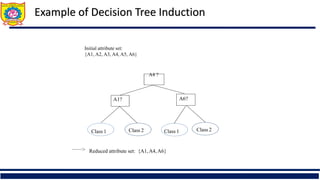
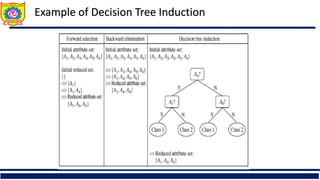
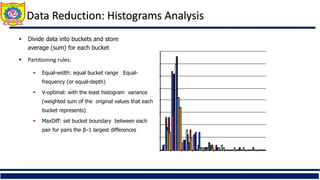
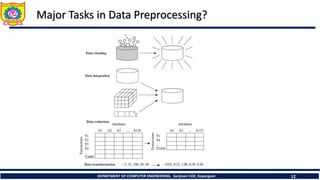
The document is an educational material from Sanjivani College of Engineering discussing data preprocessing techniques in data mining, emphasizing the importance of data quality. It outlines methods for data cleaning, integration, reduction, and transformation to address issues like missing values, noise, and inconsistencies that hinder effective data analysis. Additionally, it highlights the significance of preprocessing in achieving accurate and reliable mining results.




















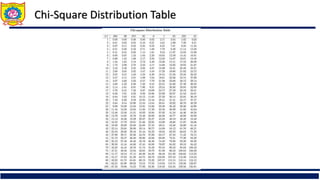



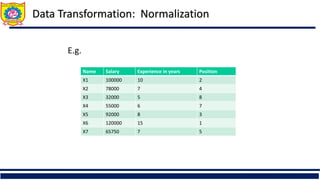
![Data Transformation: Normalization
Then $73,000 is mapped to
98,00012,000
(new_ maxA new_ minA) new_ minA
v'
A
– Ex. Let μ = 54,000, σ = 16,000. Then
• Normalization by decimal scaling
v' Where j is the smallest integer such that Max(|ν’|) < 1
16,000
Min-max normalization: to [new_minA, new_maxA]
Ex. Let income range $12,000 to $98,000 normalized to [0.0, 1.0]. Then $73,000 is
mapped to
Z-score normalization (μ: mean, σ: standard deviation):
Ex. Let μ = 54,000, σ = 16,000. Then
Normalization by decimal scaling
A
A
A
A
A
A
min
new
min
new
max
new
min
max
min
v
v _
)
_
_
(
'
A
A
v
v
'
j
v
v
10
' Where j is the smallest integer such that Max(|ν’|) < 1
716
.
0
0
)
0
0
.
1
(
000
,
12
000
,
98
000
,
12
600
,
73
225
.
1
000
,
16
000
,
54
600
,
73
](https://image.slidesharecdn.com/unit2-240425043617-54490292/85/Data-Preparation-and-Preprocessing-Data-Cleaning-29-320.jpg)