Downloaded 1,261 times
![Introduction to Data Mining Ch. 2 Data Preprocessing Heon Gyu Lee ( [email_address] ) http://dblab.chungbuk.ac.kr/~hglee DB/Bioinfo., Lab. http://dblab.chungbuk.ac.kr Chungbuk National University](https://image.slidesharecdn.com/ch-2-datapreprocessing-090808113508-phpapp01/85/Data-Preprocessing-1-320.jpg)


















![Data Transformation : Normalization Min-max normalization: to [new_min A , new_max A ] Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0]. Then $73,000 is mapped to Z-score normalization ( μ : mean, σ : standard deviation): Ex. Let μ = 54,000, σ = 16,000. Then Normalization by decimal scaling Where j is the smallest integer such that Max(| ν ’ |) < 1](https://image.slidesharecdn.com/ch-2-datapreprocessing-090808113508-phpapp01/85/Data-Preprocessing-25-320.jpg)


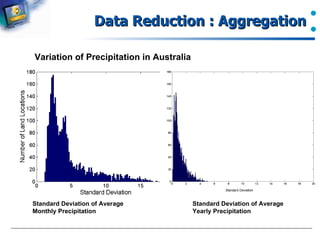



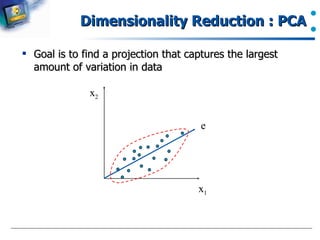
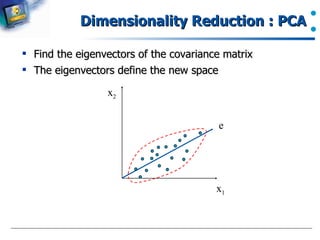



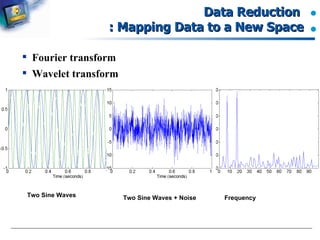
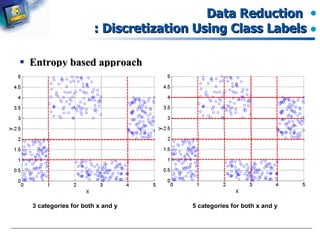
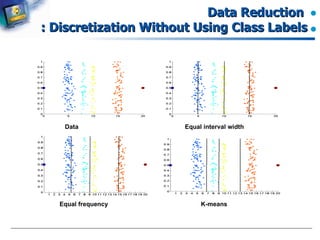
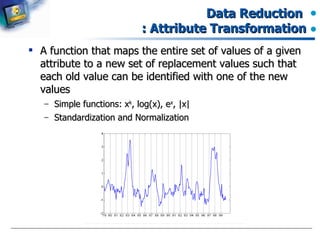


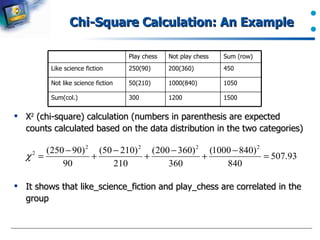
The document introduces data preprocessing techniques for data mining. It discusses why data preprocessing is important due to real-world data often being dirty, incomplete, noisy, inconsistent or duplicate. It then describes common data types and quality issues like missing values, noise, outliers and duplicates. The major tasks of data preprocessing are outlined as data cleaning, integration, transformation and reduction. Specific techniques for handling missing values, noise, outliers and duplicates are also summarized.












































































