Assembled by UFO
CGIRÖVIDEN
Ez a dokumentum egy bevezető, amely segítségével az érdeklődő olvasó gyorsan, és szándékaim szerint aránylag
fájdalommentesen megtanulhat CGI programokat készíteni Perl nyelven. Ehhez persze ismerni kell a Perl nyelvet,
amelyhez egy bevezető olvasható a Perl hönyvben. Nem a Perl nyelvről lesz szó, hanem a CGI programozásról. A Perl
csak példanyelvként szerepel, a példák átírhatók több kevesebb erőfeszítéssel más nyelvre is. A nyelvválasztás oka,
hogy ez az a nyelv, amelyet leggyakrabban választanak a programozók Web programozásra.
És természetesen valamennyire ismerni kell a HTML nyelvet is.
A következő fejezetekben áttekintjük, hogy hogyan is működik a Web. Ennek ismerete feltétlenül szükséges, hiszen az
egész CGI programozás erre alapul. Természetesen sokan lesznek, akiknek ez a fejezet már ismerős, a könyökükön jön
ki. Nos ebben az esetben át lehet ugorni. Ha később valami mégsem világos, akkor vissza lehet térni. Ha ezután sem
válik egyértelművé és könnyen érthetővé a szöveg, akkor rosszul írtam meg a könyvet.
Ha már tudjuk, hogy hogyan működik a Web, akkor áttekintjük a CGI fogalmát, mi is az, hogyan kapcsolódik a Webhez,
milyen egyéb, más megoldások vannak. Itt még mindig nem programozunk. Ha valaki ezzel is tisztában van, akkor ezt a
fejezetet is át lehet ugorni, ugyanazok a kitételek vonatkoznak erre, és minden más fejezetre is, mint az előzőre. egy
kicsit precízebben, de nem annyira, mint az RFC. Az RFC lefordítására nem vállalkozom, nem is látom értelmét.
A következő fejezet még mindig nem programozás. Áttekintjük, hogy egy Web szervert hogyan kell felkonfigurálni ahhoz,
hogy Perl CGI programokat lehessen futtatni. Ez az a rész, amelyik az ilyen jellegű bevezetőkben általában nem
szerepel, és a különböző fórumokon felvetett kérdésekből az az érzésem, hogy valóban hiányzik. Itt megvan, remélem
jól. Ugyanakkor meg kell most azonnal jegyeznem, hogy ez a fejezet nem pótolhatja egyetlen Web szerver
dokumentációjának elolvasását sem, mert ahány Web szerver, annyiféle megoldás. Itt csak általánosságokról lesz szó,
olyan dogokról, amelyek általában azonosak minden Web szerver szoftver esetében. Konkrét példaként a WindowsNT
operációs rendszer alatt futó IIS3.0 és IIS4.0 konfigurálását említem, egyszerűen önös érdekből: ezt ismerem jól, és ez
van kéznél.
Ezután már tényleg elkezdünk programozni. Megnézzük azt, hogy a CGI programok hogyan kapják meg a
paramétereiket a Web szervertől, és hogy hogyan kell az eredményt, a válasz Web oldalt megjeleníteni. Milyen fejlécek
kellenek, mik a GET és a PUT paraméterek, milyen környezeti változók vannak stb.
A proxy egy kis kitérő, amely egyáltalán nem CGI programozás, de nagyon hasznos lehet ha valaki mag akarja egészen
precízen tudni, hogy mit is küld a bögésző a szervernek, és viszont. Ez a kis program ugyanazon a gépen futtatható, mint
a böngésző, figyel a 8080 porton, és ha a böngészőn a localhost:8080 proxy beállítást alkalmaztuk, akkor a
böngésző, és a szerver egymás között ezen az alkalmazáson keresztül kommunikál. Ő pedig mindent kiír a képernyőre.
Nincs több titok.
Ezután egy kis elméleti kitérő jön, a session fogalmát tárgyaljuk, majd rögtön ezután a sütikkel, (angolul cookie)
foglalkozunk.
Ha ez is megvan, akkor megnézzük, hogy hogyan kell, lehet a HTTP protokoll segítségével fájlokat feltölteni a Web
szerverre, és hogy a CGI programnak hogyan kell ezeket a fájlokat fogadni.
Ha ez is megvan, akkor a többi már csak hab a tortán. Megnézzük a CGI.pm modult, egy kicsit, nem teljes dokumentáció,
csak belenézünk, és a cgi-lib.pl csomagot.
Végül egy utolsó példaként megnézzük, hogy hogyan kell UNIX alatt a Microsoft által kitalált Active Server Pages jellegű
programozási környezetet kialakítani, Visual BASIC helyett Perl nyelvvel.
Hogyan működik a Web
A Web működéséhez két fontos dolog kell:
• Web szerver és
• Web böngésző.
- 1 -
2.
Assembled by UFO
Hálózatsem árt, hogy a kettőt összekösse, de ez elhagyható. Aki CGI írásra adja a fejét általában ugyanazon a gépen
fogja használni a böngészőjét, mint ahol a szerver fut, ilyenkor a hálózat a egy gépen belül van, virtuálisan.
A böngésző Web oldalakat jelenít meg, amelyeket a Web szervertől kap. Ezeknek a formátuma többnyire HTML, és
lehetnek benne képek. A Web szerver a kért oldalt általában a szerveren lévő diszkről veszi.
Az oldal letöltésének és megjelenítésének folyamata a következő:
• A böngésző megszólítja a Web szervert, és egy TCP/IP csatornát hoz létre a böngésző és a szerver között.
• A csatornán keresztül elküld egy HTTP kérést a szervernek, amelyben meghatározza, hogy melyik oldalt
szeretné letölteni.
• A szerver értelmezi a kérést, előszedi az oldalt, vagy képet és egy HTTP válaszban leküldi a böngészőnek.
• Ezután a TCP/IP csatorna elbomlik. (Vagy nem, lásd keep-alive.)
A csatorna Perl programozási szempontból olyan mint egy nem pufferelt fájl, nem open-nel kell megnyitni, hanem némi
socket hókusz-pókusszal, de utána teljesen olyan, mint egy olyan fájl, amelybe print utasítással lehet írni, és <>
operátorral lehet belőle olvasni. Ezzel azonban a CGI programozáshoz nem kell törődni, ez csak akkor érdekes, ha valaki
Perl-ben akar HTTP klienst (böngészőt) írni.
A HTTP kérés és HTTP válasz egyszerű szövegfájl. A formátuma a TCP/IP-ben szokásos:
• bevezető fejléc paraméter: érték alakú sorokkal,
• üres sor
• test (body) a fájl végéig.
(Azonnal jön egy példa.) Ez egy nagyon egyszerű protokoll, éppen az egyszerűsége az oka annak, hogy olyan jól
elterjedt. Amikor a böngésző megjelenített egy oldalt a kapcsolat lebomlik, a szerver foglalkozhat más kliensekkel, nincs
semmilyen erőforrás az éppen inaktív, olvasó klienshez kötve. Amikor újabb oldalt kér le a felhasználó a folyamat
megismétlődik.
A CGI és általánosabban a Web programozás ott jön be a képbe, amikor az URL által meghatározott oldal nincs
statikusan a szerveren, hanem valahogy elő kell állítani a szerveren lévő információkból. A sima HTML oldalak és képek
lekérését úgy is lehet tekinteni, mint a nulla operátort, amikor a Web szerver nem csinál semmit, csak leküldi a kliensnek
a Web oldalt. Amikor azonban az információ nem ilyen módon áll rendelkezésre, vagy ha a kérés feldolgozása során a
szerveren tárolt információk megváltoznak, akkor már Web szerver programozásról van szó.
Ilyenkor a szerver nem csak beolvas egy fájlt valamelyik diszkjéről, hanem elindít valamilyen programot, és ennek a
programnak az eredménye adja a szerver válaszát. Egy nagyon egyszerű példaprogram kiírhatja az 1970. január 1. nulla
óra nulla perc, nulla másodperc időpont óta eltelt időt másodpercekben:
#!/usr/bin/perl
require 'state.pl';
print_http_state('200 OK');
$time = time();
print <<END;
Content-type: text/html
- 2 -
3.
Assembled by UFO
<HTML>
<BODY>
$time
</BODY>
</HTML>
END
Természetesenez nem egy komoly CGI program, csak egy nagyon
egyszerű példa, de jól látható belőle, hogy a Web szerver egy olyan
választ ad, amelyet a program állít elő. A program a szabványos
kimenetére küldi az egész HTTP választ (nem mindig így kell!!), amely
jelen esetben két fejléc sorból, és egy rövid törzsből áll.
Ezzel a legelső cgi programot meg is írtuk. Persze nem csak cgi felület
létezik. Nagyon sok lehetőség van arra,hogy a Webszerver program
miként indítsa el az alkalmazást, annak hogyan adja át a paramétereket,
és hogyan kapja meg az eredményt.
A cgi programozásnál a Webszerver egy külön processzt indít el, és ennek a processznek a parancsorában, a
szabványos bemenetében és a környezeti változókban adja át a http kérés paramétereit, a program által megjelenítendő
HTML oldalt pedig a processz szabványos kimenetéről veszi.
Egy másik lehetőség az isapi felület, amelyik nem indít el egy külön processzt, hanem az alkalmazásokat, mint
dinamikusan szerkeszthető könyvtárakat kell a Webszerverhez illeszteni. Ez sokkal gyorsabb lehet, mint a cgi, mert nem
indít új processzt, viszont egy végtelen ciklus, vagy bármely más programhiba az egész webszerver processzt
veszélyezteti. És nem minden webszerver tudja, csak a Microsoft IIS, és az Apache. (Azóta, hogy ezt írtam lehet, hogy
mások is tudják.)
Intranet alkalmazások architektúrája
Sok mindent lehet intranet alkalmazásnak tekinteni az SMTP levelezéstől kezdve, az Interneten keresztüli titkosított
csatornákkal összekötött LAN-okon át, a hagyományos alkalmazásokig. Ez a fogalom leggyakrabban azonban olyan
alkalmazást jelent, amelyet Web böngésző segítségével lehet használni. Ilyen alkalmazások ma már vannak, és egyre
többen lesznek. A hagyományos alkalmazások egymás után kapnak Webes felületet, és olyan új alkalmazások is
kialakulnak, amelyek eddig nem léteztek, és amelyek hatékony megvalósítását a Web technológia teszi lehetővé.
Ugyanakkor a Webet elsősorban nem arra találták ki, hogy univerzális kliens felület legyen kliens-szerver
alkalmazásokhoz annak ellenére, hogy úgy tűnik, ez válik az elsődleges felhasználási móddá. A Web eredeti
felhasználása információpublikálás, amely csak később lett kiegészítve olyan elemekkel, amelyek lehetővé teszik az
eredetihez képest fordított, a kliens felől a szerver felé haladó információk továbbítását. Ezekkel az elemekkel már
lehetővé válik Web alapú alkalmazások megírása, de sok olyan kérdés nyitva marad, amelyre nem ad a Web technológia
egyértelmű választ.
CGI, ISAPI, NSAPI, FastCGI
A Web technológia a HTTP protokollon alapul. Ez a protokoll pedig nagyon egyszerű. Nem biztosít a mai
követelményeknek megfelelő felhasználói azonosítást. Alapvetően kapcsolat nélküli információ cserét biztosít, ezért a
http protokollnál nincs olyan fogalom, mint bejelentkezett felhasználó, vagy kilépés a rendszerből. Pedig ahhoz, hogy
alkalmazásokat készítsenek a programozók, ezekre feltétlenül szükség van.
A Webes alkalmazások megismeréséhez még egy szabványt, vagy szabvány csoportot ismerni kell. Ezek azok a
szabályok, amelyek azt határozzák meg, hogy a Web szerver program, amely a hálózaton keresztül HTTP protokollal
kommunikál a böngészővel, hogyan és mikor indítja el a szerver oldali alkalmazást, hogyan adja át neki a HTTP kérésben
szereplő adatokat, amelyek alapján a program el tudja látni feladatát, és hogyan veszi át a program futási
eredményeképpen születő, a HTTP válaszhoz szükséges információkat. A szabvány a Common Gateway Interface
(CGI), amely a UNIX világ hagyományaihoz illeszkedve azt mondja, hogy a Web szerver a programot minden egyes
HTTP kéréshez külön processzként indítja el, a kérésben szereplő paramétereket a parancssorban, a szabványos
- 3 -
4.
Assembled by UFO
bemenetenés környezeti változókban adja át, a választ pedig a program szabványos kimenetéről veszi. Ez a szabvány
elterjedt, és gyakorlatilag minden Web szerver támogatja. A gond vele az, hogy minden egyes kéréshez egy új processzt
elindítani külön védett címtartománnyal egy kicsit túlzás, feleslegesen leterheli az operációs rendszert. Az olyan
operációs rendszereknél ahol egy processz aránylag primitív, mint a UNIX-nál, ez nem okoz komoly lassulást, de a
Windows NT vagy például az OpenVMS operációs rendszer alatt egy processz elindítása már komolyabb erőforrást
igényel. Emiatt alakult ki két másik ajánlás is, az egyik a Microsoft ISAPI, a másik a Netscape NSAPI ajánlása. Ezek
szerint az ajánlások szerint a Web szerver nem indít el egy külön processzt, hanem csak a Web szerver processzen belül
egy külön szálat. Ez sokkal gyorsabb, kevésbé terheli le a rendszert. A hátránya a CGI-vel szemben az, hogy ezek nem
széleskörűen támogatott eljárások, és mivel nincsenek külön memória területe lefoglalva, ezért a Web szerver és az
egyes szálak nincsenek egymástól védve. Emiatt az ilyen módon indított alkalmazások kevésbé robusztusak, ha
valamelyik szálban hiba történik az egész Web szervert, vagy UNIX-os terminológiával http démont kell újraindítani.
Végül, de egyáltalán nem utolsósorban mind a CGI, mind pedig az ISAPI és NSAPI megoldás hátránya, hogy egyáltalán
nem biztosítanak folyamatos környezetet egy kliens szerver kapcsolathoz. Ha valaki "bejelentkezik" egy Web
alkalmazásba, akkor a szerver oldalon futó alkalmazásnak kell gondoskodnia arról, hogy a felhasználót
bejelentkezettként tartsa nyilván, figyeljen arra, hogy ha a felhasználó kimondottan nem jelentkezik ki, akkor is törölje a
bejelentkezett felhasználók közül bizonyos idő elteltével, és minden ezzel járó feladatot elvégezzen. Azonban még ennél
is komolyabb feladat az, hogy olyan alsóbb szintű szolgáltatások, mint adatbázis kapcsolat hatékony felhasználása
nehézkes. Egy CGI alkalmazás, ha megnyit egy adatbázis kapcsolatot, például ODBC felületen keresztül, azt nem tudja
nyitva tartani, mert maga a processz, amely megnyitja, véget ér, és a felhasználó újabb rendszerhez fordulásakor újra, és
újra meg kell nyitni, és le kell zárni a kapcsolatot. A megoldás az lehet, ha a szerver oldali alkalmazás egy külön
processzt indít el minden egyes felhasználó számára, amely azután nem ér véget, hanem mindaddig fut, amíg a
felhasználó "be van jelentkezve", és amely megtartja a többi alkalmazással, például adatbázissal a kapcsolatot, és csak a
felhasználó által kezdeményezett, vagy kidobási idő lejártával automatikusan végrehajtott kijelentkezéskor fejezi be
működését. A közbenső események, és felhasználói kommunikáció során a Web szerver RPC-vel, socket felületen, vagy
neves csatornán (named pipe) keresztül kommunikál a futó processzel.
Az is megoldás lehet, ha a CGI, ISAPI, NSAPI alkalmazás csak a legalapvetőbb feladatokat végzi el és az igazi
funkcionalitást egy Windows NT szerviz vagy UNIX démon végzi el. Ez a megoldás lehetőséget ad arra, hogy a
felhasználó bejelentkezésekor felépülő adatbázis kapcsolat csak a felhasználó kijelentkezésekor szakadjon meg, és ne
kelljen minden egyes érintésnél újra felépíteni ezt a kapcsolatot. Ez a megoldás sokkal kevésbé terheli a gépet, és ennek
megfelelően sokkal jobb teljesítményt nyújt, mint a teljesen a CGI, ISAPI, NSAPI programban megvalósított
funkcionalitás, de még mindig nem választja szét operációs rendszer szinten az egyes felhasználói memória területeket,
adatterületeket, és processzor időt. Ha a funkcionalitást nem egy démon, vagy szerviz valósítja meg, hanem minden
egyes felhasználó számára a saját neve alatt futó processzt indít el a rendszer, akkor több más dolog mellett az
operációs rendszer gondoskodhat az egyes felhasználói memória területek védelméről, vagy arról, hogy az egyes
felhasználók ne használjanak fel túl sok számítási erőforrást. Azaz ne lépjék túl processzor kvótájukat, és ezzel ne
terheljék le a többi felhasználó számára használhatatlanul lassúra a gépet. Persze ez csak olyan rendszerben képzelhető
el, amelyik ismeri a processzor kvóta fogalmát.
A külön processzeknek gyakorlati jelentőségük is van. Valaki azt mondhatja, hogy ő nem fog olyan programot írni,
amelyik túl sok erőforrást eszik, elveszti a lefoglalt memóriát stb. Vannak azonban olyan UNIX változatok ahol maguk a
rendszerfüggvények teszik meg ezt. (Az Apache Web szerver dokumentációja szerint a Solaris néhány könyvtári rutinja
ilyen, és ezért konfigurálhatók az Apache processzek olyan módon, hogy bizonyos számú http kérés kiszolgálása után
leállnak, és a rendszer új processzt indít helyettük.)
A megoldás talán a legújabb, és még formálódó szabvány lehet, a FastCGI, amelyet az OpenMarket támogat. Jelenleg
az OpenMarket Web szervere az egyetlen üzleti Web szerver, amelyik ezt a szabványt támogatja, valamint olyan
ingyenes szerverek, mint az Apache, NCSA httpd. Sem a Microsoft, sem pedig a Netscape nem tették még le a voksukat
e mellet a szabvány mellett. Várható azonban, hogy ingyenes programként meg fognak jelenni teljes értékű ISAPI és
NSAPI felületű FastCGI megvalósítások, mint ahogy elkészítették a CGI FastCGI átjárót is (bár ez utóbbi csak fejlesztési
célokra jó, elveszti azokat a tulajdonságokat, amitől a FastCGI fast, azaz gyors).
A FastCGI szabvány a CGI két feladatát szétválasztja. A CGI szabvány előírja azt, hogy a Web szerver hogyan indítja el
az alkalmazási programot, vagy script-et, mint külön processzt, és azt, hogy hogyan kommunikál vele. A FastCGI
szabvány nem törődik azzal, hogy egy processz hogyan indul el, ezt a Web szerverre, vagy valamilyen más szerverre
bízza, csak azt írja le, hogy a Web szerver és a futó processz hogyan kommunikál.
A FastCGI szabvány a HTTP kérés tartalmát illetve a választ socket felületen keresztül küldi el az alkalmazásnak, és
azon keresztül is fogadja a választ. Ez lehetővé teszi, hogy az alkalmazás ne ugyanazon a gépen fusson, mint a Web
szerver, és talán ezt az előnyt nem akarták a szabvány fejlesztői azzal, hogy előírják a processzek kezelésének módját. A
Web szerver a socket-en keresztül csomagokat küld az alkalmazásnak és a választ is így fogadja. Mivel az egyes http
kérésekhez nem indul el új processz, mint a CGI esetében, ezért minden az adott FastCGI programra hivatkozó http
- 4 -
5.
Assembled by UFO
kérésugyanahhoz a processzhez fog elérkezni. Ezeket a kéréseket a Web szerver és FastCGI processz közötti
kommunikációban a Web szerver által generált egyedi azonosítók hordozzák, amelyek megjelennek a processz és a Web
szerver közötti minden egyes csomagban.
A FastCGI egyik előnye, hogy gyorsabb, hiszen nem kell minden egyes http kéréshez egy új processzt létrehozni. A
másik nagy előnye, hogy nem feltétlenül kell a Web szerver gépen futnia az alkalmazásnak. A harmadik, és talán
legnagyobb előnye, hogy a FastCGI processz az egyes http kérések között megtarthatja az állapotát memóriában, nem
kell elvesztenie az adatbázis kapcsolatokat.
A hátránya, hogy ezzel több feladat hárul a fejlesztőkre. Fel kell készülniük arra, hogy amíg az egyik kérést kiszolgálják,
újabb kéréseket kap ugyan a processz. Ezt pedig csak többszálú programozással lehet megoldani, amelyre például a
Perl nyelv jelenlegi verziója 5, amely a Web programozás legkedveltebb nyelve, nem alkalmas. És más nyelveken sem
túl egyszerű ilyen alkalmazások fejlesztése, főleg nem a hibakeresés.
Egy félmegoldás ennek feloldására az, hogy egy FastCGI alkalmazás több példányban is fut akár különböző gépeken, és
a Web szerver mindig kiválaszt egyet az adott URL-hez rendelt processzek közül. Ezzel el lehet kerülni a többszálú
programozást, és egyszerre több kérést is ki lehet szolgálni, egyszerre annyit, ahány processz elindult az alkalmazást
futtatva. Viszont ez esetleg kevesebb, mint amennyit maga a rendszer elbír. Ezért ez csak félmegoldás, és ezzel elvész
annak a lehetősége, hogy a processz a memóriában őrizze meg az állapotát és az adatbázis kapcsolatokat, hiszen hol az
egyik, hol a másik processz indul el.
Emiatt egyes megvalósítások, de nem maga a FastCGI szabvány kitalálták a session affinity fogalmat. Ez azt jelenti,
hogy egy session-höz tartozó http kérések mindig ugyan ahhoz a FastCGI processzhez kerülnek. Ha valaki valahogyan
bejelentkezett, akkor ezentúl mindig ugyanaz a processz fogja a kéréseit kiszolgálni, amíg a session tart. A session
fogalma azonban nem túl jól definiált. Eloszthatja a szerver a http kéréseket a processzek között a kérést feladó kliens
oldal IP címe szerint. Ez gondot okoz az IP címet váltogató proxy szerverek mögött ülő felhasználóknak, pl. AOL. De
eloszthatja kéréseket az URL bizonyos darabjai szerint. Ennek kezelése megjelenik a FastCGI programban, és ebben a
pillanatban - mivel ez már nem a FastCGI specifikáció része - a program már egy adott Web szerverhez fog kötődni.
Kapcsolattartás
A felhasználó azonosítására három megoldás lehetséges. Az első, használni a HTTP protokoll által támogatott "basic
authentication", azaz alapszintű felhasználó azonosítást, amely azonban a nevének megfelelően nagyon alapszintű. A
másik lehetőség a Microsoft Internet Explorer-be épített kérdezz-felelek azonosítás, amely viszont nem szabványos és
minden más böngésző használót kizár a rendszerből. A harmadik lehetőség saját azonosító rendszert írni, amely annyira
lehet biztonságos, amennyire a programozó paranoiás (azaz nagyon), viszont sok programozást igényel.
A http protokoll rendkívül egyszerű. A kliens és a szerver között a kapcsolat mindig a kliens kezdeményezésére jön létre.
A kliens az IP protokoll felhasználásával megszólítja a szervert, és amikor az válaszol, létrejön egy csatorna. Ezen a
csatornán keresztül a kliens elküldi az úgynevezett http kérést, amelyre a szerver a http választ adja, és ezek után
lebomlik a kapcsolat. A szabvány újabb, 1.1 változata szerint lehetőség van a kapcsolat megtartására, és újabb http
kérés elküldésére, ez azonban csak a több darabból álló dokumentumok letöltését gyorsítja, és ettől még a protokoll
továbbra is kapcsolat nélküli. Ez azt jelenti, hogy nincs olyasmi, mint a telnet, vagy ftp kapcsolatnál a felhasználói
bejelentkezés, és élő kapcsolat akkor is, amikor a kliens éppen nem cserél adatot a szerverrel.
Mint általában a többi TCP protokollnál, a http kérés és válasz is sor orientált szöveges protokoll, két részből áll: egy
fejlécből, és egy testből, amelyeket egy üres sor választ el. A fejléc első sora jelzi, hogy a tartalom a http protokollnak
megfelelő formátumú, és hogy milyen verziót használ a kliens vagy a szerver. A fejléc minden további sora tartalmazza a
fejléc mező megnevezését, amely után egy kettőspont és szóköz áll, majd a mező értéke következik. Példaképpen egy
nagyon egyszerű http válasz, amelyet egy Web szerver küldhet a böngészőnek:
HTTP/1.0 200 OK
Content-type: text/html
<html><head><title>Hello</title></head><body>Hello!</body></html>
Ezt a választ kapva a Web böngésző a "Hello" üzenetet jeleníti meg a felhasználó képernyőjén.
- 5 -
6.
Assembled by UFO
Ahttp üzenetek fejlécében rengeteg járulékos információ foglalhat helyet. A kérésben a böngésző általában elküldi a
saját típusát, verzióját, és hogy milyen operációs rendszeren fut, így a szerverek pontosan láthatják, hogy ki használ
Netscape, ki Internet Explorer vagy éppen valamilyen más böngészőt, és ezt felhasználva például különböző módon
küldhetik el ugyan azt az információt a különböző böngészőknek kihasználva azok speciális tulajdonságait. A kliens olyan
információt is küldhet a szervernek, amely meghatározza, hogy egy információt milyen körülmények között kér.
Előfordulhat, hogy már korábban letöltött valaki egy információt, és csak azt szeretné megtudni, hogy változott-e az adott
oldal. Ilyenkor a fejlécmezők segítségével a böngésző mondhatja azt a szervernek, hogy csak akkor küldje át a hálózaton
a dokumentumot, ha az újabb, mint egy bizonyos időpont. Megteheti a böngésző azt is, hogy egy félig letöltött kép
folytatását kéri, amennyiben az nem változott azóta, hogy az első felét letöltötte.
A http válasz fejlécében a szerver olyan információkat küldhet, amelyek az oldal megjelenítését, tárolását, illetve a proxy
szervereken keresztüli továbbítását vezérlik. Meghatározhatja a szerver, hogy egyes oldalakat ne tároljon a cache
memóriájában egyetlen proxy vagy a böngésző sem. Ennek lehetnek biztonsági okai. Küldhet a fejlécben olyan állapot
azonosító információkat, amelyeket a böngésző a legközelebbi http kérés fejlécében visszaküldhet. Ezeket hívják cookie-
nak. Vagy küldhet a fejlécben olyan hibajelzést, amely hatására a böngésző felhasználói nevet és kulcsszót kérő ablakot
jelenít meg a felhasználó előtt, és amely segítségével valamilyen "bejelentkezés" megvalósulhat.
A HTTP alapszintű azonosítás első lépése, hogy a szerver egy oldal lekérésekor hibaüzenetet küld a kliensnek, egy olyan
hibakóddal, amely jelentése: Azonosítás nem megfelelő! Ekkor a böngésző egy kis ablakot nyit a képernyőn, és
megkérdezi a felhasználótól a bejelentkezési nevét és jelszavát, majd pedig az előző HTTP kérést újra elküldi egy olyan
fejlécmezővel kiegészítve, amely tartalmazza a felhasználói azonosítást. Ezt a mezőt minden további kéréssel is elküldi a
böngésző. Ez olyan, mintha valakivel beszélgetve minden egyes mondat előtt újra be kellene mutatkozni.
A megoldás előnye, hogy a böngészők és a szerverek is támogatják ezt a megoldást, szabványos, és megfelelő
biztonságot adhat például egy helyi hálózaton, amely fizikailag védett a lehallgatás ellen. Ugyanakkor ez a megoldás nem
programozható szabványosan! Amíg a szabvány rögzíti, hogy hogyan kell elküldeni az azonosítási információkat, nem
rögzíti azt, hogy a Web szerver program, és az ezt használó alkalmazás közötti kommunikációban ez az információ
hogyan cserélődik. Ennek oka az, hogy a szabvány tervezői nem akarták a Web oldali alkalmazásokat üzemeltetők
kezébe adni a jelszavakat, nem akarták, hogy egy egyszerű ki script hozzáférhessen a felhasználók jelszavához. Úgy
gondolták, hogy ezt a fajta azonosítást támogatják majd maguk a Web kiszolgáló programok, például a Microsoft IIS,
Netscape Web szerver vagy a szabadon terjeszthető, ingyenes Apache. Ez így is van, csak nem mindig elegendő. Ha
egy olyan Web oldalt akar valaki elérni, amelyiknek a fájlrendszerben megadott védelme nem engedi a Web szerver
processz számára, hogy olvassa, akkor a Web szerver az alapszintű azonosítást használva a felhasználó nevében próbál
hozzáférni a fájlhoz, legyen az futtatható, vagy statikus HTML lap. Ezzel tehát megoldható, hogy az egyes oldalak, Web
szerver oldali programok védettek legyenek, de a megoldás mégsem az igazi.
Gondoljunk a Web áruházra, mint nagyon egyszerű alkalmazásra. A Web áruházba "bemennek" a vásárlók, azonosítva
vannak, hiszen valahol nyilván van tartva, hogy ki mit vásárol, mi van a kosarában, mi a hitelkártya száma stb. Tehát
valahogy minden egyes http kérésnek hihetően, biztonságosan tartalmaznia kell a felhasználó azonosítását. Erre elvileg,
de csak elvileg lehetne használni a szabványos alapszintű azonosítást, feltéve, hogy nem bánjuk, hogy a felhasználó
kulcsszava minden egyes HTTP kérés során keresztül megy a hálózaton. Ebben az esetben minden egyes felhasználót
fel kell venni az operációs rendszerbe, mint felhasználót például a Microsoft IIS esetében és ez nem feltétlenül
biztonságos, és nem is biztos, hogy kivitelezhető.
Ha saját azonosítási és bejelentkezés nyilvántartási rendszer írására adja valaki a fejét, mint e cikk szerzője tette, akkor
nyilván kell tartania a felhasználókat minden szükséges rendszer adattal együtt, és gondoskodni kell arról, hogy a
felhasználók bejelentkezhessenek, és a bejelentkezés után a bejelentkezés nyilván legyen tartva, azaz ne kelljen minden
egyes bejelentkezés után újra és újra bejelentkezni. Valahogyan gondoskodni kell arról, hogy a kliens minden egyes
újabb kérésében legyen olyan információ, amely alapján biztonsággal azonosítani lehet a felhasználót. A biztonságos
azonosítás olyan módon történhet, hogy a szerver a bejelentkezés után létrehoz egy véletlenszerű kulcsot, amelyet a
HTTP válaszban elküld a kliensnek, és amelyet a kliens a következő HTTP kérésben visszaküld a szervernek. A szerver
ellenőrzi, hogy ez a kulcs valóban ki lett-e adva azonosításra az adott felhasználónak, és ha igen, akkor egyéb
paraméterek megvizsgálása után engedélyezi, vagy nem engedélyezi a HTTP kérés kiszolgálását. A kulcsot a biztonsági
kívánalmaknak, és a paranoia fokának megfelelően lehet gyakrabban, vagy ritkábban változtatni. Ezen kívül lehetőség
van olyan feltételek ellenőrzésére, mint, hogy a HTTP kérés ugyan arról az IP címről érkezett-e, mint ahonnan a
felhasználó bejelentkezett, vagy ugyan azt a böngészőt használja-e, mint korábban, stb.
A kulcsinformáció elküldése a HTTP válaszban több lehetőség is van. Ha az alkalmazás úgy van megírva, hogy miden
egyes HTML oldalt a szerver oldali alkalmazás generál, akkor a szerveralkalmazásnak olyan HTML fájlt generálhat, ahol
minden egyes HTML referenciában az URL-ben a script neve után a paraméterek között szerepel az aktuális kulcs, illetve
a formákban rejtett változókban van megadva. Ekkor a referenciát követve, vagy egy formát elküldve a böngészőből a
felhasználó automatikusan elküldi a szerver által a HTML kódban elhelyezett kulcsot. Az előbbi esetben a CGI
- 6 -
7.
Assembled by UFO
alkalmazása parancssor paraméterek között, míg a második esetben a szabványos bemenetén kapott paraméterek
között kapja meg a kulcsinformációt.
Egy másik lehetőség a kulcsinformáció süteményben való elhelyezése.
A süti - angolul cookie - egy olyan információ, amelyet a szerver a HTTP válasz fejlécében helyez el, és amelyet a kliens
ettől kezdve egy ideig minden egyes HTTP kérés fejlécében elküld a szervernek. A szerver megadhatja azt az URL
tartományt, amelynek a sütit el kell küldeni, illetve megadhat egy időtartamot, ameddig a süti érvényes. Ennek lejártakor a
kliens elfelejti a sütit, és nem küldi többet a szervernek. Egy szerver megadhat több sütit egyszerre, vagy egymás utáni
HTTP válaszokban. A kliens oldalon pedig lehetnek több szerverről kapott sütik is. A szerver által megadott tartomány
vonatkozhat például csak a szerverre. Ebben az esetben a kliens a sütit csak az adott szervernek küldi el a további HTTP
kérésekkel, de ha egy másik szerverről kér le a böngésző információt, akkor annak nem küldi el a sütit. De küldhet a
szerver olyan sütit is, amely a szerver csak bizonyos részeire vonatkozik, például a /scripts alkönyvtárra, ebben az
esetben a kliens csak a CGI scripteknek fogja elküldeni a sütit, ugyanezen szerveren a statikus Web oldalak lekéréséhez
nem. Viszont lehetőség van arra is sajnos, hogy olyan tartományt adjon meg a szerver, amely alapján a kliens az egyik
szervertől kapott sütit egy másik gépnek is elküldi. Ad abszurdum, az is elképzelhető, hogy a programozó lustasága miatt
olyan tartományt ad meg a szerver, hogy azután a kliens a sütit annak lejáratáig minden gépnek elküldi.
A kliens minden olyan sütit elküld egy HTTP kéréssel, amely még nem járt le, és a kérésben szereplő URL benne van a
süti érvényességi tartományában. Ez azt jelenti, hogy egy HTTP kéréssel a kliens akár nagyon sok sütit is elküldhet,
jelentősen növelve a HTTP forgalmat, esetenként feleslegesen.
A sütik kezelése a felhasználó számára láthatatlan. Ha csak nem veszi valaki magának a fáradtságot, hogy
szövegszerkesztővel beleeditáljon a megfelelő böngésző fájlokba, akkor a böngésző nem mutatja meg, hogy milyen
tartalmú, lejáratú és tartományú sütit küld a HTTP kéréssel a szervernek, illetve, hogy az egyes szerverektől milyent kap.
Emiatt és azért, mert a szerver által meghatározott tartományra nincsen megkötés a Netscape ajánlásában, a sütik
komoly biztonsági rést jelenthetnek. Persze csak akkor, ha valamilyen szerveralkalmazást igénytelenül írnak meg, és
nem figyelnek a felhasználó biztonságára.
Példaképpen tekinthetjük az Internetes áruházakat, mert éppen ezek között volt, vagy talán van is néhány olyan, amelyet
hanyagul készítettek el, és emiatt a vevőik kerültek veszélybe.
Egy Internetes áruház használata során a felhasználó több lapon halad keresztül, miközben a virtuális kosarába rak
megveendő árukat. Annak a nyilvántartása, hogy egy vevő kosarában milyen áru van és a vevő azonosítása általában
sütikkel történik. A megoldás az lehet, hogy a vevő kap egy azonosítót, amelyet automatikusan a szerver generál
vigyázva arra, hogy egy azonosítót ne adjon ki kétszer, és ezt elküldi a kliensböngészőnek. A vevő kosarában levő árukat
egy adatbázis tarthatja nyilván, amelyben minden vevőhöz tartozik egy vagy több rekord tárolva az eddigi vásárlásait, a
hitelkártyaszámát, nevét, szállítási címet stb.
Persze ez a szerver oldalon komoly erőforrást igényel. Az áruház üzemeltetője számára olcsóbb, és a programozók
számára kényelmesebb, ha ezeket az információkat mind belepakolják a sütikbe, és keresztül küldik a hálózaton. Ekkor
nem kell adatbázisban keresni a felhasználói azonosító alapján, hanem minden rendelkezésre áll a sütiből. És a
hitelkártyaszámot lehet használni vevői azonosításra, hiszen az biztosan egyedi. A vevő pedig mit sem vesz észre a
dologból, legfeljebb egy kicsit lassabb lesz a kommunikáció. Ezért ez a megoldás nem igazán elegáns. És esetleg
minden egyes alkalommal a hitelkártya száma is átmegy a hálózaton. Ezért ez a megoldás nem igazán biztonságos. És
ez még nem minden. Volt a hálózaton olyan bolt, amelynek programozói mindezen merényletek mellett még arra is lusták
voltak, hogy rendesen beállítsák a sütik érvényességi tartományát, így a vevők a bolt meglátogatása, és egy esetleges
vásárlást követően - amikor is megadták a hitelkártya számukat - minden meglátogatott Web szervernek elküldték ezeket
az információkat. Ezért ez a megoldás egyáltalán nem biztonságos :-)
Ennek az az előnye, hogy nem kell minden egyes generált HTML oldalon gondoskodni arról, hogy a megfelelő kulcs
információt felküldje a kliens. A hátránya viszont az, hogy nem minden böngésző képes kezelni a sütiket, és a szerver
által egyszer már a kliensnek leküldött sütit nem lehet törölni, csak megvárni, amíg az lejár. Ha pedig egy kulcs még nem
járt le, de az érvényessége már a vége felé jár, akkor újat kell a kliensnek adni. A rejtett változókban elküldött kulcs
esetén ezt az új kulcsot fogja a következő alkalommal a kliens a szervernek visszaküldeni. Ha azonban a kulcsot a
szerver és a kliens között süti hordozza, akkor az új kulcs kiadása után a szerver a régi kulcs lejáratáig azt is megkapja.
Erre a szervernek külön figyelnie kell.
A sütinek még egy előnye van a rejtett változókkal szemben. A rejtett változók az oldalakhoz kötődnek, így ha a kliens
oldalon a felhasználó a böngésző vissza gombját használva visszalép egy korábbi oldalra, akkor a rejtett változóban adott
kulcsok közül azt fogja legközelebb a szervernek elküldeni, amit a szerver azzal az oldallal küldött le a kliensnek. Ha ez
az oldal nagyon régen került a szerverről a böngészőhöz, akkor ez a kulcs esetleg már nem érvényes. Ha viszont a
- 7 -
8.
Assembled by UFO
kulcsotegy süti hordozza, akkor nincsen ilyen gátja a böngésző navigációs eszközeinek használatában, mindig azokat a
sütiket küldi el a böngésző, amelyeket legutoljára kapott meg, és amelyek még érvényesek.
A FastCGI szabvány is támogatja a saját azonosítási és engedélyezési rendszert, és segít az azonosítási
programrészeket és a "valódi" funkcionalitást elválasztani. Ezt olyan módon teszi, hogy definiál ún. authorizer
alkalmazásokat, amelyeket a http kérés kezdetekor lefuttat, még esetleg a http kérés törzsének megkapása előtt. Ezek az
alkalmazások nem is kapják meg az egész http kérést, csak a fejlécben szereplő információkat. Ha a processz által
visszaadott http válasz, amely a Web szerverhez és nem feltétlenül a klienshez megy tovább a 200 OK státusz kódot
tartalmazza, akkor a Web szerver engedélyezettnek veszi a kérést, és továbbítja a megfelelő FastCGI alkalmazásnak,
amelynek most már nem kell azzal törődnie, hogy kiszolgálhatja-e a kérést. Ha az authorizer alkalmazás egyéb kódot ad
vissza, akkor a Web szerver elutasítottnak tekinti a http kérést, és az authorizer válaszát küldi vissza a kliensnek, mint
http választ. Ilyenkor nem indul el az igazi FastCGI processz.
Összefoglalás
Mi lehet mindezeknek a végső konklúziója? Melyik felülete használjuk Web alkalmazások fejlesztéséhez? Természetesen
nem lehet egyértelmű választ adni. Ha valaki olyan alkalmazást fejleszt, amely egyébként is nagyon kötődik a Windows
NT szerver platformhoz, például használ OLE-n keresztül egyéb alkalmazásokat, akkor nyugodtan választhatja az ISAPI
felületet. Ha nem fontos a Web szerver program cserélhetősége, és Netscape szervert használ, akkor használható az
NSAPI. A CGI minden esetben használható, jól megvalósított, minimális a különbség az egyes változatok között. Nagyon
jól használható azokban az esetekben, amikor az operációs rendszerek és a Web szerverek közötti hordozhatóságot
kívánja valaki használni. A FastCGI egyenlőre inkább kísérletezésre való, még nem egészen kiforrott, de mindenképpen
figyelembe kell venni, amikor valaki CGI alkalmazást fejleszt, hogy könnyen átvihető legyen majd FastCGI alá.
Referenciák
NSAPI http://www.netscape.com
ISAPI http://www.microsoft.com
FastCGI http://www.fastcgi.com
Perl http://www.perl.org
http://www.perl.com
CGI FAQ
CGI definíció
Mivel ez a jegyzet nem referencia, arra ott van az RFC, ezért itt egy kicsit kevésbé precízen, de erőm szerint nem
pongyolán következik a cgi szabvány leírása.
Egy cgi program ugyan azon a gépen fut, mint a webszerver. A cgi programot a webszerver processz indítja el, mint
gyerekprocesszt. Azt, hogy melyik programot kell elindítani a webszervernek a http kérés URL-jéből, és természetesen a
konfigurációs fáljaiból találja ki. A processz parancssor-argumentumként megkapja a http kérés GET paramétereit, azaz
azt a füzért, amelyik általában az URL-ben a kérdőjel után áll. A szabványos bemeneten pedig megjelenik a http kérés
POST paramétere, vagyis az az állomány, amely a http kérés fejléce után következik egészen a HTTP kérés végéig. A
fejlécet nem kapja meg a cgi processz, semmi köze hozzá, hiszen az tartalmazhat jelszót, amelyet a webszerver maga
ellenőriz.
A http fejlécből kiszedhető információk egy részét környezeti változókban kapja meg a cgi processz. Ilyen például a
HTTP_ACCEPT környezeti változó, amely azt mondja meg, hogy a kliens milyen típusú információ elfogadását jelezte a
http kérésben.
A cgi processz szabványos kimenetét figyeli a webszerver, és ami itt megjelenik azt küldi a kliensnek. Egyes webszerver
szoftverek megkívánják, hogy a cgi processz a http válasz fejlécét is előállítsa, mások ezt maguktól a visszaadott html
oldal elé teszik.
A Microsoft IIS4.0 például elfogadja, ha megadjuk a http fejlécet, de ha valamelyik szükséges rész hiányzik, például a
válasz mime típusa, akkor azt a válasz elé teszi.
- 8 -
9.
Assembled by UFO
AzApache webszerver nem viseli el, ha a cgi program által a szabványos kimenetre kiírt első sor
HTTP/1.0 200 OK
Ehelyett a
Status: 200 OK
sort kell a cgi processznek visszadnia, amelyet maga az Apache szerver értelmez, és ennek alapján állítja elő a http
válasz fejlécének első sorát. Ugyanakkor ha a státusz 200 OK akkor ezt a sort nem kell kiírnia a cgi programnak, mert
alaphelyzetben az Apache ezt feltételezi.
Webszerver konfiguráció
Ebben a fejezetben a Webszerver konfigurációjáról lesz szó. Természetesen nem célom sem az IIS, sem az Apache,
sem valamilyen más Webszerver konfigurációjának részletes leírása. Viszont tapasztalom, hogy igen gyakran merülnek
fel olyan kérdések az on-line fórumokon, amelyek a Webszerver konfigurációjára vonatkoznak, és emlékszem, hogy
magam is elsősorban ezzel szenvedtem első CGI programjaim megírásakor.
Ebben a fejezetben a Webszerver konfigurációt általánossan tekintjük át, nem túl részletesen, inkább csak a fogalmak
tisztázására, hogy ezt elolvasva az éppen alkalmazni akart Webszerver dokumentációja sokkal könyebben érthető
legyen. Mivel azonban nem sok értelme lenne egy hipotetikus Webszerver konfigurációját tárgyalni, ezért úgy döntöttem,
hogy két Webszerver szoftvert választok példának: az Apache-t, mert ezt használják a legtöbben, és az IIS-t mert ezt
ismerem a legjobban, és ez alapján tudom a fogalmakat legjobban elmagyarázni.
Megjegyzés gyakorlott cgi programozóknak:
Tudom, hogy néhány mondat ebben a fejezetben kissé pongyola. Ez direkt van így, a túlzott precizitás néhol
megzavarhatja a kezdő olvasót. Arra azért törekedtem, hogy hibás dolgot ne írjak le, legfeljebb egyszerüsítetten írok le
dolgokat. Ha úgy gondolod, hogy valamit rosszul írtam le, mindenképpen szóljál.
Ahhoz, hogy egy CGI program fusson a Webszervernek azt el kell indítani. CGI programokat nem lehet lokálisan
ellenőrizni olyan módon, mint HTML fájlokat, vagy Java, Java Script programokat. A CGI-hez Webszerver szoftver kell.
Természetesen ez a szerver lehet ugyanazon a gépen Linux, WindowsNT Workstation, vagy akár Windows95 (esetleg
szinte bármilyen más) operációs rendszer alatt, amelyik előtt a tesztelő ül. De nem lehet úgy betölteni a böngészőbe,
ahogy egy HTML vagy GIF fájlt.
A Webszerver minden egyes http kérésre egy http választ ad. Ez a válasz úgy alakul ki, hogy
1. vagy fog egy fájlt, amelyik megfelel a http kérésnek, és ennek tartalmát küldi vissza,
2. vagy ez a fájl egy program, és ezt a programot indítja el a Webszerver és amit ez a program kiír, az a
visszaküldendő információ.
A második eset a CGI program. Honnan tudja a Webszerver, hogy egy fájlt futtania kell, vagy csak egyszerűen a
tartalmát visszaküldeni. A Perl programok ugyanúgy szövegfájlok, mint a html fájlok, és a Perl fájlokat futtatnia kell a
Webszervernek, a html fájloknak pedig a tartalmát visszaadni. Fordítva pedig a GIF képek ugyanúgy binárisak, mint a
Windows/DOS alatti exe fájlok, vagy UNIX alatt a lefordított programok. Mégis a GIF fájlokat a rendszer csak egyszerűen
leküldi a böngészőnek, a futtatandó fáljokat pedig futtania kell.
A Webszerver két dologról tudhatja, hogy egy fájl futtatandó CGI. Az egyik a fájl kiterjesztése, a másik pedig az, hogy
melyik könyvtárban van, esetleg mindkettőről. A Microsoft IIS Webszerver programja grafikus felületen konfigurálható az
Internet Service Manager programmal. (Természetesen bele lehet nyúlni a registry-be is, de nem ajánlott. Néha azonban
kell, majd erről is lesz pár szó.) Ebben az anyagban az IIS3.0 webszervert vettük alapul. A szerver 4.0 verziójára a
konfigurálása lényegesen változott, sokkal több mindent lehet állítani, sokkal összetettebb, és bonyolultabb. Ezért az
IIS3.0 sokkal jobb egyszerű példának az alapfogalmak megértéséhez.
- 9 -
10.
Assembled by UFO
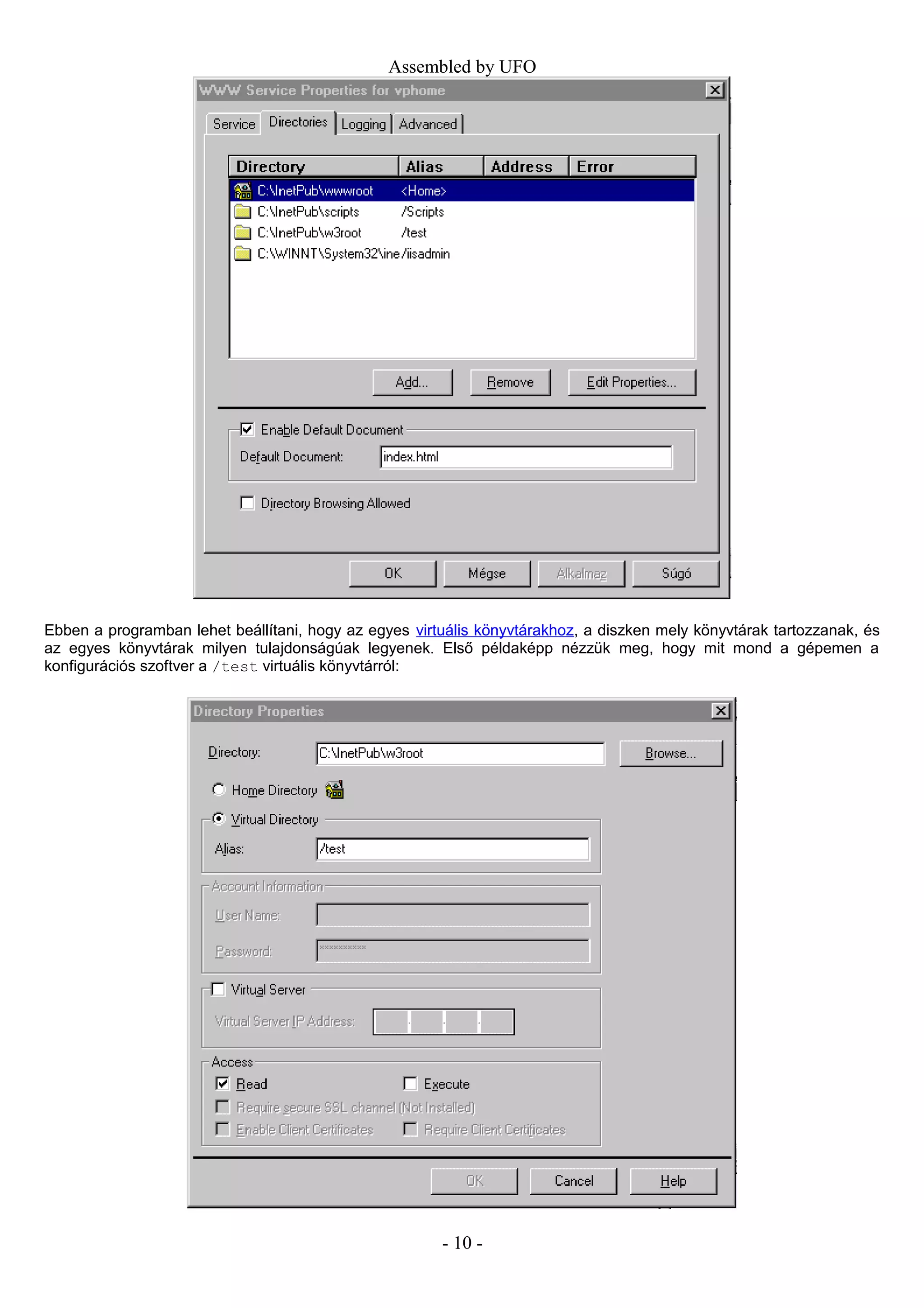
Ebbena programban lehet beállítani, hogy az egyes virtuális könyvtárakhoz, a diszken mely könyvtárak tartozzanak, és
az egyes könyvtárak milyen tulajdonságúak legyenek. Első példaképp nézzük meg, hogy mit mond a gépemen a
konfigurációs szoftver a /test virtuális könyvtárról:
- 10 -
11.
Assembled by UFO
Akönyvtárhoz rendelt könyvtár a diszken a c:InetPubw3root könyvtár, és olvasási hozzáférése van a
webszervernek, futtaási joga nincs. Ez azt jelenti, hogy minden olyan URL, amelyet a gépemen tesztelés közben úgy
kezdek, hogy http://localhost/test/ egy fájlt fog visszadni (vagy hibajelzést), de nem indít el semmilyen cgi
programot.
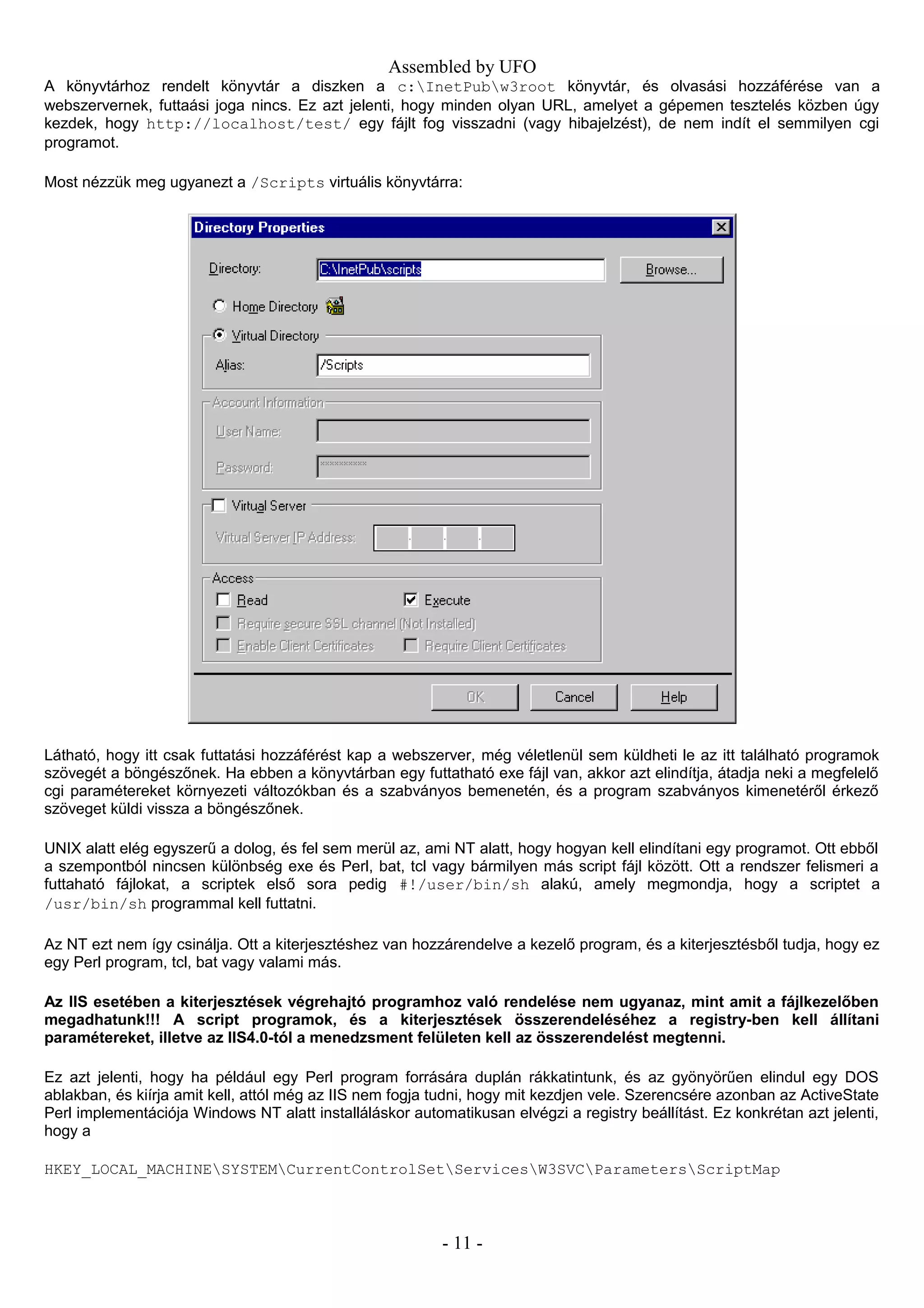
Most nézzük meg ugyanezt a /Scripts virtuális könyvtárra:
Látható, hogy itt csak futtatási hozzáférést kap a webszerver, még véletlenül sem küldheti le az itt található programok
szövegét a böngészőnek. Ha ebben a könyvtárban egy futtatható exe fájl van, akkor azt elindítja, átadja neki a megfelelő
cgi paramétereket környezeti változókban és a szabványos bemenetén, és a program szabványos kimenetéről érkező
szöveget küldi vissza a böngészőnek.
UNIX alatt elég egyszerű a dolog, és fel sem merül az, ami NT alatt, hogy hogyan kell elindítani egy programot. Ott ebből
a szempontból nincsen különbség exe és Perl, bat, tcl vagy bármilyen más script fájl között. Ott a rendszer felismeri a
futtaható fájlokat, a scriptek első sora pedig #!/user/bin/sh alakú, amely megmondja, hogy a scriptet a
/usr/bin/sh programmal kell futtatni.
Az NT ezt nem így csinálja. Ott a kiterjesztéshez van hozzárendelve a kezelő program, és a kiterjesztésből tudja, hogy ez
egy Perl program, tcl, bat vagy valami más.
Az IIS esetében a kiterjesztések végrehajtó programhoz való rendelése nem ugyanaz, mint amit a fájlkezelőben
megadhatunk!!! A script programok, és a kiterjesztések összerendeléséhez a registry-ben kell állítani
paramétereket, illetve az IIS4.0-tól a menedzsment felületen kell az összerendelést megtenni.
Ez azt jelenti, hogy ha például egy Perl program forrására duplán rákkatintunk, és az gyönyörűen elindul egy DOS
ablakban, és kiírja amit kell, attól még az IIS nem fogja tudni, hogy mit kezdjen vele. Szerencsére azonban az ActiveState
Perl implementációja Windows NT alatt installáláskor automatikusan elvégzi a registry beállítást. Ez konkrétan azt jelenti,
hogy a
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesW3SVCParametersScriptMap
- 11 -
12.
Assembled by UFO
registrykönyvtárban a .pl kulcshoz a C:PerlbinPerl.exe %s %s vagy a C:PerlbinPerlIS.dll értékek
vannak rendelve attól függően, hogy az igazi CGI Perl futtatót akarjuk-e használni a pl kiterjesztésű fájlok futtatásához,
vagy a gyorsabb, és Perl forrásszinten szintén CGI-ként működő, de új processzt nem indító ISAPI filterként
megvalósított Perl interpretert. (És természetesen feltételezve, hogy a Perl éppen a C:Perl könyvtárba lett installálva.)
Az Apache webszerver esetén a virtuális könyvtárakat illetve azt, hogy azokat letöltendő, vagy futtatandó fájlok
lelőhelyéül kell-e értelmezni a vi menedzsment szoftver segítségével lehet állítani. (bocs) A szövegszerkesztővel a
httpd.conf és fájlokat kell szerkeszteni, és a szerkesztés után a webszervert a kill -s HUP xxx paranccsal lehet
rávenni, hogy a konfigurációs fájljait újraolvassa, ahol xxx a httpd processz pid-je. Ha több ilyen is van, akkor lehet
mindegyiknek HUP-olni (sport), vagy csak a legkisebb sorszámút is elég. (azért később még részletesebben is írok az
Apache-ról.)
POST és GET paraméterek
A cgi processz környezeti változóként kapja meg a http kérés GET paramétereit, azaz azt a füzért, amelyik általában az
URL-ben a kérdőjel után áll. A szabványos bemeneten pedig megjelenik a http kérés POST paramétere, azaz az az
állomány, amely a http kérés fejléce után következik egészen a HTTP kérés végéig.
Egy URL-ben, például a http://altavizsla.matav.hu?mss=simple esetén, ami a kérdőjel után áll, az a cgi
processz GET paramétere lesz. De nem csak ez a módja a GET paraméterek előállításának. Amikor egy böngésző egy
kitöltött formot küld el a szervernek, és a form metódusa GET, akkor ez is a QUERY_STRING környezeti változóban
jelenik meg a cgi processznél. Például a
<form method=GET action="http://www.emma.hu/cgitutorial/showparam.pl">
kakukk: <input type=text name=kakukk><BR>
szarka: <input type=text name=szarka><BR>
<input type=submit value="Ezt kell megnyomni!">
</form>
kakukk:
szarka:
Ezt kell megnyomni!
form esetén, amely a
#!/usr/bin/perl
$get_parameter = $ENV{'QUERY_STRING'};
read STDIN, $post_parameter,$ENV{'CONTENT_LENGTH'};
require 'state.pl';
print_http_state('200 OK');
print <<END;
Content-type: text/html
<HTML>
<BODY>
<h1>GET és POST paraméterek</h1>
<HR>
GET paraméter:<BR>
$get_parameter
<HR>
POST paraméter:<BR>
$post_parameter
</BODY>
</HTML>
END
- 12 -
13.
Assembled by UFO
programotindítja el.
GET és POST paraméterek
GET paraméter:
kakukk=a+kakukk+egy+mad%F3r&szarka=a+szarka+is
POST paraméter:
Egy fontos dolgot már most érdemes észrevenni: a POST paramétert a szabványos bemenetről a CONTENT_LENGTH
környezeti változó által megadott hosszban olvassuk be, és nem fájlvégjelig. Fájlvége jel ugyanis nincs a
szabványos bemeneten a cgi programoknál.
A másik dolog az az, hogy a form mezőit a böngésző kódolta. Minden szóköz, és nemnyomtatható karaktert átalakított
%xx alakúra, ahol xx a karakter hexa ascii kódja. Minden szóköz helyett + jelet rakott, és az egyes paramétereket & jellel
fűzte össze. Ezen kívül még megteszi azt a szívességet is, hogy a form paraméterek neveit és a megadott értékeket
egyenlőségjellel köti össze.
Mielőtt megnéznénk, hogy hogyan kell ezeket dekódolni, nézzük meg a következő példát, amely még mindig GET
paramétereket tartalmaz, de most már legyen a form-ban action-ként megadott program neve mögött is paraméter.
<form method=GET action="http://www.emma.hu/cgitutorial/showparam.pl?birka=nem+mad%F3r">
kakukk: <input type=text name=kakukk><BR>
szarka: <input type=text name=szarka><BR>
<input type=submit value="Ezt kell megnyomni!">
</form>
kakukk:
szarka:
Ezt kell megnyomni!
A válasz nem különbözik az előző példától, azaz a böngésző, nem veszi figyelembe az URL után írt paramétereket.
Ugyanez a példa POST paraméterrel:
<form method=POST action="http://www.emma.hu/cgitutorial/showparam.pl">
kakukk: <input type=text name=kakukk><BR>
szarka: <input type=text name=szarka><BR>
<input type=submit value="Ezt kell megnyomni!">
</form>
kakukk:
szarka:
Ezt kell megnyomni!
- 13 -
14.
Assembled by UFO
GETés POST paraméterek
GET paraméter:
POST paraméter:
kakukk=mad%E1r&szarka=mad%F3r Ha most a második példának megfelelő POST pareméteres formot próbáljuk,
<form method=POST action="http://www.emma.hu/cgitutorial/showparam.pl?birka=nem+mad%F3r">
kakukk: <input type=text name=kakukk><BR>
szarka: <input type=text name=szarka><BR>
<input type=submit value="Ezt kell megnyomni!">
</form>
kakukk:
szarka:
Ezt kell megnyomni!
GET és POST paraméterek
GET paraméter:
birka=nem+mad%F3r
POST paraméter:
kakukk=mad%EDr&szarka=szint%FCn Nézzük meg, hogy hogy hogyan kell dekódolni ezeket a paramétereket.
Fejlécek kezelése
A HTTP fejlécek kezelése két esetben érdekes. Az egyik a HTTP kérés fejlécei, míg a másik a HTTP válasz fejlécei. A
HTTP kérés fejléceihez a CGI program direkt módon nem fér hozzá, azokat a Webszerver nem adja át. Ez talán érthető
is, ha arra gondolunk, hogy a HTTP fejlécben szerepelhetnek olyan információk, mint a felhasználó jelszava, amelyet a
Webszerver esetleg maga értelmez, és ellenőriz, és semmi dolga vele magának az alkalmazásnak. Azokat az
információkat, amelyeket a böngésző a http fejlécben küld el a webszervernek, és amelyekre a CGI programnak
szüksége lehet a webszerver a CGI processz környezeti változóiban helyezi el, erről azonban nem itt, hanem a
Környezeti változókban átadott paraméterek fejezetben van szó.
Jelen fejezetben azt tekintjük át, hogy milyen http fejléceket kell a CGI programnak magának előállítania, és ezeket
hogyan kell a webszerver felé elküldenie.
Alaphelyzetben a CGI programnak nem kell semmilyen fejlécet előállítania. A minimálisan szükséges fejléceket a html
szöveg elé odateszi a webszerver, elegendő, ha a CGI program magát a HTML szöveget visszaküldi.
Persze igen gyakran előfordul, gyakorlatilag az iskolapéldák után szinte azonnal az első komolyann CGI alkalmazásnál,
hogy a programozó igenis szeretne HTTP fejléceket küldeni a webszerveren keresztül a böngészőnek. A CGI erre is
teremt lehetőséget.
Megtehetjük, hogy a teljes általunk küldendő fejlécet a program a HTML kód előtt kiírja, pontosan úgy, ahogy annak a http
válaszban szerepelnie kell. Ekkor egy program, például a
#!/usr/bin/perl
require 'state.pl';
print_http_state('200 OK');
$time = time();
print <<END;
Content-type: text/html
- 14 -
15.
Assembled by UFO
<HTML>
<BODY>
$time
</BODY>
</HTML>
END
nemcsak a HTML sorokat írja ki, hanem a fejléceket is. Persze aki ismeri a HTTP szabványt annak feltűnhet, hogy az
első sor NEM http fejléc, a http szabványban nincs olyan fejlécsor, hogy Status. Valóban ez egy olyan fejlécsor, amelyet
a Webszerver értelmez, és amelyet átalakít a megfelelő HTTP/1.0 200 OK formára. Az IIS viszont nem viseli el ezt a
formát, és ha WindowsNT alatt futtatunk Perl CGI programokat, akkor a HTTP/1.0 200 OK sort kell a programnak
minden más fejlécsor előtt kiírnia. Ugyanakkor az Apache nem fogadja el, csak a Status formátumú megadást.
Szerencsére azonban még így is lehet protábilis programokat írni, mert a Webszerverek a megfelelő környezeti
változókban sok mindent elárulnak, nem csak a http kérés fejlécéről, de magukról is.
Létezik a fejlécekkel kapcsolatban az NPH fogalma is, amely a No Parsed Header angol kifejezés rövidítése, amely azt
jelenti, hogy a webszerver a CGI alkalmazás által visszaküldött http választ teljesnek tekinti, nem vizsgálja, hogy van-e
benne Status vagy bármilyen más olyan fejléc, amellyel kezdeni tud valamit, nem tesz a CGI program által generált
fejlácek elé, vagy mögé semmit, hanem leküldi egy az egyben a böngészőknek.
Az nph scriptek írására a CGI szabvány azt mondja, hogy ezek a futtatandó fájlok nph- karakterekkel kell, hogy
kezdődjenek.
Térjünk tehát rá arra, hogy milyen fejléceket érdemes a programnak a HTML szöveg előtt küldenie. Nem fogunk minden
fejlécet áttekinteni, csak a legfontosabbakat.
Content-type
A legfontosabb, és a Status után az első amit minden programnak küldenie kell, az a Content-type fejlécsor,
amelyben a böngészővel közöljük, hogy a küldendő információ, amelyik a fejlécsorok után jön, milyen MIME típusú. Ez
általában text/html de ha nem HTML szöveget küldünk vissza, csak sima szöveget akkor text/plain, de
előfordulhat, hogy egy bináris állományt küldünk vissza, ami mondjuk egy GIF kép, akkor image/gif az érték, így a
programsor, amelyik ezt az információs mint fejlécsort kinyomtatja:
print "Content-type: text/htmln";
vagy
print "Content-type: text/plainn";
vagy
print "Content-type: image/gifn";
vagy valami más a visszadott tartalomnak megfelelően. Itt kellmegjegyezni, bár nem egészen ide tartozik, hogy Perl
nyelvben mindenképpen ajánlatos a binmode használata amikor valamilyen nem ASCII fájl olvasunk vagy írunk. Igaz
ugyan, hogy UNIX alatt ez teljesen felesleges, de még egy UNIX-ra írt CGI program is elkerülhet esetleg egyszer egy
WindowsNT gépre. Akár Apache Webszerverrel együtt. Így a következő példaprogram CGI scripten keresztül küld a
felhasználónak egy GIF képet, amelyen egy kislány látható (a kép nem túl élvezetes, nem azért van):
#!/usr/bin/perl
require 'state.pl';
print_http_state('200 OK');
print <<END;
Content-type: image/gif
END
open(F,"girl.gif");
binmode F;
binmode STDOUT;
- 15 -
16.
Assembled by UFO
while(read(F,$buffer,1024) ){
print $buffer;
}
close F;
Location
Ez egy olyan fejléc, amellyel azt mondhatjuk aböngészőnek, hogy az információ, amit ő kér nem is ott van, ahol ő keresi,
hanem valahol máshol. Ilyenkor általában a Status sorban sem a 200 OK üzenetet adja vissza a program, hanem
valamilyen más hibakódot, általában a 301 Moved Permanently értéket. Ez azt jelenti a böngészőnek, hogy a kért
információ nem ott található, ahol ő keresi, hanem valahol máshol, nevezetesen a Location fejlécsorban megadott
helyen. Egy egyszerű példaként álljon itt egy kis script, amelyik a felhasználót az AltaVizsla keresőhöz küldi:
#!/usr/bin/perl
require 'state.pl';
print_http_state('301 Permanently Moved');
print <<END;
Location: http://altavizsla.matav.hu
END
Mire jó ez? Nos a leggyakrabban a hirdetési bannereket megjelenítő programok használják ezt a technikát. Amikor
megjelenik egy hirdetési kép, és valaki rákattint, akkor nem lehet azonnal a hirdető Web oldalaira küldeni, mert előtte a
hirdetést megjelenítő szolgáltató még rögzíteni akarja egy naplófájlba, hogy egy rákattintás történt, és csak ezután küldi
el a felhasználót a keresett oldalra. Például az Internetto is ezt a technikát használja. Ha valaki Apache webszervert
használ, és valamilyen oknál fogva egy weboldalba a képeket CGI scripten keresztül akarja küldeni, például azért, mert
ellenőrizni akarja, hogy aki le akarja tölteni az oldalt az kifzette-e a havi díjat és így jogosult a képek megnézésére, akkor
is használhatja ezt a technikát. Sokkal hatékonyabb lesz, mint beolvasni az egész fájlt, majd a CGI processzen keresztül
elküldeni a webszervernek, amelyik azt továbbküldi. Az Apache van annyira intelligens, hogy észreveszi, hogy a cgi script
az elérendő információ helyeként egy olyan URL-t adott meg, amelyet szintén ő kezel, és ahelyett, hogy a hibakódot
leküldené a böngészőnek, rögtön az új URL-en levő információt küldi le. Ami persze lehet kép, szöveg, hang vagy akár
egy újabb CGI script, vagy valamilyen más információ, amelyet például egy Apache modul kezel. Ha pedig nem fizetett,
akkor a visszatérési státusz kód lehet 402.
Content-Length
Ebben a fejléc mezőben adhatjuk meg, hogy milyen hosszú a visszaküldött HTML oldal, vagy egyéb információ. Ha ezt
nem teszzük meg, akkor ezt vagy megteszi helyettünk a webszerver vagy nem. Ennek ellenőrzésére kiváló kis program a
proxy.pl program. Mindenesetre ha megtesszük, akkor sokkal nagyobb biztonságban érezhetjük magunkat afelől, hogy a
böngésző rendben megejelníti a leküldött információt. Ha nincs megadva a tartalom hossza, akkor a böngésző nem lehet
egészen biztos abban, hogy az egész tartalmat megkapta-e. Ha viszont megadjuk, akkor a böngésző azt figyelembe
veszi, és például az előző példát módosítva:
#!/usr/bin/perl
require 'state.pl';
print_http_state('200 OK');
print <<END;
Content-type: image/gif
Content-Length: 1200
END
open(F,"girl.gif");
binmode F;
binmode STDOUT;
while( read(F,$buffer,1024) ){
print $buffer;
}
close F;
IE4.0 böngészőben a képnek csak egy része jelenik meg, pedig az egész képet leküldi a cgi
processz.
Az én kis proxy-m
- 16 -
17.
Assembled by UFO
Aproxy egy apró kis Perl program, amelyik nagyon buta proxy-ként viselkedik. Semmit nem vizsgál, semmit nem tárol, de
mindent továbbít mindkét irányba, és mindent kiír a konzolra.
Ugyanazon a gépen futtatható, mint a böngésző, figyel a 8080 porton (vagy egy másikon ha a forrásban valaki átírja), és
ha a böngészőn a localhost:8080 proxy beállítást alkalmaztuk, akkor a böngésző, és a szerver egymás között ezen
az alkalmazáson keresztül kommunikál. Ő pedig mindent kiír a képernyőre. Nincs több titok. Gondosan figyelve a
képernyőt sokat lehet tanulni abból, hogy a böngésző hogyan kommunikál a szerverrel. Természetesen ennek ismerete
nem szükséges a CGI programozáshoz, de nem árt. Sokkal jobb eredményeket és stabilabban működő programokat
lehet írni, ha valaki tudja, hogy pontosan mi is zajlik a háttérben.
Ha pedig valakit érdekel a hálózati programozás, amikor nem csak a Webszerver által adott felületet használjuk, hanem
magunk kezeljük az egyes portokat, nos azt hiszem, hogy ebből a kis programból sokat lehet tanulni. Ha valakinek van
kedve, akkor rögtön megvalósíthatja a program továbbfejlesztését, amelyik alkalmas remote-proxy kezelésére is.
Környezeti változók
A CGI processz szinte minden paraméterét környezeti változókon keresztül kapja meg. Ezek a változók a Perl nyelvben a
%ENV hash-ben vannak. A POST paraméterek kivételével, amelyeket a CGI processz a szabványos bemenetén (stdin)
kap meg, minden mást a környezeti változókba rak a webszerver. A legfontosabb környezeti változó a QUERY_STRING
amely a GET paramétereket tartalmazza és a REQUEST_METHOD amely azt mondja meg, hogy a kérés pontosan milyen
típusú GET, POST, esetleg PUT vagy HEADER. Hogy pontosan hogyan kell felhasználni ezeket a változókat azt külön
fejezetben tárgyaljuk részletesen, annyira fontos.
Azt, hogy milyen egyéb változókat kap meg a CGI program a legegyszerűbben egy kis CGI program lefuttatásával
tudhatjuk meg:
#!/local/bin/perl
require 'state.pl';
print_http_state('200 OK');
print <<END;
Content-type: text/html
<HTML>
<BODY>
<b>Környezeti változók</b>
<HR>
<table border=0>
END
while( ($k,$v) = each %ENV ){
print "<tr><td><b>$k</b></td><td>$v</td></tr>n";
}
print <<END;
</TABLE>
</BODY>
</HTML>
END
(Megjegyzés: Ne lepődjön meg senki, ha IIS alatt az ActiveState Perl interpretert használva nem ezt az eredményt kapja.)
Nézzük meg, hogy mit ír ki ez a program az én gépemen:
SERVER_SOFTWARE Microsoft-IIS/3.0
SERVER_PORT_SECURE 0
PROCESSOR_IDENTIFIER x86 Family 5 Model 4 Stepping 3, GenuineIntel
PROCESSOR_ARCHITECTURE x86
OS Windows_NT
GATEWAY_INTERFACE CGI/1.1
REMOTE_ADDR 127.0.0.1
SERVER_PROTOCOL HTTP/1.1
SYSTEMROOT C:WINNT
- 17 -
18.
Assembled by UFO
REQUEST_METHODGET
REMOTE_HOST 127.0.0.1
COMSPEC C:WINNTsystem32cmd.exe
HTTP_USER_AGENT Mozilla/4.0 (compatible; MSIE 4.0; Windows NT)
WINDIR C:WINNT
PATH C:Perlbin;C:WINNTsystem32;C:WINNT;
PROCESSOR_REVISION 0403
NUMBER_OF_PROCESSORS 1
HTTP_ACCEPT */*
HTTP_CONNECTION Keep-Alive
USERPROFILE C:WINNTProfilesDefault User
COMPUTERNAME VPHOME
HTTP_ACCEPT_LANGUAGE hu
SCRIPT_NAME /cgitutorial/listenv.plx
HTTP_ACCEPT_ENCODING gzip, deflate
SERVER_NAME localhost
PROCESSOR_LEVEL 5
OS2LIBPATH C:WINNTsystem32os2dll;
PATH_INFO /cgitutorial/listenv.plx
SERVER_PORT 80
CONTENT_LENGTH 0
HTTP_HOST localhost
PATH_TRANSLATED C:InetPubwwwrootcgitutsourcecgi-binlistenv.plx
SYSTEMDRIVE C:
Mivel ez a gép nincs az Internetre kötve azért meg merem mutatni ezeket a paramétereket, bár meglehetősen sokat
megmutat. Csak azokon a változókon megyünk végig, amelyek általában minden webszerveren használhatóak, és
amelyeket a portabilitás elvesztése nélkül bátran lehet használni. (Vagy esetleg éppen a portabilitás elérése érdekében.)
SERVER_SOFTWARE
A webszerver szoftver megnevezése és verziója. Ezt péládul alkalmazni lehet ahhoz, hogy kikerüljünk néhány
rendszerspecifikus különbséget. Ilyen például az, hogy az IIS nem fogadja el a Status sort, hanem helyette a HTTP/1.0
karaktersorozatot kell kiküldeni. Ehhez a státusz kiírásához használhatjuk a kis apró state.pl programot
sub print_http_state
{
my $state = shift;
if( $ENV{'SERVER_SOFTWARE'} =~ /IIS/ )
{
print "HTTP/1.0 $staten"
}
else
{
print "Status: $staten"
}
}
1;
(Ezt önnmagában nincs értelme lefuttatni még akkor sem, ha a jamal makró iderakja a futtatáshoz szükséges linket.)
OS
Az operációs rendszer neve, amelyiket a Webszerver használ. Előfordulhatnak olyan kód darabok, amelyek másként
funkcionálnak a különböző operációs rendszereken, illetve más kódot kell használni ugyanazon funkcionalitás elérése
érdekében. Ezeknél a scripteknél figyelembe kell venni ennek a környezeti változónak az értékét.
GATEWAY_INTERFACE
A webszerver szoftver és aprogram közötti felület neve és verziója. Ez szinte mindig CGI/1.1
REMOTE_ADDR
A kliens gép IP címe. Ez a cím persze lehet, hogy nem a kliens címe, hanem a proxy gép címe, amit a kliens használt.
- 18 -
19.
Assembled by UFO
Amennyibenpedig a kliens és a szerver között több proxy-n is keresztül megy a http folyam, akkor annak a proxy-nak a
címe amelyik a sorban a legutolsó, és a szerverhez a "legközelebb" van.
Nem lehet feltételezni, hogy egy IP címről csupán egy felhasználó jön, csak különleges esetben. Ilyen lehet az, amikor
tudjuk, hogy az alkalmazást csak egy LAN-on belül fogják használni.
SERVER_PROTOCOL
Az a protokoll, amelyet a szerver használ. A HTTP/1.0 és a HTTP/1.1 között lényegi különbség nincsen, csak
egyészen kis apróságokban, főleg a proxy és a proxy cache kezelésében.
REQUEST_METHOD
Ez egy nagyon fontos környezeti változó. Ez a változó mondja meg, hogy a HTTP kérés típusa milyen. Ez általában GET
vagy POST. Ennek bővebb használatáról külön fejezetben részletesen írunk.
REMOTE_HOST
A kliens gép neve. Általában nem lehet számítani rá, hogy ez a változó rendesen rendelkezésre áll. Amikor egy gépnek
nincs neve, csak ip száma, vagy a webszerver teljesítmény okok miatt nem határozza meg a kliens tcp/ip nevét, akkor ez
a változó vagy üres, vagy általában az IP számot tartalmazza.
HTTP_USER_AGENT
A böngésző típusa. Akkor érdemes használni, ha olyan a program válasza, amely a különböző böngészők számára
különböző választ ad. Ilyen lehet például a frame használat.
HTTP_ACCEPT
Azoknak a MIME típusoknak a felsorolása, amelyeket a böngésző elfogad. Ha más típusú információt adunk vissza,
akkor feltehetőleg a böngésző nem fog tudni mit kezdeni vele. Egy lynx például ebben a http fejlécben a text/*
információt küldheti, aminek megfelelően a gif képek helyett a program küldhet alternatív szöveget.
HTTP_ACCEPT_LANGUAGE
Azoknak a nyelveknek a listája, amelyeket a böngésző tulajdonosa beállított, hogy elfogad, el tud olvasni. A program erre
figyelhet, és amennyiben az információ, amelyet előállít több nyelven is elérhető, akkor a legmegfelelőbbet választhatja
ki.
SCRIPT_NAME
Ez egy nagyon fontos környezeti változó. Eleinte ugyannem használja az ember, de bonyolultabb programok írásánűl
igen gyakran előfordul, hogy olyan HTML fájlt jelenít meg a program, amelynek bizponyos funkcióit követve újra ugyanaz
a script indul el. Például egy form kitöltése után ha az nincs teljesen kitöltve, akkor egy olyan oldalt jelenít meg a program,
amely figyelmeztet a hiányosságokra, és tartalmazza a form-ot a már beírt információkkal. Természetesen ilyen esetben
hivatkozni lehet a script nevére, de mi történik akkor, ha valaki átnevezi a programot, és így akarja használni? Sokkal
biztonságosabb, ha ezta környezeti változót használjuk. Persze munkásabb is. De nem vészes:
#!/usr/bin/perl
require 'state.pl';
&print_http_state('200 OK');
$url = 'http://' .
$ENV{'SERVER_NAME'} .
$ENV{'SCRIPT_NAME'};
print <<END;
Content-type: text/html
<HTML>
<BODY>
Én <A HREF="$url">$url</A> vagyok.
</BODY>
</HTML>
END
- 19 -
20.
Assembled by UFO
SERVER_NAME
Aszervergép neve. Ez is fontos lehet, ha a saját script teljes URL-jét akarjuk összeállítani.
PATH_INFO
SERVER_PORT
Annak a portnak a száma, ahol a szerver figyel.
CONTENT_LENGTH
Ez az információ akkor érdekes, ha POST típusú http kérést kell feldolgoznia a cgi scriptnek. Ez a változó tartalmazza a
http kérés tartalmának a hosszát. Ezt mindenképpen tudni kell, mert csak innen lehettudni, hogy mikor van vége a http
kérésnek. A http protokoll ugyanis nem zárja le a http kérés végén a csatornát egy fájlvégjellel. Végülis ez teszi lehetővé
azt, hogy a http továbbfejlesztésében meg tudták valósítani a keep-alive fogalmat.
HTTP_HOST
PATH_TRANSLATED
Megadja annak a könyvtárnak a helyét ahol a script valóban van.
- 20 -