
Logistic Regression
・ロジスティック回帰を利用して各予測器に最適な重み付けを行う
・各予測器を組み合わせたCVR予測の再定義
※最適なパラメータベクトルββββを決める必要がある
(9)
( ) xT
e
xf β
β −
+
=
1
1
;
この先この先この先この先i,j,kの表示が落とされますが、の表示が落とされますが、の表示が落とされますが、の表示が落とされますが、
あるあるあるあるi,j,kについて述べられていると考えてくださいについて述べられていると考えてくださいについて述べられていると考えてくださいについて述べられていると考えてください
9. Cobining Estimators using Logistic
Regression
・各PVに対する対数尤度関数
ユーザ、ページ、広告の組み合わせ時の正確なCVRの見積もり手法
(10)
・最適なβを求める(L-BFGS-B法などを利用)
(11)
同キャンペーン中の同キャンペーン中の同キャンペーン中の同キャンペーン中のs回目の回目の回目の回目の
impressionにおける数値における数値における数値における数値
両者ともベクトル両者ともベクトル両者ともベクトル両者ともベクトル
(ボールドになっていなくてわかりにくく(ボールドになっていなくてわかりにくく(ボールドになっていなくてわかりにくく(ボールドになっていなくてわかりにくく
てすみません)てすみません)てすみません)てすみません)
10. Data Imbalance & Output
Calibration
・CV/非CV率が非常に低い
- CVしたデータは全て利用
- 非CVデータはサンプリングして利用 ← 影響は調査する
・スコアを区間で分割し、キャリブレーション
(13)
(14)
1...,0 121 ≤<≤ +nvvvロジスティック回帰の結果をロジスティック回帰の結果をロジスティック回帰の結果をロジスティック回帰の結果を ののののn binに等分割し再定義に等分割し再定義に等分割し再定義に等分割し再定義
真の真の真の真のCVRに近づけるために近づけるために近づけるために近づけるため
に行うに行うに行うに行う
単純に単純に単純に単純にbin内のサンプル内のサンプル内のサンプル内のサンプル
ののののCVRの計算の計算の計算の計算
i,j,kの枠は排除(?)の枠は排除(?)の枠は排除(?)の枠は排除(?)
(分割数は手探り?)(分割数は手探り?)(分割数は手探り?)(分割数は手探り?)
11. Data Imbalance & Output
Calibration
・区間ごとのCV率の凹凸のスムージングはPool Adjacent Violators
Algorithm(PAVA)を利用
― 等調回帰をベースとしたものを使って指数関数にフィットするように調整
・実際のCVRは内分して算出
(15)
12. 13. 14. 15. 16. Baseline Estimators vs
Logistic Regression
・実験条件
- 2012年1月の2週間のログを利用
始めの1週間を訓練、残りの1週間をテストとする
- 広告群は5種類(車、贈り物・・・など、それぞれ100万単位のPV数/日)
- あるユーザがページ、広告を見たときにCVするかしないかを予測
17. Baseline Estimators vs
Logistic Regression
・提案手法の効果
-Baseline1:
ユーザの年齢、性別、居住地域などのデモグラフィックな属性による
クラスタリングと広告群による推定
- Baseline2:
広告群を見たユーザと特定の広告による推定
(19)
(20)
※B1、B2はbaggingしてない
18. 19.



























![[読会]Causal transfer random forest combining logged data and randomized expe...](https://cdn.slidesharecdn.com/ss_thumbnails/causaltransferrandomforest-combiningloggeddataandrandomizedexperimentsforrobustprediction-211229095227-thumbnail.jpg?width=640&height=640&fit=bounds)

![[読会]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[読会]A critical review of lasso and its derivatives for variable selection und...](https://cdn.slidesharecdn.com/ss_thumbnails/acriticalreviewoflassoanditsderivativesforvariableselectionunderdependenceamongcovariates-211229094859-thumbnail.jpg?width=640&height=640&fit=bounds)






![[読会]Long tail learning via logit adjustment](https://cdn.slidesharecdn.com/ss_thumbnails/long-taillearningvialogitadjustment-211229095016-thumbnail.jpg?width=640&height=640&fit=bounds)




![[読会]Themis decentralized and trustless ad platform with reporting integrity](https://cdn.slidesharecdn.com/ss_thumbnails/themisdecentralizedandtrustlessadplatformwithreportingintegrity-211229094342-thumbnail.jpg?width=640&height=640&fit=bounds)
![[読会]P qk means-_ billion-scale clustering for product-quantized codes](https://cdn.slidesharecdn.com/ss_thumbnails/pqk-meansbillion-scaleclusteringforproduct-quantizedcodes-211229095124-thumbnail.jpg?width=640&height=640&fit=bounds)







![【会社紹介資料】 株式会社カンゲンエージェント [ 11 月 30 日作成資料公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/11-251211095054-61b5c9e6-thumbnail.jpg?width=640&height=640&fit=bounds)

