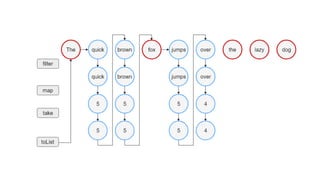
官網 Iterable 範例
—
valwords = "The quick brown fox jumps over the lazy dog"
.split(" ")
val lengthsList =
words.filter {
it.length > 3
}.map {
it.length
}.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)
19.
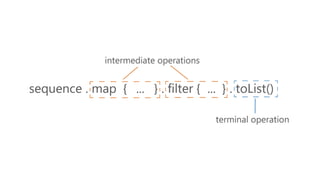
官網 Sequence 範例
—
valwords = "The quick brown fox jumps over the lazy dog"
.split(" ")
val wordsSequence = words.asSequence()
val lengthsSequence =
wordsSequence.filter {
it.length > 3
}.map {
it.length
}.take(4)
println("Lengths of first 4 words longer than 3 chars")
println(lengthsSequence.toList())
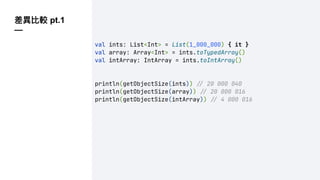
差異比較 pt.1
—
val ints:List<Int> = List(1_000_000) { it }
val array: Array<Int> = ints.toTypedArray()
val intArray: IntArray = ints.toIntArray()
println(getObjectSize(ints)) !" 20 000 040
println(getObjectSize(array)) !" 20 000 016
println(getObjectSize(intArray)) !" 4 000 016
60.
差異比較 pt.2
—
open classPrimitiveArrayBenchmark {
lateinit var list: List<Int>
lateinit var array: IntArray
@Setup
fun init() {
list = List(1_000_000) { it }
array = IntArray (1_000_000) { it }
}
@Benchmark
!" On average 1 260 593 ns
fun averageOnIntList(): Double {
return list.average()
}
@Benchmark
!" On average 868 509 ns
fun averageOnIntArray(): Double {
return array.average()
}
}
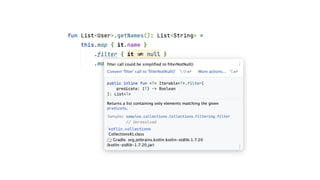
底層實作
—
public operator fun<T> Iterable<T>.plus(
elements: Array<out T>
): List<T> {
if (this is Collection) return this.plus(elements)
val result = ArrayList<T>()
result.addAll(this)
result.addAll(elements)
return result
}




















![產⽣ Sequence
opt.2
—
val fibonacci: Sequence<BigDecimal> = sequence {
var current = 1.toBigDecimal()
var prev = 1.toBigDecimal()
yield(prev)
while (true) {
yield(current)
val temp = prev
prev = current
current += temp
}
}
print(fibonacci.take(10).toList())
!" Prints: [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]](https://image.slidesharecdn.com/effective-kotlin-chapter8-221208155318-f914a841/85/Effective-Kotlin-Efficient-collection-processing-23-320.jpg)











![⽤ Map 實作
—
class InMemoryUserRepoWithMap : UserRepo {
private val users: MutableMap<Int, User> = mutableMapOf()
override fun getUser(id: Int): User? = users[id]
fun addUser(user: User) {
users[user.id] = user
}
}](https://image.slidesharecdn.com/effective-kotlin-chapter8-221208155318-f914a841/85/Effective-Kotlin-Efficient-collection-processing-35-320.jpg)

![再從 Map 轉回 List
—
val originalList = byId.values
println(originalList)
!" [ User(id=1, name=Michal),
!" User(id=2, name=Mark),
!" User(id=3, name=Mark) ]](https://image.slidesharecdn.com/effective-kotlin-chapter8-221208155318-f914a841/85/Effective-Kotlin-Efficient-collection-processing-37-320.jpg)
![實務範例 pt.1
—
class ConfigurationsRepository(
configurations: List<Configuration>,
) {
private val configurations: Map<String, Configuration> =
configurations.associateBy { it.name }
fun getByName(name: String) = configurations[name]
}](https://image.slidesharecdn.com/effective-kotlin-chapter8-221208155318-f914a841/85/Effective-Kotlin-Efficient-collection-processing-38-320.jpg)


































![[JCConf 2023] 從 Kotlin Multiplatform 到 Compose Multiplatform:在多平台間輕鬆共用業務邏輯與 U...](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-multiplatform-with-compose-231011174559-d4d22a45-thumbnail.jpg?width=640&height=640&fit=bounds)








![[GDG Kaohsiung DevFest 2023] 以 Compose 及 Kotlin Multiplatform 打造多平台應用程式](https://cdn.slidesharecdn.com/ss_thumbnails/building-multiplaftorm-application-using-kotlin-and-compose-multiplatform-231127165717-6bee7d0b-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[COSCUP 2022] Kotlin Collection 遊樂園](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-collection-playground-220803082529-17e4a226-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[JCConf 2024] Kotlin/Wasm:為 Kotlin 多平台帶來更多可能性](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-wasm-the-new-target-in-kmp-241004034547-e11ec4a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kotlin 讀書會第五梯次] 深入淺出 Kotlin 第一章導讀](https://cdn.slidesharecdn.com/ss_thumbnails/guided-reading-on-head-first-kotlin-chapter-one-230816095202-c328f541-thumbnail.jpg?width=640&height=640&fit=bounds)
![[WebConf Taiwan 2023] 一份 Zend Engine 外帶!透過 Micro 讓一次打包、多處運行變得可能](https://cdn.slidesharecdn.com/ss_thumbnails/building-app-with-zend-engine-using-micro-230816092930-84eda384-thumbnail.jpg?width=640&height=640&fit=bounds)

![[MOPCON 2022] 以 Kotlin Multiplatform 制霸全平台](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-multiplatform-221017125206-52db0fac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JCConf 2022] Compose for Desktop - 開發桌面軟體的新選擇](https://cdn.slidesharecdn.com/ss_thumbnails/compose-for-desktop-221008111948-4f59ebda-thumbnail.jpg?width=640&height=640&fit=bounds)

![[COSCUP 2022] 讓黑畫面再次偉大 - 用 PHP 寫 CLI 工具](https://cdn.slidesharecdn.com/ss_thumbnails/make-cli-great-again-by-using-php-220803083302-2be4b800-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PHP 也有 Day #64] PHP 升級指南](https://cdn.slidesharecdn.com/ss_thumbnails/php-upgrade-guide-220301051052-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Kotlin Serverless 工作坊] 單元 4 - 實作 RSS Aggregator](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-serverless-ep4-rss-aggregator-210423105251-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kotlin Serverless 工作坊] 單元 3 - 實作 JSON API](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-serverless-ep3-json-handling-210423105249-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kotlin Serverless 工作坊] 單元 2 - 簡介 Kotlin Serverless](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-serverless-ep2-introduce-cloud-functions-210423105247-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Kotlin Serverless 工作坊] 單元 1 - 開發環境建置](https://cdn.slidesharecdn.com/ss_thumbnails/kotlin-serverless-ep1-dev-env-210423105244-thumbnail.jpg?width=640&height=640&fit=bounds)
