Downloaded 701 times







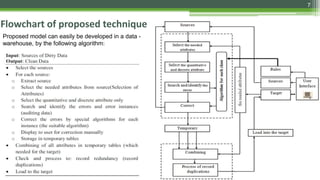

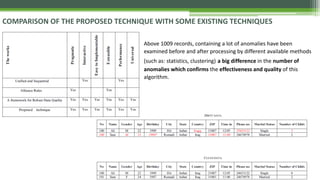


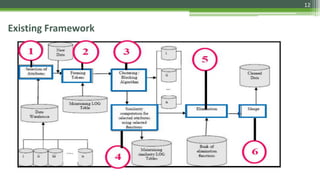

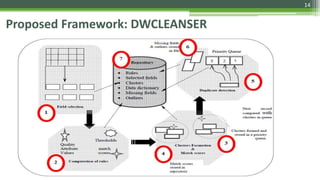




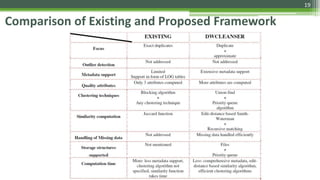






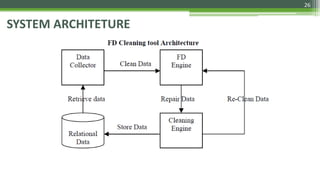






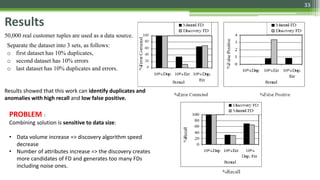





The document discusses various data cleaning techniques essential for ensuring data quality in information systems, highlighting methods such as DWcleanser for detecting approximate duplicates and employing data quality mining with association rules and functional dependencies. An enhanced algorithm for cleaning data warehouses is presented, focusing on accuracy and efficiency in correcting errors, as well as a systematic approach for managing metadata and outlier records. The frameworks and techniques described aim to address common data quality issues while minimizing processing time and improving overall data integrity.

















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















