Download to read offline







































![Google BigQuery Tastiness
47
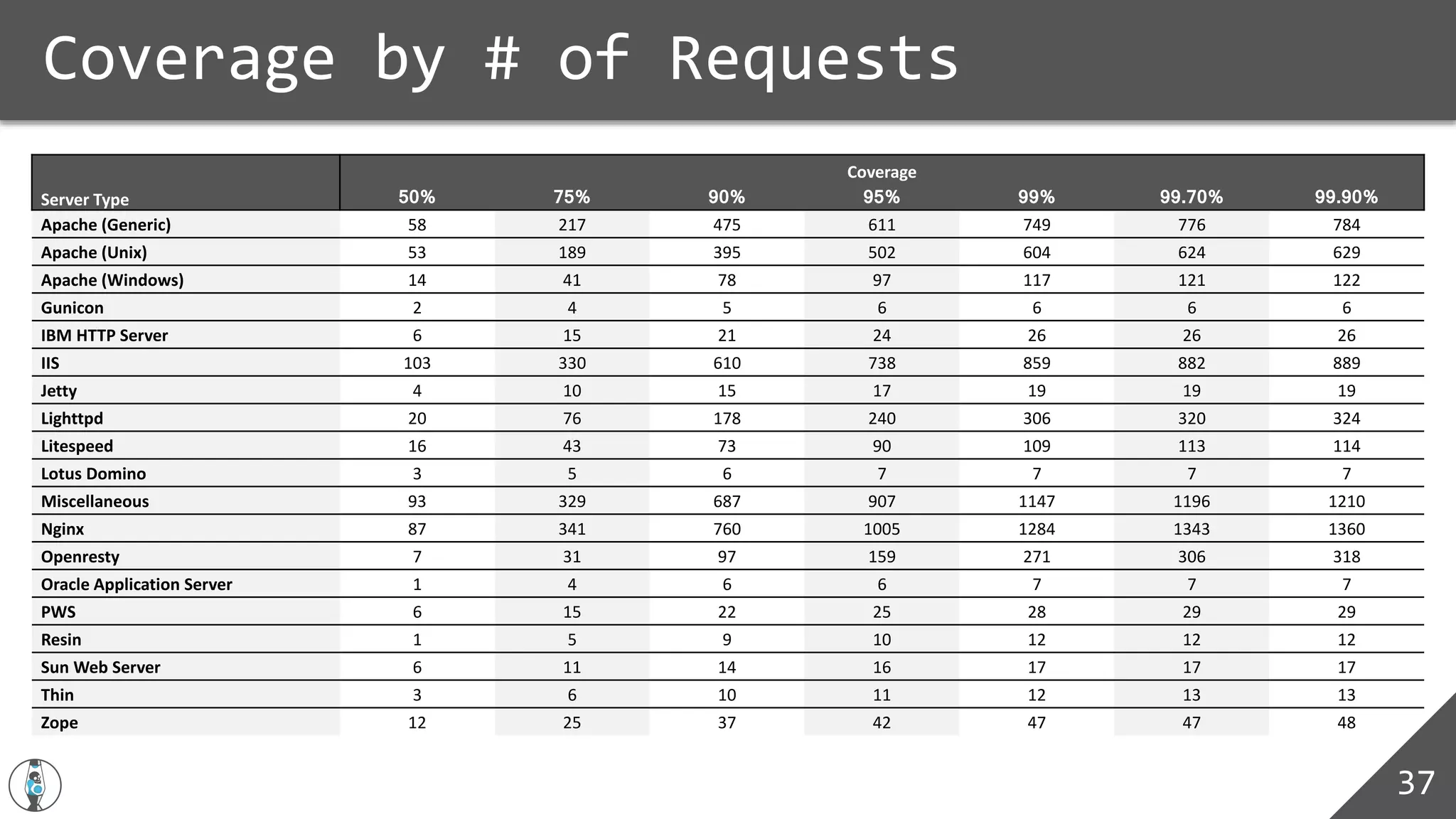
SELECT count(*)
FROM [bigquery-public-data:github_repos.files] as BQFILES
WHERE BQFILES.path LIKE '%server.pem' OR BQFILES.path like "%id_rsa"
OR BQFILES.path like "%id_dsa";
13,706
SELECT count(*)
FROM [bigquery-public-data:github_repos.files] as BQFILES
WHERE BQFILES.path LIKE '%.aws/credentials’;
42
SELECT count(*)
FROM [bigquery-public-data:github_repos.files] as BQFILES
WHERE BQFILES.path LIKE '%.keystore’;
14,558
SELECT count(*)
FROM [bigquery-public-data:github_repos.files] as BQFILES
WHERE BQFILES.path LIKE '%robots.txt’;
197,694](https://image.slidesharecdn.com/cloudstone06032017-170605215642/75/Cloudstone-Sharpening-Your-Weapons-Through-Big-Data-47-2048.jpg)




![THANK YOU!
@_lavalamp
chris [AT] websight [DOT] io
https://github.com/lavalamp-
https://l.avala.mp](https://image.slidesharecdn.com/cloudstone06032017-170605215642/75/Cloudstone-Sharpening-Your-Weapons-Through-Big-Data-52-2048.jpg)

The document discusses utilizing big data tools like MapReduce, Hadoop, and Amazon Elastic MapReduce (EMR) to enhance web application content discovery through mining data from the Common Crawl. It details the methodologies for processing large datasets, the extraction of meaningful URL paths, and the challenges faced in aggregating that data. The outcomes highlight potential improvements in identifying common vulnerabilities in web applications and insights into applying big data for penetration testing.










![Understanding and Deploying DNSSEC, by Champika Wijayatunga [APRICOT 2015]](https://cdn.slidesharecdn.com/ss_thumbnails/dnssec-final1425360815-150318234332-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)









