Data Contamination –What is it?
LLMs may have already seen the test data during training.
6/20/25 4
Train Test
5.
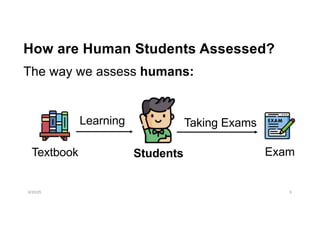
How are HumanStudents Assessed?
The way we assess humans:
6/20/25 5
Students
Textbook Exam
Learning Taking Exams
6.
How are LLMsAssessed?
The way we assess AIs:
6/20/25 6
LLMs
Textbook
Learning Taking Exams
Exam
7.
Challenges
• Training corporais huge
• Pretraining corpora surpasses 774.5 TB !
• Data contamination could be indirectly introduced
• Github, GitLab
• Blogs, forums
• Social media feeds
6/20/25 7
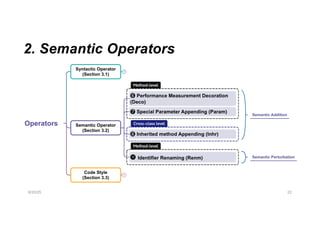
8.
Solution 1 –Collect new data
• Collect new data uploaded after LLMs’ cut-off date
6/20/25 8
2020 2021 2022 2023 2024 2025
9.
Solution 1 –Collect new data
• Collect new data uploaded after LLMs’ cut-off date
6/20/25 9
2020 2021 2022 2023 2024 2025
🤷
No more new?
10.
Solution 2 –Refactor old data
• Code refactoring
6/20/25 10
11.
Solution 2 –Refactor old data
• Challenges of Code refactoring
6/20/25 11
• Perturb code while keeping its
syntactic, semantic, and logic
requirements
• Using LLMs to refactor the
code will reintroduce data
contamination
12.
Is Code RefactoringReally Effective?
6/20/25 12
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
(A) Code from Scikit-Learn
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
(B) Code After Changing Naming Style
Overlap:
40.98%
Overlap:
20.78%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
• Take this piece of code as an example
DataPortraits: https://dataportraits.org/
Overlap with the
Stack-v1 (6TB
Code Data)
40.98%
13.
Is Code RefactoringReally Effective?
6/20/25 13
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
(A) Code from Scikit-Learn
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
(B) Code After Changing Naming Style
Overlap:
40.98%
Overlap:
20.78%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(B) Code After Changing Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
40.98%
Overlap:
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
Change Naming Style
• Overlap ratio with training data: 40.98% à 20.78%
14.
Is Code RefactorReally Effective?
• Overlap ratio with training data: 20.78% à 0%
6/20/25 14
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if not (v is None or v == '' or v != v):
s = encode_string(str(v))
else:
s = '?'
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(B) Code After Changing Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
40.98%
Overlap:
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
Flip if-else branch
Syntactic Operators –If-condition Flipping
6/20/25 17
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if not (len(row) > 0 and max(row) >= num_attributes):
pass
else:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
After Flipping If-else Branches
1
2
3
4
5
6
7
8
9
10
11
Before
After
18.
Syntactic Operators –If-condition Flipping
6/20/25 18
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if not (len(row) > 0 and max(row) >= num_attributes):
pass
else:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
After Flipping If-else Branches
1
2
3
4
5
6
7
8
9
10
11
Before
After
19.
Syntactic Operators –Loop transformation
6/20/25 19
Before
After
def decode_rows(self, stream, conversors):
for row in stream:
values = _parse_values(row)
(A) Original Code
1
2
3
def decode_rows(self, stream, conversors):
_iter2 = iter(stream)
while True:
try:
row = next(_iter2)
except StopIteration:
break
values = _parse_values(row)
(B) Code After Loop Transformation (for → while)
1
2
3
4
5
6
7
8
Loop Transformation
20.
Syntactic Operators –Iter transformation
6/20/25 20
Before
After
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(A) Original Code
Iteration Transformation
1
2
3
4
5
6
7
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in range(len(data)):
new_data = []
if len(data[row]) > 0 and max(data[row]) >= num_attributes:
...
(B) Code After Iteration Transformation (direct iteration → index iteration)
1
2
3
4
5
6
7
21.
Syntactic Operators –Commutative Law
Shuffling
6/20/25 21
Before
After
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
(A) Original Code
1
2
3
4
5
6
for col in sorted(row):
v = row[col]
if v == '' or v != v or v is None:
s = '?'
else:
s = encode_string(str(v))
(B) Code After Applying Commutative Law in Logic Operators
1
2
3
4
5
6
Commutative Law
Semantic Operators –Special Parameter
Appending
6/20/25 23
Before
After
def decode_rows(self, stream, conversors):
for row in stream:
values = _parse_values(row)
if not isinstance(values, dict):
raise BadLayout()
(A) Original Code
Appending special parameters
1
2
3
4
5
def decode_rows(self, stream, conversors, *args, **kwargs):
for row in stream:
values = _parse_values(row)
if not isinstance(values, dict):
raise BadLayout()
(B) Code After Appending Special Parameters
1
2
3
4
5
24.
Semantic Operators –Identifier Renaming
6/20/25 24
Before
After
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(A) Original Code
1
2
3
4
5
6
7
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
advanced_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(B) Code After Renaming an Identifier
1
2
3
4
5
6
7
Identifier Renaming
Code Style Operators- Code Normalization
6/20/25 26
Before
After
def __setattr__(self, key: str, val: Any) -> None:
prefix = object.__getattribute__(self, "prefix")
if prefix:
prefix += "."
prefix += key
if key in self.d and not isinstance(self.d[key], dict):
_set_option(prefix, val)
else:
raise OptionError("You can only set the value of existing options")
(A) Original Code
Code Normalization
1
2
3
4
5
6
7
8
9
def __setattr__(self, key: str, val: Any) -> None:
prefix = object.__getattribute__(self, 'prefix')
if prefix:
prefix += '.'
prefix += key
if key in self.d and (not isinstance(self.d[key], dict)):
_set_option(prefix, val)
else:
raise OptionError('You can only set the value of existing options')
(B) Code After Normalization
1
2
3
4
5
6
7
8
9










![Is Code Refactoring Really Effective?
6/20/25 12
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
(A) Code from Scikit-Learn
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
(B) Code After Changing Naming Style
Overlap:
40.98%
Overlap:
20.78%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
• Take this piece of code as an example
DataPortraits: https://dataportraits.org/
Overlap with the
Stack-v1 (6TB
Code Data)
40.98%](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-12-320.jpg)
![Is Code Refactoring Really Effective?
6/20/25 13
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
(A) Code from Scikit-Learn
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
(B) Code After Changing Naming Style
Overlap:
40.98%
Overlap:
20.78%
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(B) Code After Changing Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
40.98%
Overlap:
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
Change Naming Style
• Overlap ratio with training data: 40.98% à 20.78%](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-13-320.jpg)
![Is Code Refactor Really Effective?
• Overlap ratio with training data: 20.78% à 0%
6/20/25 14
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if not (v is None or v == '' or v != v):
s = encode_string(str(v))
else:
s = '?'
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
new_data.append('%d %s' % (col, s))
current_row += 1
yield ' '.join(['{', ','.join(new_data), '}'])
Change Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= numAttributes:
raise BadObject('Instance %d has %d attributes,
expected %d' % (currentRow,
max(row) + 1, numAttributes))
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
newData.append('%d %s' % (col, s))
currentRow += 1
yield ' '.join(['{', ','.join(newData), '}'])
(B) Code After Changing Naming Style
def encode_data(self, data, attributes):
currentRow = 0
numAttributes = len(attributes)
for row in data:
newData = []
if len(row) > 0 and max(row) >= num_attributes:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
(C) Code after Changing Naming Style + Flipping If-else Branch
If-else branch switch
40.98%
Overlap:
20.78%
Overlap:
0.0%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1
2
3
4
5
6
7
8
9
Flip if-else branch](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-14-320.jpg)


![Syntactic Operators – If-condition Flipping
6/20/25 17
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if not (len(row) > 0 and max(row) >= num_attributes):
pass
else:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
After Flipping If-else Branches
1
2
3
4
5
6
7
8
9
10
11
Before
After](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-17-320.jpg)
![Syntactic Operators – If-condition Flipping
6/20/25 18
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if not (len(row) > 0 and max(row) >= num_attributes):
pass
else:
raise BadObject(‘Instance %d has %d attributes,
expected %d’ % (current_row,
max(row) + 1, num_attributes))
After Flipping If-else Branches
1
2
3
4
5
6
7
8
9
10
11
Before
After](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-18-320.jpg)

![Syntactic Operators – Iter transformation
6/20/25 20
Before
After
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(A) Original Code
Iteration Transformation
1
2
3
4
5
6
7
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in range(len(data)):
new_data = []
if len(data[row]) > 0 and max(data[row]) >= num_attributes:
...
(B) Code After Iteration Transformation (direct iteration → index iteration)
1
2
3
4
5
6
7](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-20-320.jpg)
![Syntactic Operators – Commutative Law
Shuffling
6/20/25 21
Before
After
for col in sorted(row):
v = row[col]
if v is None or v == '' or v != v:
s = '?'
else:
s = encode_string(str(v))
(A) Original Code
1
2
3
4
5
6
for col in sorted(row):
v = row[col]
if v == '' or v != v or v is None:
s = '?'
else:
s = encode_string(str(v))
(B) Code After Applying Commutative Law in Logic Operators
1
2
3
4
5
6
Commutative Law](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-21-320.jpg)

![Semantic Operators – Identifier Renaming
6/20/25 24
Before
After
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
new_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(A) Original Code
1
2
3
4
5
6
7
def encode_data(self, data, attributes):
current_row = 0
num_attributes = len(attributes)
for row in data:
advanced_data = []
if len(row) > 0 and max(row) >= num_attributes:
...
(B) Code After Renaming an Identifier
1
2
3
4
5
6
7
Identifier Renaming](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-24-320.jpg)

![Code Style Operators - Code Normalization
6/20/25 26
Before
After
def __setattr__(self, key: str, val: Any) -> None:
prefix = object.__getattribute__(self, "prefix")
if prefix:
prefix += "."
prefix += key
if key in self.d and not isinstance(self.d[key], dict):
_set_option(prefix, val)
else:
raise OptionError("You can only set the value of existing options")
(A) Original Code
Code Normalization
1
2
3
4
5
6
7
8
9
def __setattr__(self, key: str, val: Any) -> None:
prefix = object.__getattribute__(self, 'prefix')
if prefix:
prefix += '.'
prefix += key
if key in self.d and (not isinstance(self.d[key], dict)):
_set_option(prefix, val)
else:
raise OptionError('You can only set the value of existing options')
(B) Code After Normalization
1
2
3
4
5
6
7
8
9](https://image.slidesharecdn.com/codecleaner-jialuncao-0620-250620092803-57f4d896/85/CodeCleaner-Mitigating-Data-Contamination-for-LLM-Benchmarking-26-320.jpg)














































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)




