Downloaded 20 times
![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
≈ LEAVE A COMMENT
[]
Tags
leveragebigdata
—
Elastic Search integration with Hadoop
28 Saturday Jun 2014
POSTED BY LEVERAGEBIGDATA IN UNCATEGORIZED
Elastic Search, Hadoop, Hive, MapReduce
Elastic is open source distributed search engine, based on lucene framework with Rest API. You
can download the elastic search using the URL
http://www.elasticsearch.org/overview/elkdownloads/. Unzip the downloaded zip or tar file and
then start one instance or node of elastic search by running the script ‘elasticsearch-
1.2.1/bin/elasticsearch’ as shown below:
Installing plugin:
We can install plugins for enhance feature like elasticsearch-head provide the web interface to
interact with its cluster. Use the command ‘elasticsearch-1.2.1/bin/plugin -install
mobz/elasticsearch-head’ as shown below:
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 1/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/85/Elastic-search-integration-with-hadoop-leveragebigdata-1-320.jpg)
![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
≈ LEAVE A COMMENT
[]
Tags
leveragebigdata
—
Elastic Search integration with Hadoop
28 Saturday Jun 2014
POSTED BY LEVERAGEBIGDATA IN UNCATEGORIZED
Elastic Search, Hadoop, Hive, MapReduce
Elastic is open source distributed search engine, based on lucene framework with Rest API. You
can download the elastic search using the URL
http://www.elasticsearch.org/overview/elkdownloads/. Unzip the downloaded zip or tar file and
then start one instance or node of elastic search by running the script ‘elasticsearch-
1.2.1/bin/elasticsearch’ as shown below:
Installing plugin:
We can install plugins for enhance feature like elasticsearch-head provide the web interface to
interact with its cluster. Use the command ‘elasticsearch-1.2.1/bin/plugin -install
mobz/elasticsearch-head’ as shown below:
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 1/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/75/Elastic-search-integration-with-hadoop-leveragebigdata-1-2048.jpg)


![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
Integrating with Map Reduce (Hadoop 1.2.1)
To integrate Elastic Search with Map Reduce follow the below steps:
Add a dependency to pom.xml:
123456789
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>2.0.0</version>
</dependency>
or Download and add elasticSearch-hadoop.jar file to classpath.
Elastic Search as source & HDFS as sink:
In Map Reduce job, you specify the index/index type of search engine from where you need to
fetch data in hdfs file system. And input format type as ‘EsInputFormat’ (This format type is
defined in elasticsearch-hadoop jar). In org.apache.hadoop.conf.Configuration set elastic search
index type using field ‘es.resource’ and any search query using field ‘es.query’ and also set
InputFormatClass as ‘EsInputFormat’ as shown below:
ElasticSourceHadoopSinkJob.java
123456789
10
11
12
13
14
15
16
17
18
19
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.elasticsearch.hadoop.mr.EsInputFormat;
public class ElasticSourceHadoopSinkJob {
public static void main(String arg[]) throws IOException, ClassNotFoundException, Configuration conf = new Configuration();
conf.set("es.resource", "movies/movie");
//conf.set("es.query", "?q=kill");
final Job job = new Job(conf,
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 4/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/85/Elastic-search-integration-with-hadoop-leveragebigdata-4-320.jpg)
![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
"Get information from elasticSearch.");
job.setJarByClass(ElasticSourceHadoopSinkJob.class);
job.setMapperClass(ElasticSourceHadoopSinkMapper.class);
job.setInputFormatClass(EsInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MapWritable.class);
FileOutputFormat.setOutputPath(job, new Path(arg[0]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
ElasticSourceHadoopSinkMapper.java
123456789
10
11
12
13
14
15
import java.io.IOException;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ElasticSourceHadoopSinkMapper extends Mapper<Object, MapWritable, @Override
protected void map(Object key, MapWritable value,
Context context)
throws IOException, InterruptedException {
context.write(new Text(key.toString()), value);
}
}
HDFS as source & Elastic Search as sink:
In Map Reduce job, specify the index/index type of search engine from where you need to load
data from hdfs file system. And input format type as ‘EsOutputFormat’ (This format type is
defined in elasticsearch-hadoop jar). ElasticSinkHadoopSourceJob.java
123456789 10
11
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.elasticsearch.hadoop.mr.EsOutputFormat;
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 5/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/85/Elastic-search-integration-with-hadoop-leveragebigdata-5-320.jpg)
![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class ElasticSinkHadoopSourceJob {
public static void main(String str[]) throws IOException, ClassNotFoundException, Configuration conf = new Configuration();
conf.set("es.resource", "movies/movie");
final Job job = new Job(conf,
"Get information from elasticSearch.");
job.setJarByClass(ElasticSinkHadoopSourceJob.class);
job.setMapperClass(ElasticSinkHadoopSourceMapper.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(EsOutputFormat.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(MapWritable.class);
FileInputFormat.setInputPaths(job, new Path("data/ElasticSearchData"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
ElasticSinkHadoopSourceMapper.java
123456789
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.io.IOException;
import org.apache.hadoop.io.ArrayWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.MapWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ElasticSinkHadoopSourceMapper extends Mapper<LongWritable, Text, @Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] splitValue=value.toString().split(",");
MapWritable doc = new MapWritable();
doc.put(new Text("year"), new IntWritable(Integer.parseInt(splitValue[0])));
doc.put(new Text("title"), new Text(splitValue[1]));
doc.put(new Text("director"), new Text(splitValue[2]));
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 6/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/85/Elastic-search-integration-with-hadoop-leveragebigdata-6-320.jpg)
![11/23/2014 Elastic Search integration with Hadoop | leveragebigdata
24
25
26
27
28
29
30
31
32
33
String genres=splitValue[3];
if(genres!=null){
String[] splitGenres=genres.split("$");
ArrayWritable genresList=new ArrayWritable(splitGenres);
doc.put(new Text("genres"), genresList);
}
context.write(NullWritable.get(), doc);
}
}
Integrate with Hive:
Download elasticsearch-hadoop.jar file and include it in path using hive.aux.jars.path as shown
below: bin/hive –hiveconf hive.aux.jars.path=<path-of-jar>/elasticsearch-hadoop-2.0.0.jar or ADD
elasticsearch-hadoop-2.0.0.jar to <hive-home>/lib and <hadoop-home>/lib
Elastic Search as source & Hive as sink:
Now, create external table to load data from Elastic search as shown below:
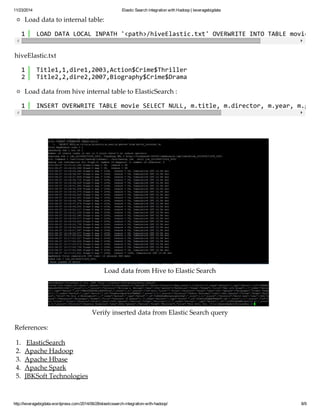
1 CREATE EXTERNAL TABLE movie (id BIGINT, title STRING, director STRING, year BIGINT, 1 CREATE TABLE movie_internal (title STRING, id BIGINT, director STRING, year BIGINT, You need to specify the elastic search index type using ‘es.resource’ and can specify query using
‘es.query’.
Load data from Elastic Search to Hive
Elastic Search as sink & Hive as source:
Create an internal table in hive like ‘movie_internal’ and load data to it. Then load data from
internal table to elastic search as shown below:
Create internal table:
http://leveragebigdata.wordpress.com/2014/06/28/elasticsearch-integration-with-hadoop/ 7/9](https://image.slidesharecdn.com/elasticsearchintegrationwithhadoopleveragebigdata-141123021714-conversion-gate01/85/Elastic-search-integration-with-hadoop-leveragebigdata-7-320.jpg)


Elasticsearch can be integrated with Hadoop and Hive to enable searching structured data stored in these frameworks. Elasticsearch indexes can be populated from Hadoop using MapReduce jobs where Elasticsearch is the output format, or data can be extracted from Elasticsearch to Hadoop. Similarly for Hive, external tables can be defined pointing to Elasticsearch indexes as the data source, or data can be loaded from Hive tables to Elasticsearch indexes. The document provides code examples for performing these types of Extract, Transform, Load operations between Elasticsearch, Hadoop and Hive.
























![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































