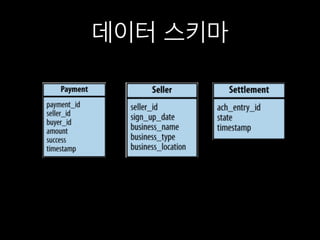
표본의 문제
전통적인 데이터수집 방법
표본을 가지고 의미 있는 데이터를 찾음(e.g. 평균)
현대의 방법
모든 데이터로 작업이 가능
“전체는 일시적인 시각화에 불과하다.”
4.
– Bruno Latour
“도구를바꿔라, 그러면 여러분은 그것과 함께 하는 사
회 이론을 통째로 바꿀 수 있다.”
과거의 방식에 집착하지 마라
5.
도메인 지식의 중요성
기술은어떤 학문분과의 자연적 필요에서 발생
지리정보시스템 -> 지리학자
텍스트 데이터 마이닝 -> 디지털 인문학
세상을 지배하는 것은 수학자가 아니라 그 분야의 전문가
“데이터과학의 언어는 수학으로 하는 무언가를 가지고 있
듯이 사회과학으로 하는 무언가도 가지고 있다.”
도메인주도개발??
6.
Processing
예술가와 디자이너를 위한프로그래밍 언어
그 분야의 전문가들의 언어로 이야기해야 한다.
“좋은 언어란 그 언어를 사용하는 사람들의 사고방식을 반영하고 있으며, 또한
그들이 하고자 했던 표현이 가능하도록 설계되거나 구조화 되어있다.”
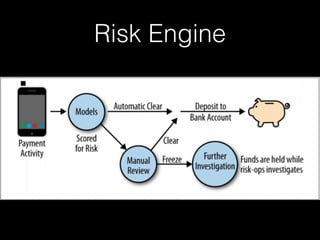
어떻게 분류명을 붙일까
지도학습 문제? K-근접 이웃?
최초 트랜잭션 이후 하루에 걸쳐 처리
초기에 거절되었으나 추후에 승인
처음엔 승인되었으나 추가 검토후 악성으로 판명
계속 악성이었던 경우
계속 정상 거래였던 경우
준 지도 학습 문제
21.
성능 척도의 정의
전체거래수에 비교해 사기는 희박
따라서 ‘모두 사기다’ 혹은 ‘모두 정상거래다’ 라는 모델의 정확도가 높음
실제로 사실 실제로 거짓
사실이라고 예측 TP(true, positive) FP(false, positive)
거짓이라고 예측 FN(false, negative) TN(true, negative)
정확도 =
TP + TN
TP + TN + FP + FN
가장 간단한 성능 척도 모델
22.
더 나은 오차측정
정밀도 =
TP
TP + FP
재현율 =
TP
TP + FN
사기라고 판단한 것중
실제 사기
모형의 정확성
전체 사기(맞춘것 + 안맞춘것) 중
실제 사기
진짜 사기가 모형에서 잡힐 확률
23.
분류명 정의
의심스러운 활동이란뭘까?
이걸 어떻게 정의하나?
열정적 사용자를 어떻게 정의하나?
분류명의 정의에 따라 전혀 다른 결과가 도출
24.
특징과 학습에서의 도전
하나의특징을 학습하는데 필요한 표본의 크기는 관심대상
모집단에 비례
신규 판매자의 첫 시작 문제
새로운 사용자에 대한 데이터가 없을 때
문제 상황에 맞추어 알고리즘 조정
적대적 행동 인지
25.
모형 구축에 관한조언
모형은 블랙박스가 아니다
알고리즘이 어떻게 동작하는지 알것!
모형 반복을 빠르게 수행할 것
여러가지 가정을 다양하게 시도해보아야 함.
모형과 패키지가 만병통치약이 아니다
상황에따라 같은 모형도 다르게 적용되는것
26.
코드 생산의 조언
코드의가독성과 재사용 가능성
짝 프로그래밍
실제 환경은 개발환경보다 엄격하다
시간과 공간상의 가용성 제약.
특징연산으로 축소
전체 데이터중 중요한 의미를 갖는것
데이터는 중복된 것들이 많다. 그것들을 모형에 다 넣을 필요가 없다
27.
스퀘어의 데이터 시각화활용
효율적인 트랜잭션 검토
의심스러운 행동을 검토하는 팀에서 시각화된 데이터 활용으로 더 효율적인 예측 모델 구축 가능
개별 고객의 패턴과 고객 집단 사이의 패턴 탐구
집단간의 추세와 패턴을 찾음
사업 건전성 측정
투명한 비즈니스 지표 제공: 등록, 활성화, 활동적 사용자.
주변 분석 제공
어떠한 행위가 비정상행위인지 도출 가능
































![[214] data science with apache zeppelin](https://cdn.slidesharecdn.com/ss_thumbnails/241datasciencewithapachezeppelin-150915001420-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










![[울산과학고 SW/STEAM] 1주차 - 데이터 시각화 방법론 및 사례](https://cdn.slidesharecdn.com/ss_thumbnails/week1small-200708043647-thumbnail.jpg?width=640&height=640&fit=bounds)






![[도서 리뷰] 헤드 퍼스트 데이터 분석 ( Head First Data Analysis )](https://cdn.slidesharecdn.com/ss_thumbnails/headfirstdataanalysis-181125114351-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2A7]Linkedin'sDataScienceWhyIsItScience](https://cdn.slidesharecdn.com/ss_thumbnails/2a7linkedinsdatasciencewhyisitscience-140930023218-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









