Download to read offline





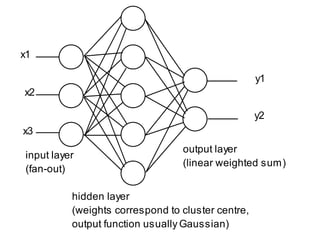




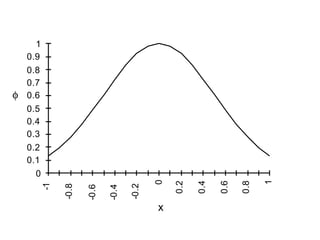





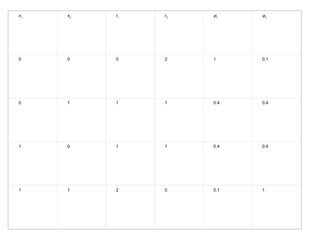

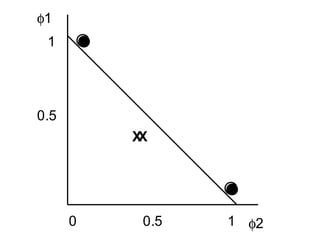















This document describes an expert system and solutions company that provides research projects and guidance to students. It is located in Paiyanoor, OMR, Chennai and provides research labs for students to assemble hardware projects. The company contacts are listed as expertsyssol@gmail.com, expertsyssol@yahoo.com, and 9952749533. Final year students in electrical engineering fields can work on projects related to power systems, applied electronics, and power electronics. Ph.D students in electrical and electronics fields are also welcome.





















































































