newtype Pair ba = Pair { getPair :: (a, b) }
-- パターンマッチを使ってPair型から中身のタプルを取り出し、
-- fをタプルの第一要素に適用し、
-- Pair値コンストラクタを使ってタプルをPair b a型に再変換
instance Functor (Pair c) where
fmap f (Pair (x, y)) = Pair (f x, y)
-- fmapの型(a -> b) -> f a -> f bは
-- Pair b a型の場合は
-- (a -> b) -> Pair c a -> Pair c b
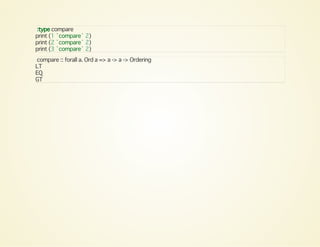
:type fmap
:type fmap (*100) Pair
print (getPair $ fmap (*100) (Pair (2, 3)))
print (getPair $ fmap reverse (Pair ("london calling", 3)))
fmap :: forall (f :: * -> *) a b. Functor f => (a -> b) -> f a -> f b
fmap (*100) Pair :: forall b a. Num (Pair b a) => (a, b) -> Pair b a
(200,3)
("gnillac nodnol",3)
-- Monoid型クラスの定義
-- (Data.Monoidモジュールにて定義されている)
--
--mは型クラスの関数定義中で型引数を取らないため
-- FunctorやApplicativeとは違って具体型となる
--
-- class Functor f where
-- fmap :: (a -> b) -> f a -> f b
--
class Monoid m where
mempty :: m
mappend :: m -> m -> m
mconcat :: [m] -> m
mconcat = foldr mappend mempty
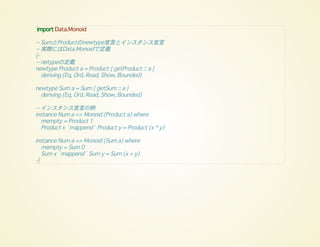
import Data.Monoid
-- SumとProductのnewtype宣言とインスタンス宣言
--実際にはData.Monoidで定義
{-
-- netypeの定義
newtype Product a = Product { getProduct :: a }
deriving (Eq, Ord, Read, Show, Bounded)
newtype Sum a = Sum { getSum :: a }
deriving (Eq, Ord, Read, Show, Bounded)
-- インスタンス宣言の例
instance Num a => Monoid (Product a) where
mempty = Product 1
Product x `mappend` Product y = Product (x * y)
instance Num a => Monoid (Sum a) where
mempty = Sum 0
Sum x `mappend` Sum y = Sum (x + y)
-}
import Data.Monoid
-- AnyとAllのnewtype宣言とインスタンス宣言
--実際にはData.Monoidで定義
{-
-- netypeの定義
newtype Any = Any { getAny :: Bool }
deriving (Eq, Ord, Read, Show, Bounded)
newtype All = All { getAll :: Bool }
deriving (Eq, Ord, Read, Show, Bounded)
-- インスタンス宣言の例
instance Monoid Any where
mempty = Any False
Any x `mappend` Any y = Any (x || y)
instance Monoid All where
mempty = All True
All x `mappend` All y = All (x && y)
-}
54.
-- 使ってみる
print "Anyexample"
print (getAny $ Any True `mappend` Any False)
print (getAny $ mempty `mappend` Any True)
print (getAny . mconcat . map Any $ [False, False, False, True])
print (getAny $ mempty `mappend` mempty)
print "All example"
print (getAll $ mempty `mappend` All True)
print (getAll $ mempty `mappend` All False)
print (getAll . mconcat . map All $ [True, True, True])
print (getAll . mconcat . map All $ [True, True, False])
{-
こんなふうに包んだり解いたりするのは面倒なので普通はandやorの関数と[Bool]を使う
-}
"Any example"
True
True
True
False
"All example"
True
False
True
False
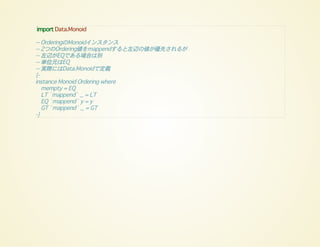
-- 長さの比較結果をa, 辞書順の比較結果をbとし、長さが等しければbを返す
lengthCompare:: String -> String -> Ordering
lengthCompare x y = let a = length x `compare` length y
b = x `compare` y
in if a == EQ then b else a
-- Orderingはモノイドであるという知識を使えばもっとシンプルに書ける
import Data.Monoid
lengthCompare :: String -> String -> Ordering
lengthCompare x y = (length x `compare` length y) `mappend` (x `compare` y)
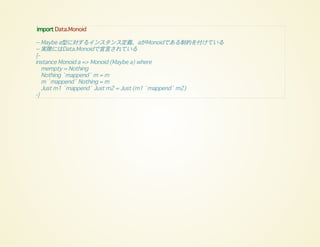
import Data.Monoid
-- Maybea型に対するインスタンス定義、aがMonoidである制約を付けている
-- 実際にはData.Monoidで宣言されている
{-
instance Monoid a => Monoid (Maybe a) where
mempty = Nothing
Nothing `mappend` m = m
m `mappend` Nothing = m
Just m1 `mappend` Just m2 = Just (m1 `mappend` m2)
-}
68.
-- 使ってみる
print (Nothing`mappend` Just "andy")
print (Just LT `mappend` Nothing)
print (Just (Sum 3) `mappend` Just (Sum 4))
Just "andy"
Just LT
Just (Sum {getSum = 7})
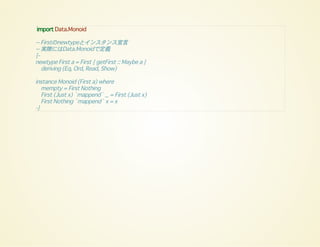
import Data.Monoid
-- Firstのnewtypeとインスタンス宣言
--実際にはData.Monoidで定義
{-
newtype First a = First { getFirst :: Maybe a }
deriving (Eq, Ord, Read, Show)
instance Monoid (First a) where
mempty = First Nothing
First (Just x) `mappend` _ = First (Just x)
First Nothing `mappend` x = x
-}
71.
-- 試す
print (getFirst$ First (Just 'a') `mappend` First (Just 'b'))
print (getFirst $ First Nothing `mappend` First (Just 'b'))
print (getFirst $ First (Just 'a') `mappend` First Nothing)
-- リストの中にJust値があるかも調べられる
print (getFirst . mconcat . map First $ [Nothing, Just 9, Just 10])
Just 'a'
Just 'b'
Just 'a'
Just 9
-- 反対の定義(第二引数優先)のLast a型もData.Monoidに存在
import Data.Monoid
print (getLast . mconcat . map Last $ [Nothing, Just 9, Just 10])
print (getLast $ Last (Just "one") `mappend` Last (Just "two"))
Just 10
Just "two"
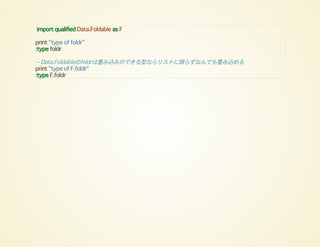
import qualified Data.Foldableas F
print "type of foldr"
:type foldr
-- Data.Foldableのfoldrは畳み込みができる型ならリストに限らずなんでも畳み込める
print "type of F.foldr"
:type F.foldr
74.
-- 実例
print (foldr(*) 1 [1,2,3])
print (F.foldr (*) 1 [1,2,3])
-- Maybeも可能
print (F.foldl (+) 2 (Just 9))
print (F.foldr (||) False (Just True))
Use product
Found: foldr (*) 1 Why Not: product
"type of foldr"
foldr :: forall a b. (a -> b -> b) -> b -> [a] -> b
"type of F.foldr"
F.foldr :: forall (t :: * -> *) a b. Foldable t => (a -> b -> b) -> b -> t a -> b
6
6
11
True
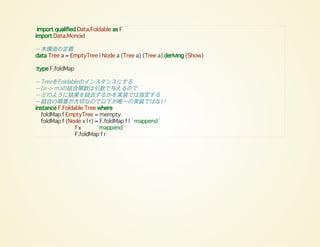
import qualified Data.Foldableas F
import Data.Monoid
-- 木構造の定義
data Tree a = EmptyTree | Node a (Tree a) (Tree a) deriving (Show)
:type F.foldMap
-- TreeをFoldableのインスタンスにする
-- (a -> m)の結合関数は引数で与えるので
-- どのように結果を結合するかを実装では指定する
-- 結合の順番が大切なので以下が唯一の実装ではない
instance F.Foldable Tree where
foldMap f EmptyTree = mempty
foldMap f (Node x l r) = F.foldMap f l `mappend`
f x `mappend`
F.foldMap f r
77.
-- 使ってみる
testTree =Node 5
(Node 3
(Node 1 EmptyTree EmptyTree)
(Node 6 EmptyTree EmptyTree)
)
(Node 9
(Node 8 EmptyTree EmptyTree)
(Node 10 EmptyTree EmptyTree)
)
print (F.foldl (+) 0 testTree)
print (F.foldl (*) 1 testTree)
-- 木の中に3に等しい数があるか調べる
print (getAny $ F.foldMap (x -> Any $ x == 3) testTree)
-- 15より大きい数があるか
print (getAny $ F.foldMap (x -> Any $ x > 15) testTree)
-- Treeをリストに変換
print (F.foldMap (x -> [x]) testTree)
Use :
Found: x -> [x] Why Not: (: [])
F.foldMap :: forall (t :: * -> *) a m. (Monoid m, Foldable t) => (a -> m) -> t a -> m
42
64800
True
False
[1,3,6,5,8,9,10]





![NEWTYPEキーワードnewtype ZipList a = ZipList { getZipList :: [a] }のように使
う新しいキーワード
dataキーワード
独自の代数データ型を作るためのキーワード
typeキーワード
既存の型に型シノニムを与える
newtypeキーワード
既存の型から新たな型を作る
値コンストラクタが1つだけ、フィールドも1つだけとい
う制限の付いたdata宣言だとみなせる](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-4-320.jpg)


![import Control.Applicative
-- 1番目の例
print ([(+1), (*100), (*5)] <*> [1,2,3])
-- 2番目の例
print (ZipList [(+1), (*100), (*5)] <*> ZipList [1,2,3])
print (getZipList $ ZipList [(+1), (*100), (*5)] <*> ZipList [1,2,3])
[2,3,4,100,200,300,5,10,15]
ZipList {getZipList = [2,200,15]}
[2,200,15]](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-7-320.jpg)
![ZIPLIST A型のデータ宣言の書き方1つの方法: data ZipList a = ZipList [a]
ZipList a型には値コンストラクタが1つ( ZipList [a] )しか
なく、その値コンストラクタにはフィールドが1つ( [a])
ZipListからリストを取り出す関数が自動的に手に入るよう
にレコード構文を使っても良い
data ZipList a = ZipList { getZipList :: [a] }
これらの方法は別に悪くはないし実際うまく動く](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-8-320.jpg)

![NEWTYPEキーワードZipList a, CMaybe aのように「1つの型を取り、それを何か
にくるんで別の型に見せかけたい」場合に用いる
ZipList aの実際の定義
newtype ZipList a = ZipList { getZipList :: [a] }](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-10-320.jpg)


![-- [Char]でなくStringにしないと怒られる
newtype CharList = CharList { getCharList :: [Char] } deriving (Eq, Show)
print (CharList "this will be shown!")
print (CharList "benny" == CharList "benny")
print (CharList "benny" == CharList "oisters")
:t CharList -- 型コンストラクタの型
:t getCharList -- CharListと[Char]という2種類の型の間の変換
Use String
Found: [Char] Why Not: String
CharList {getCharList = "this will be shown!"}
True
False
CharList :: [Char] -> CharList
getCharList :: CharList -> [Char]](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-13-320.jpg)






![-- undefinedはブッ壊れた計算を表すHaskellの値
-- 評価すると怒りを爆発させる(専門用語では例外を投げる)
undefined
Prelude.undefined
-- Haskellはデフォルトで遅延評価であるので
-- undefinedを要素に含むリストに対するheadは先頭さえundefinedでなければ成功
print (head [3,4,5,undefined,2,undefined])
3](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-20-320.jpg)





![TYPE
型シノニムを作るためのもの
type IntList = [Int]とすると[Int]型をIntListとも呼べるよ
うになる
2つの呼び名は自由に交換可能
IntList型の値コンストラクタは一切生じない
型注釈にどちらの名前を使うかは自由
type IntList = [Int]
print (([1,2,3] :: IntList) ++ ([1,2,3] :: [Int]))
[1,2,3,1,2,3]](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-26-320.jpg)
![型シノニムを使用する場面型シグネチャを整理して分かりやすくしたいときに使う
特定のものを表すために複雑な型を作る際など
7章の例
電話帳を[(String, String)]という連想リストで表
しPhoneBookという型シノニムで表現](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-27-320.jpg)

![newtype CharList = CharList { getCharList :: [Char] }
-- CharListはリストを中身に持ってはいるがリストそのものではないため
-- これはできない
print (CharList "CharList string ++ " ++ "[Char] string")
Use String
Found: [Char] Why Not: String
Couldn't match expected type ‘String’ with actual type ‘CharList’
In the first argument of ‘(++)’, namely ‘CharList "CharList string ++ "’
In the first argument of ‘print’, namely ‘(CharList "CharList string ++ " ++ "String string")’
-- 一旦リストにすると結合できる
print (getCharList (CharList "CharList string ++ ") ++ "[Char] string")
"CharList string ++ [Char] string"](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-29-320.jpg)





![乗算、リストの結合2引数関数(*)、2引数関数(++)には引数に適用してももう一
方の値を変えないような値が存在
1 * xとx * 1の結果は等しい
[] ++ xsとxs ++ []は等しい
複数の値を1つにまとめる計算をする時、値の間に関数を
挟む順序を変えても結果は変わらない
(3 * 4) * 5と3 * (4 * 5)は等しい
"la" ++ ("di" ++ "ga")と("la" ++ "di") ++ "ga"は等し
い](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-35-320.jpg)
![print (4 * 1)
print (1 * 4)
print ([1,2,3] ++ [])
print ([] ++ [0.5, 2.5])
-- 関数を挟む順序を変えても結果は変わらない
print ((3 * 2) * (8 * 5))
print (3 * (2 * (8 * 5)))
print ("la" ++ ("di" ++ "ga"))
print (("la" ++ "di") ++ "ga")
Evaluate
Found: 4 * 1 Why Not: 4
4
4
[1,2,3]
[0.5,2.5]
240
240
"ladiga"
"ladiga"](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-36-320.jpg)


![MONOID型クラスモノイド
結合的な二項演算子(2引数関数)とその演算に関する単位
元からなる構造
単位元
単位元と他の値を2引数関数に適用した時に返り値が
他の値に等しくなる要素
1は*の単位元であり[]は++の単位元
HaskellにはMonoid型クラスが用意](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-39-320.jpg)
![-- Monoid型クラスの定義
-- (Data.Monoidモジュールにて定義されている)
--
-- mは型クラスの関数定義中で型引数を取らないため
-- FunctorやApplicativeとは違って具体型となる
--
-- class Functor f where
-- fmap :: (a -> b) -> f a -> f b
--
class Monoid m where
mempty :: m
mappend :: m -> m -> m
mconcat :: [m] -> m
mconcat = foldr mappend mempty](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-40-320.jpg)




![リストの例import Data.Monoid
-- リストのモノイド型クラスに対するインスタンス宣言
-- Monoid []でなくMonoid [a]となっているのはMonoidのインスタンスは具体型であるため
-- 実際にはData.Monoidで定義
--
{-
instance Monoid [a] where
mempty = []
mappend = (++)
-}](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-45-320.jpg)
![-- 使ってみる
print ([1,2,3] `mappend` [4,5,6])
print (("one" `mappend` "two") `mappend` "tree")
print ("one" `mappend` ("two" `mappend` "tree"))
print ("one" `mappend` "two" `mappend` "tree")
print ("pang" `mappend` mempty)
print (mconcat [[1,2], [3,6], [9]]) -- デフォルト実装が利用される
-- mempty単体だとどの型に対するmemptyであるか分からないため
-- リストのインスタンスであることを明示
-- 空リストは任意の型に対して適用可能であるため[a]で良い
print (mempty :: [a])
-- モノイド則はa `mappend` bとb `mappend` aが等しいことは要求していない
print ("one" `mappend` "two")
print ("two" `mappend` "one")
[1,2,3,4,5,6]
"onetwotree"
"onetwotree"
"onetwotree"
"pang"
[1,2,3,6,9]
[]
"onetwo"
"twoone"](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-46-320.jpg)



![-- 使ってみる
print "Product example"
print (getProduct $ Product 3 `mappend` Product 9)
print (getProduct $ Product 3 `mappend` mempty)
print (getProduct $ Product 3 `mappend` Product 4 `mappend` Product 2)
print (getProduct . mconcat . map Product $ [3,4,2])
print "Sum example"
print (getSum $ Sum 2 `mappend` Sum 9)
print (getSum $ mempty `mappend` Sum 3)
print (getSum . mconcat . map Sum $ [1,2,3])
"Product example"
27
3
24
24
"Sum example"
11
3
6](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-51-320.jpg)


![-- 使ってみる
print "Any example"
print (getAny $ Any True `mappend` Any False)
print (getAny $ mempty `mappend` Any True)
print (getAny . mconcat . map Any $ [False, False, False, True])
print (getAny $ mempty `mappend` mempty)
print "All example"
print (getAll $ mempty `mappend` All True)
print (getAll $ mempty `mappend` All False)
print (getAll . mconcat . map All $ [True, True, True])
print (getAll . mconcat . map All $ [True, True, False])
{-
こんなふうに包んだり解いたりするのは面倒なので普通はandやorの関数と[Bool]を使う
-}
"Any example"
True
True
True
False
"All example"
True
False
True
False](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-54-320.jpg)












![-- 試す
print (getFirst $ First (Just 'a') `mappend` First (Just 'b'))
print (getFirst $ First Nothing `mappend` First (Just 'b'))
print (getFirst $ First (Just 'a') `mappend` First Nothing)
-- リストの中にJust値があるかも調べられる
print (getFirst . mconcat . map First $ [Nothing, Just 9, Just 10])
Just 'a'
Just 'b'
Just 'a'
Just 9
-- 反対の定義(第二引数優先)のLast a型もData.Monoidに存在
import Data.Monoid
print (getLast . mconcat . map Last $ [Nothing, Just 9, Just 10])
print (getLast $ Last (Just "one") `mappend` Last (Just "two"))
Just 10
Just "two"](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-71-320.jpg)

![-- 実例
print (foldr (*) 1 [1,2,3])
print (F.foldr (*) 1 [1,2,3])
-- Maybeも可能
print (F.foldl (+) 2 (Just 9))
print (F.foldr (||) False (Just True))
Use product
Found: foldr (*) 1 Why Not: product
"type of foldr"
foldr :: forall a b. (a -> b -> b) -> b -> [a] -> b
"type of F.foldr"
F.foldr :: forall (t :: * -> *) a b. Foldable t => (a -> b -> b) -> b -> t a -> b
6
6
11
True](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-74-320.jpg)

![-- 使ってみる
testTree = Node 5
(Node 3
(Node 1 EmptyTree EmptyTree)
(Node 6 EmptyTree EmptyTree)
)
(Node 9
(Node 8 EmptyTree EmptyTree)
(Node 10 EmptyTree EmptyTree)
)
print (F.foldl (+) 0 testTree)
print (F.foldl (*) 1 testTree)
-- 木の中に3に等しい数があるか調べる
print (getAny $ F.foldMap (x -> Any $ x == 3) testTree)
-- 15より大きい数があるか
print (getAny $ F.foldMap (x -> Any $ x > 15) testTree)
-- Treeをリストに変換
print (F.foldMap (x -> [x]) testTree)
Use :
Found: x -> [x] Why Not: (: [])
F.foldMap :: forall (t :: * -> *) a m. (Monoid m, Foldable t) => (a -> m) -> t a -> m
42
64800
True
False
[1,3,6,5,8,9,10]](https://image.slidesharecdn.com/rz3hl8rvsww1cakgbue4-signature-96f1c90753321e270283410e7f81023ab05c2cd5103d10b1684be8e78b9c6a60-poli-150301002845-conversion-gate01/85/Haskell-12-77-320.jpg)





























![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)



























