


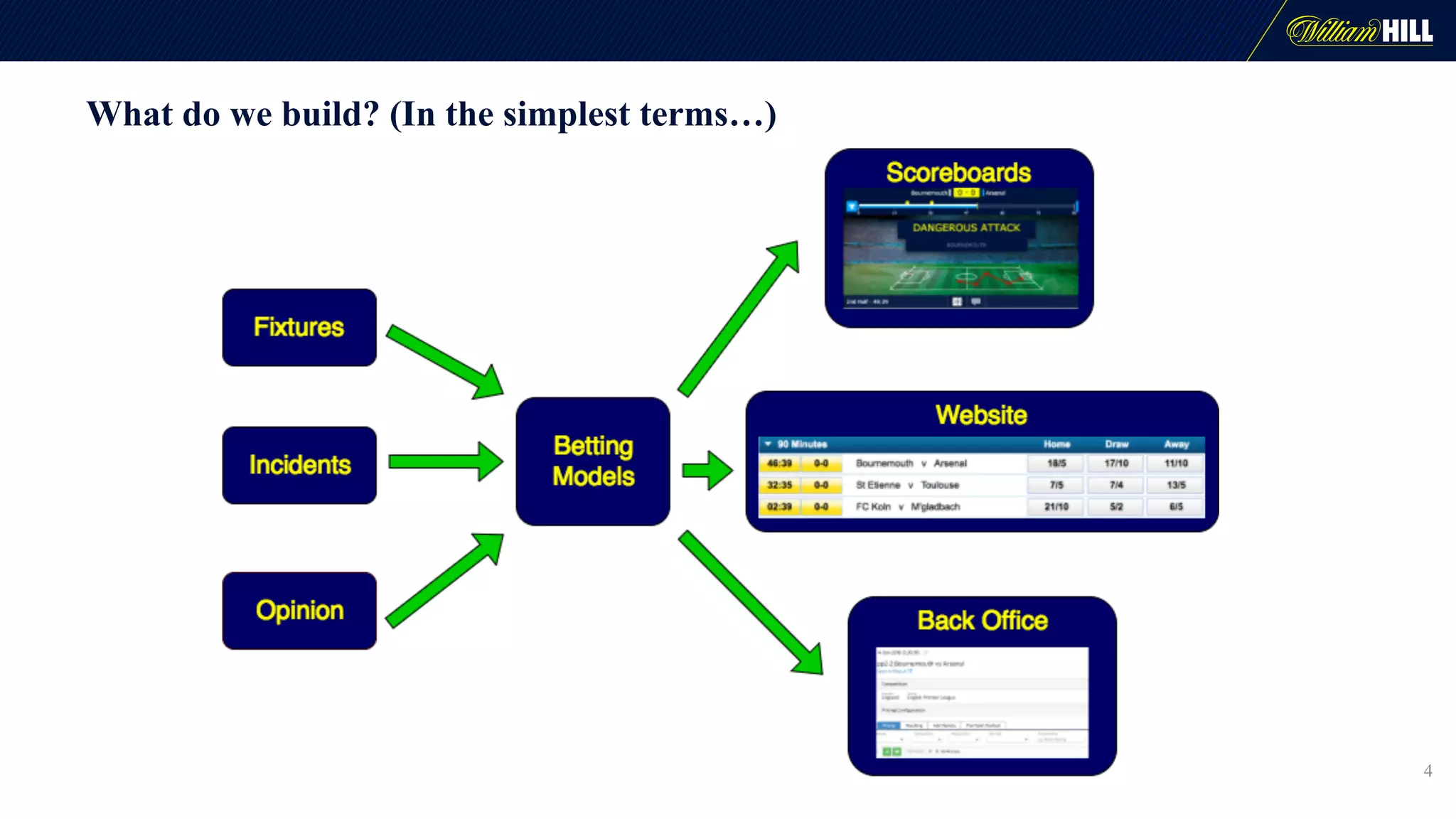
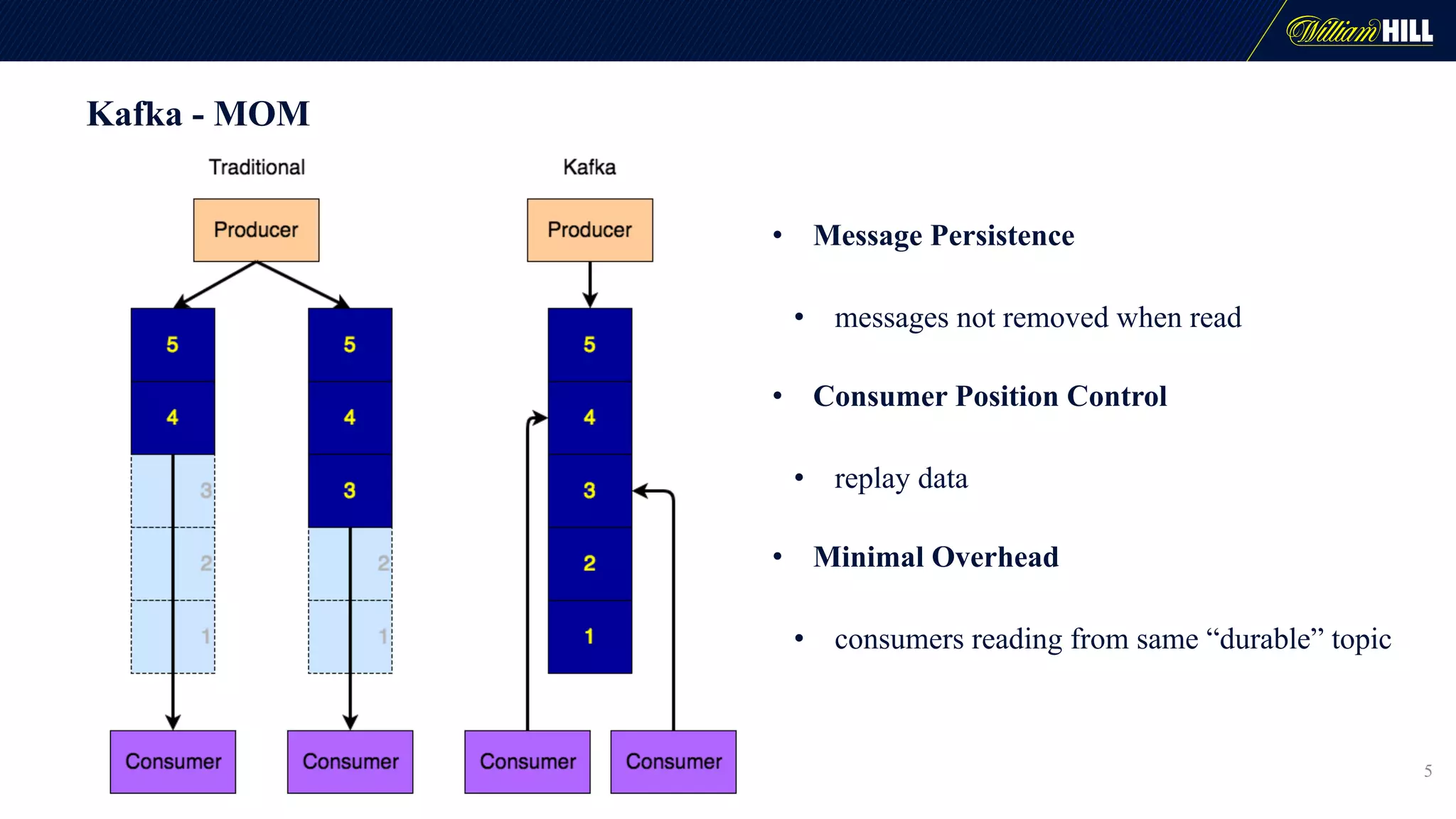
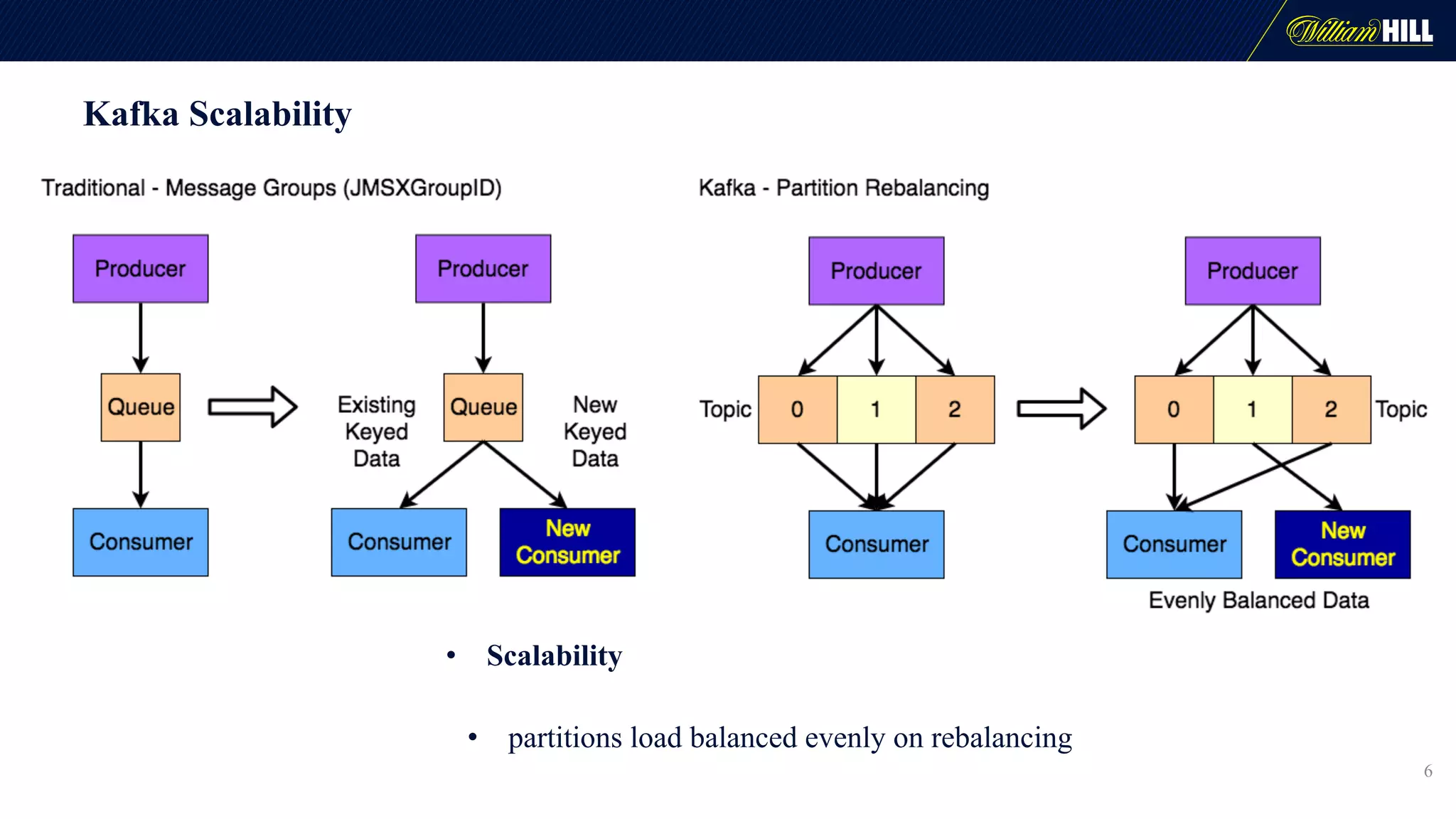
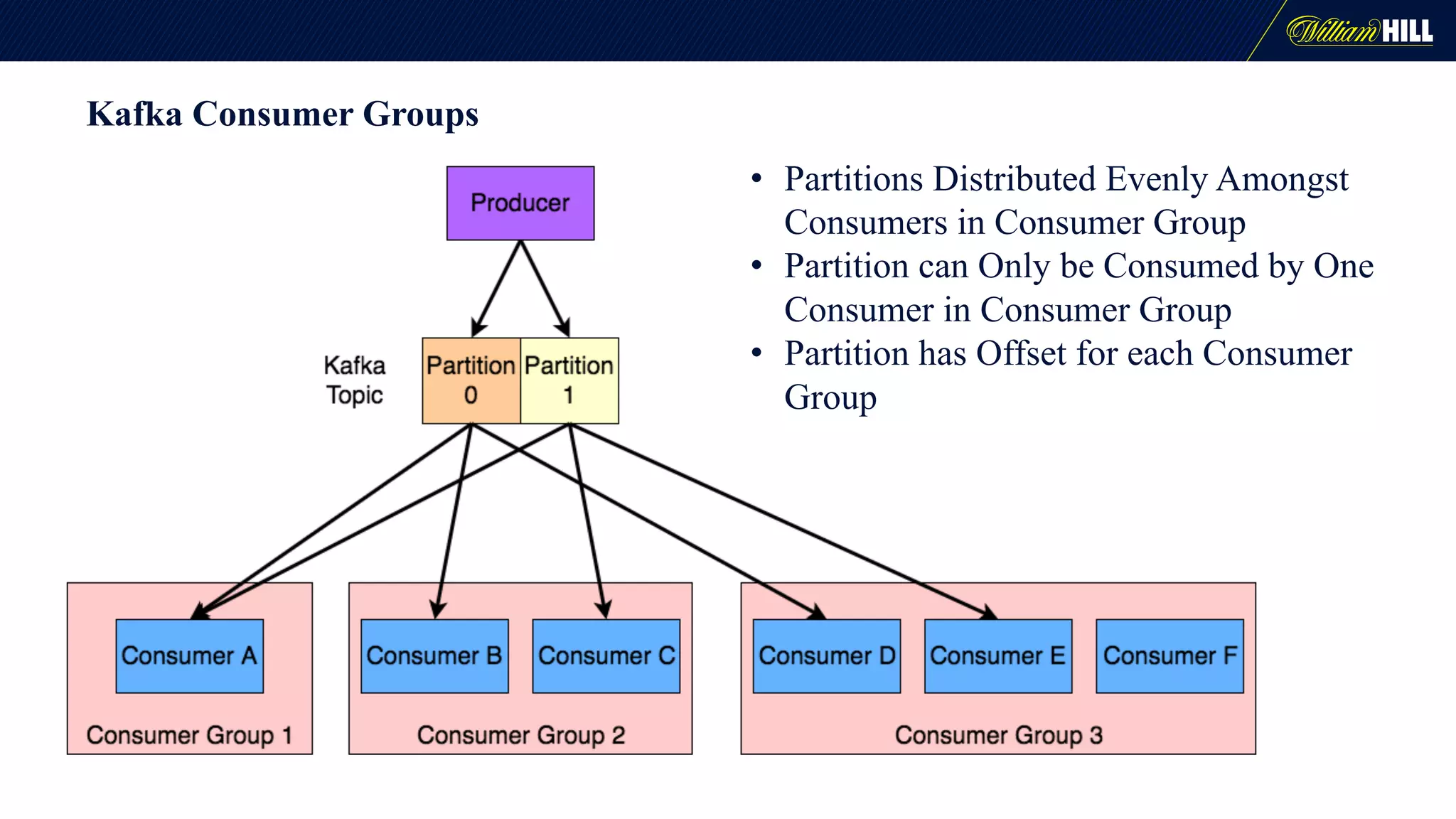
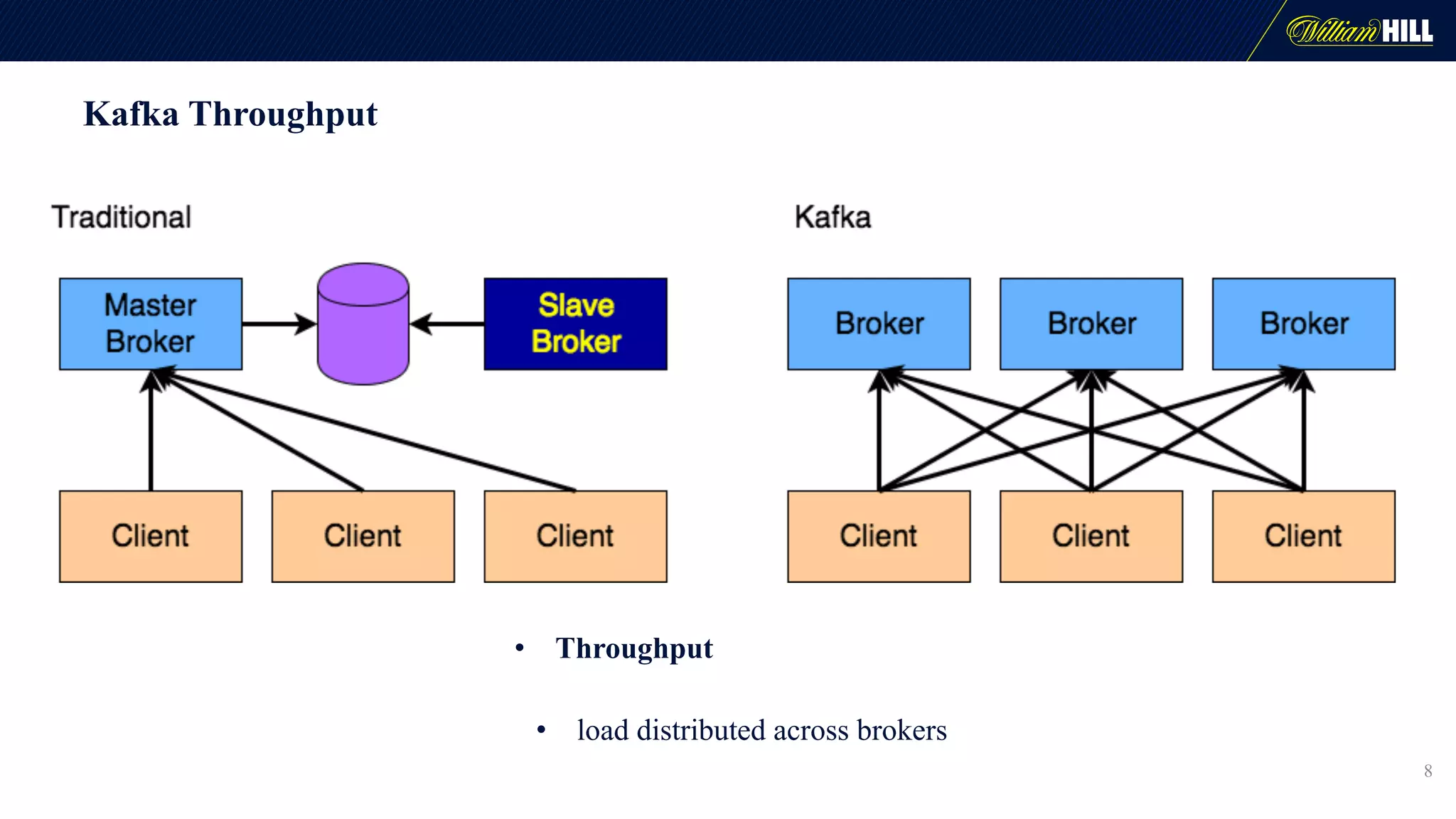

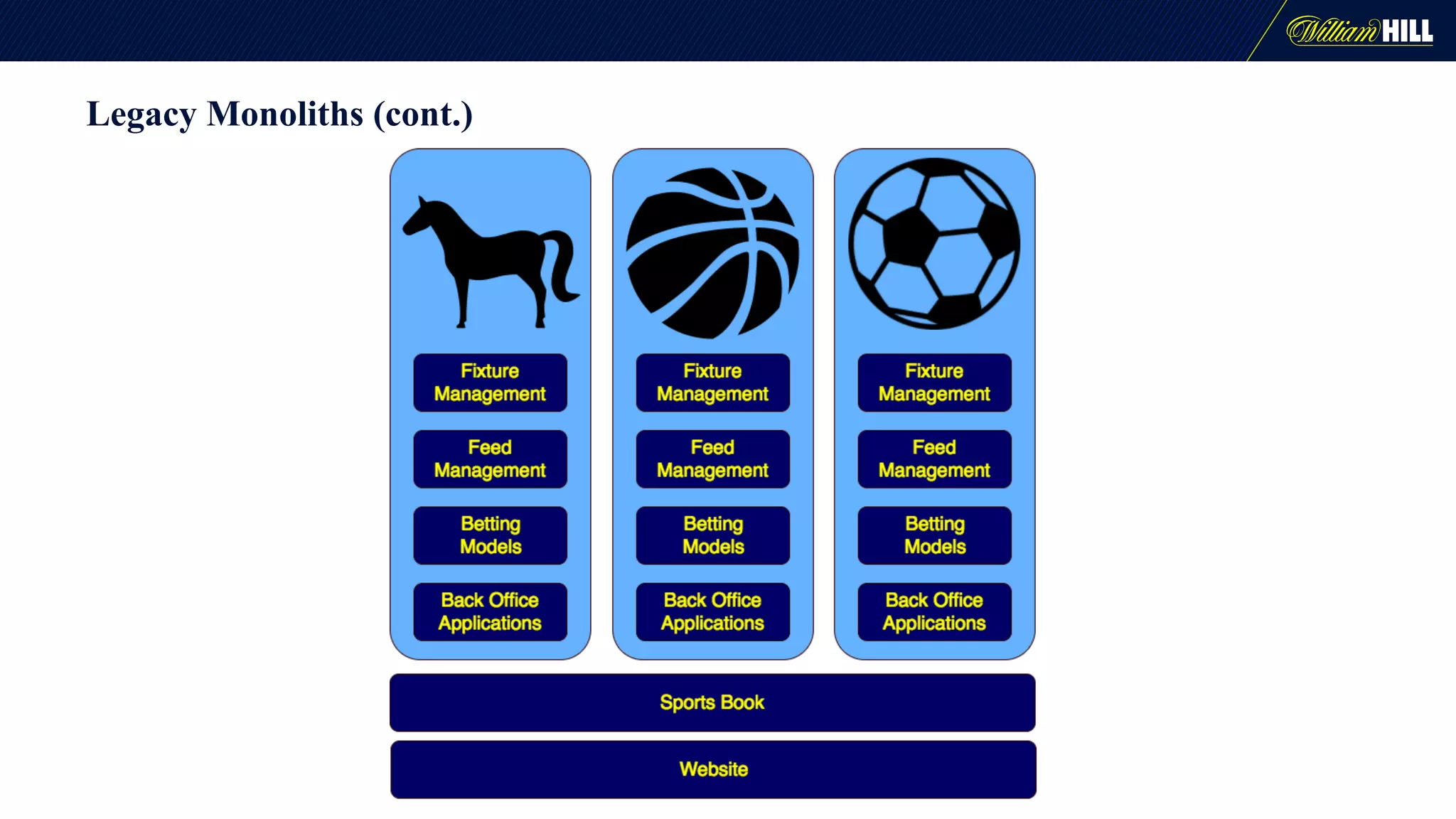



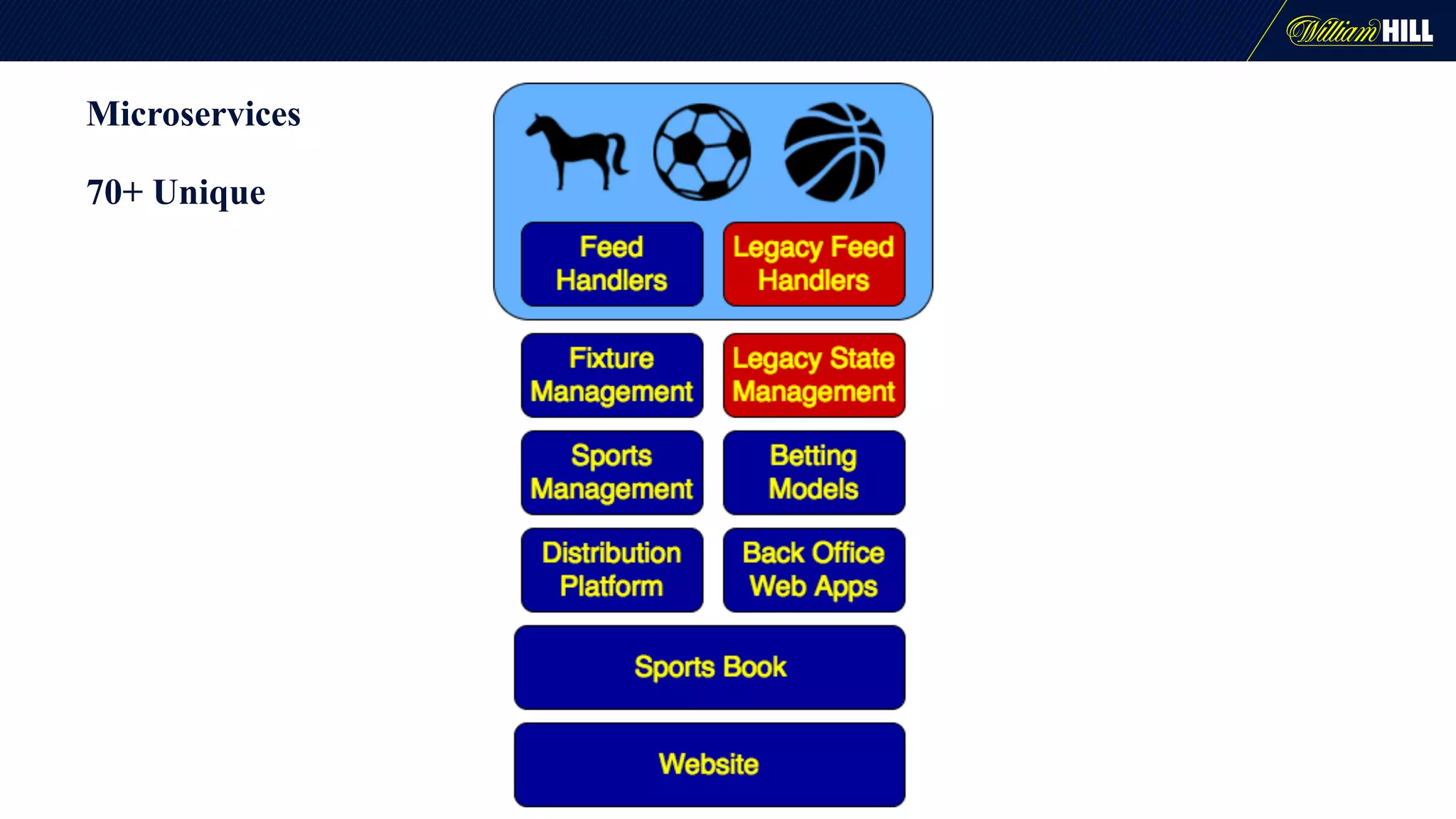












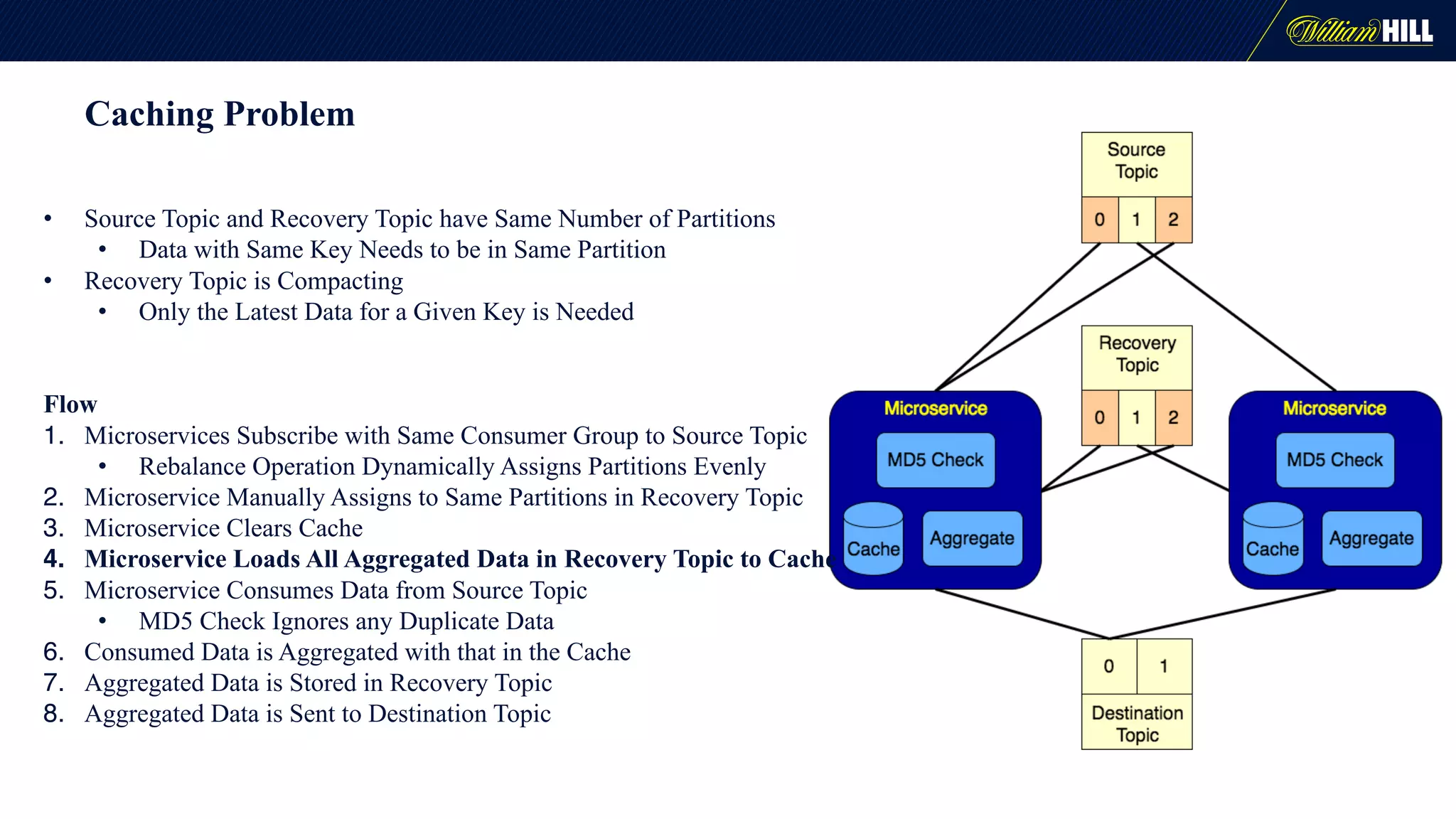

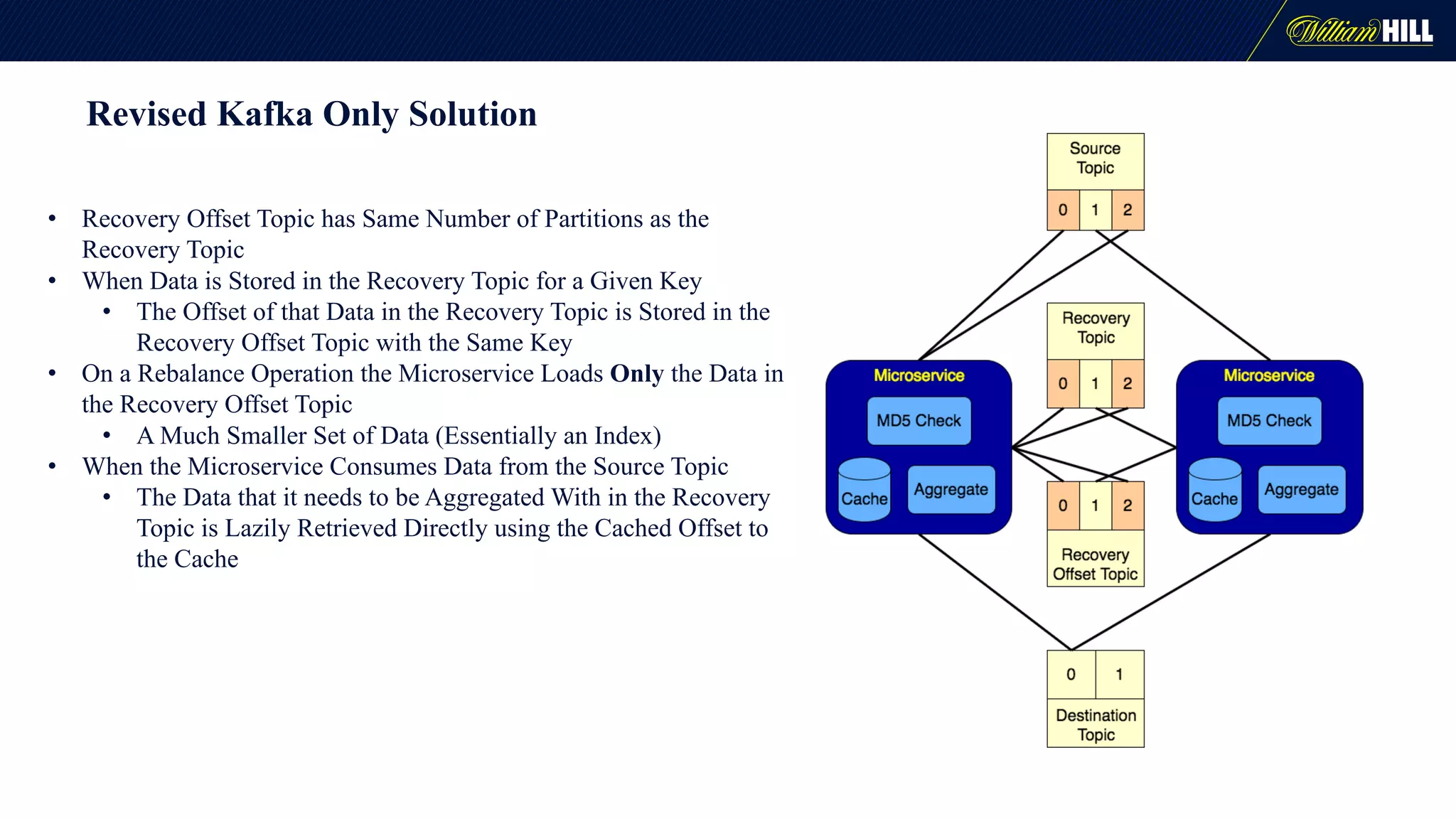
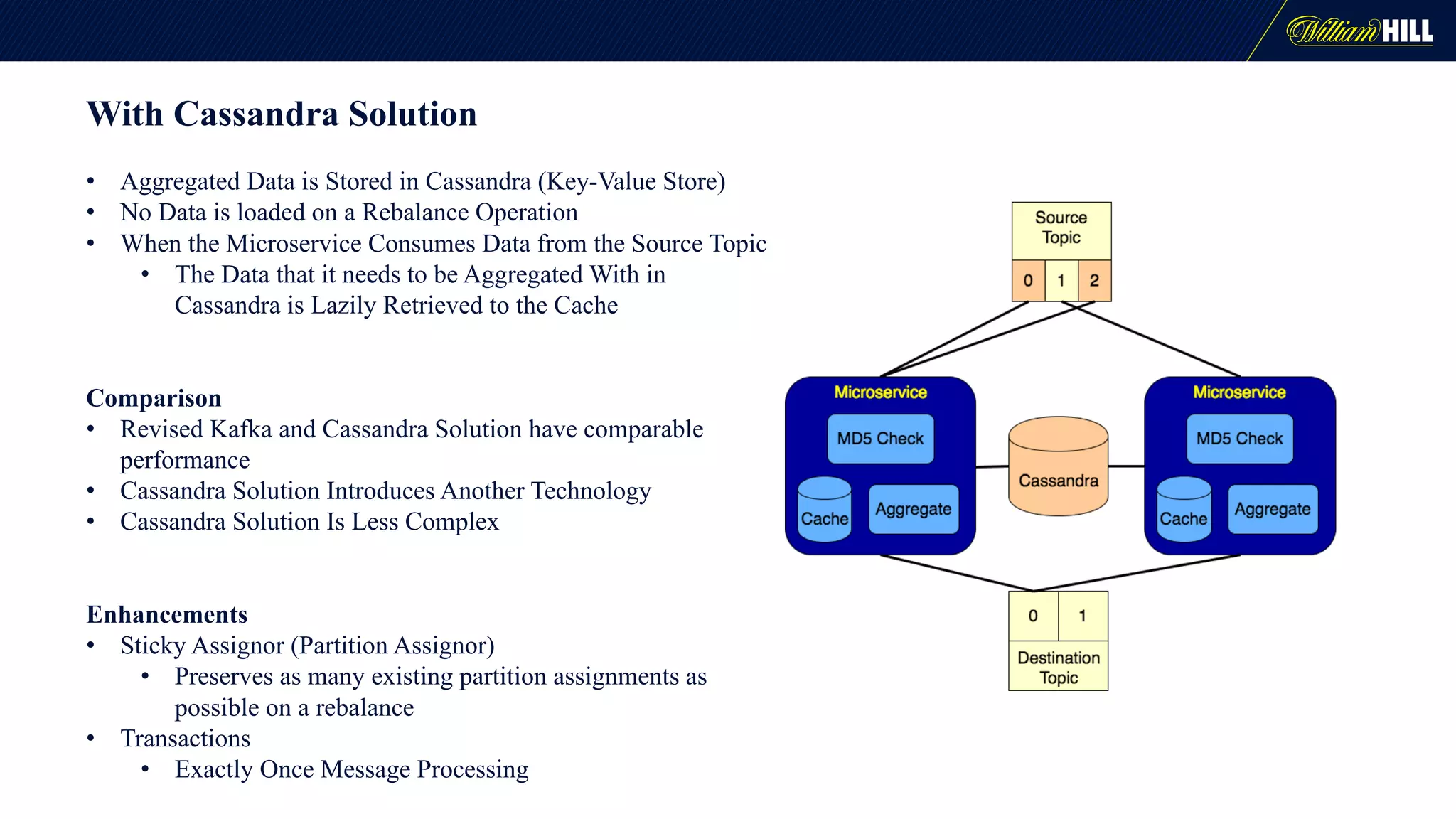







The document details the journey of William Hill's trading department as they developed a real-time data pipeline using Apache Kafka, sharing lessons learned and challenges faced during the implementation. It highlights the architectural considerations, testing strategies, and operational management required to effectively utilize Kafka for scalable messaging systems. Key insights include the need for careful message formatting, integration testing difficulties, and the importance of understanding specific use cases for optimizing Kafka's performance.







![[오픈소스컨설팅]Java Performance Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/javaperformanetuning-150408192031-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































































