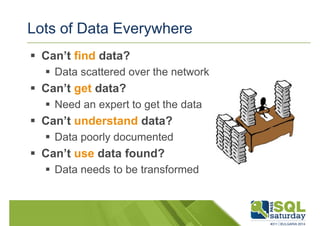
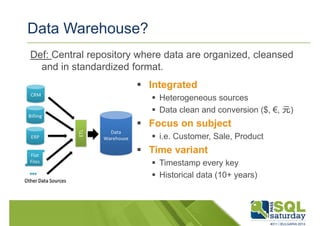
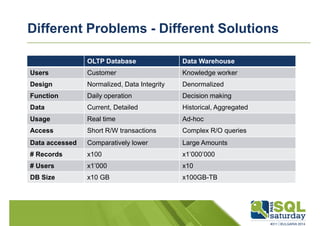
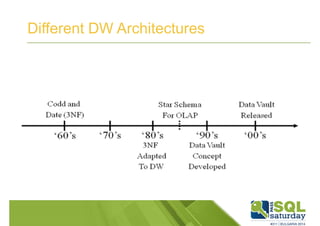
Downloaded 1,523 times





















![Multinational DW
What parts need translation?
Where to store various language versions?
How to support future languages?
Dimensions
Add language attribute
Include text data in the dimension
Problem 1: The dimension key?
Replicate PK for every language
Fact.DimId = Dim.Id AND Dim.Lang=[Lang]
Problem 2: Storage = [Dim] x [Lang]
Sub-dimension with language attributes
TxtId Attr1 Attr2 LangId
1 large Yes En
2 small No En
1 stor Ja No
2 liten Nei No
3 … … …](https://image.slidesharecdn.com/datawarehousedesignandbestpractices-141013091119-conversion-gate01/85/Data-Warehouse-Design-and-Best-Practices-28-320.jpg)


![Partitioning
Why
Faster index maintenance
Faster load
Faster queries
When
Tables 10GB+
How
Do not partition dimension tables
Partition by date (most analysis are time-based)
Eliminate partitions (WHERE [PartitionKey]=…)
Avoid split and merge of existing partitions
Can cause inefficient log generation](https://image.slidesharecdn.com/datawarehousedesignandbestpractices-141013091119-conversion-gate01/85/Data-Warehouse-Design-and-Best-Practices-31-320.jpg)

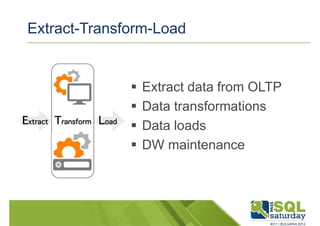






The document outlines best practices for data warehouse design, discussing various architectures like Inmon and Kimball models, as well as key concepts such as dimensional modeling, ETL processes, and data maintenance strategies. It emphasizes the importance of data quality, integrity, and effective design patterns for ensuring efficient data management and retrieval. The document also includes practical considerations and pitfalls to avoid in data warehousing to achieve successful business intelligence outcomes.























































































