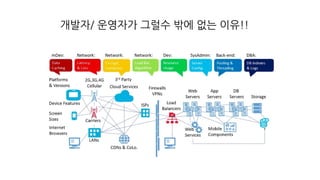
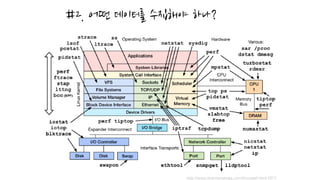
클라우드 환경에서 수집해야되는 대표적인 지표 몇개.
§ IOPS
§ Disk Queue Length (win) / iowait (linux)
§ CPU Steal Time 등..
§ http://bencane.com/2012/08/06/troubleshooting-high-
io-wait-in-linux/
15.
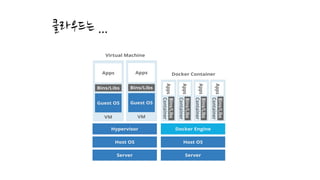
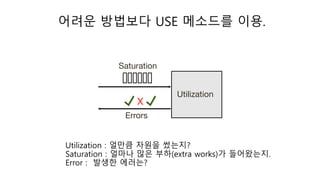
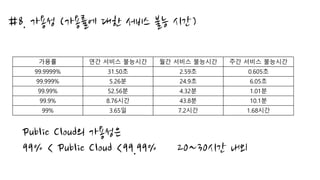
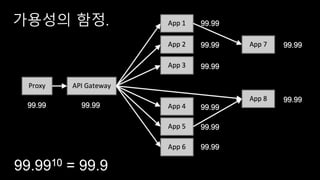
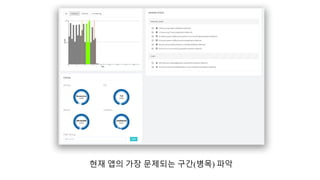
클라우드 에서의 성능측정이 어려운 이유..
첫째, 일부 부분은 우리가 통제할 수 없다.
우리는 클라우드 솔루션을 평가하고 벤치마킹할 수 있지만
어딘가 예측할 수 없는 공유 시스템을 제공 받을 뿐이다.
우리가 모든 환경을 통제할 수 없으니 정확하게 느려지거나
단절 되는 이유를 알아내기 매우 힘들다.
Sasha Goldshtein
Velocity 컨퍼런스 : Linux Performance : Tracing the Cloud
https://www.oreilly.com/ideas/linux-performance-tracing-the-cloud
16.
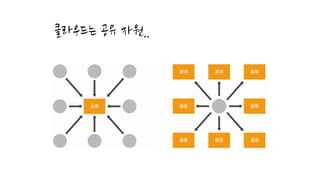
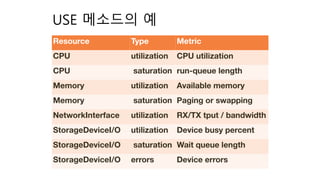
클라우드 에서의 성능측정..
둘째, 일부 성능 측정 도구는
작은 실험실 규모에서만 효과가 측정되어 클라우드 규모에서는 동작하지 않는다.
점점 큰 규모의 시스템에서 배포하는 것이 쉬워지면서,
운영 대시보드와 경보기를 엄청나게 설치하지 않는다면
작은 오버헤드와 이용할 수 있는 성능 정보를 얻는 것은 어려워지고 있다.
많은 수의 서버에서 발생하는 문제를 추적 할 수 있는 능력은 더더욱 중요시 되고 있다.
Sasha Goldshtein
Velocity 컨퍼런스 : Linux Performance : Tracing the Cloud
https://www.oreilly.com/ideas/linux-performance-tracing-the-cloud
주의할 점 MemFreevs MemoryAvailable.
cat /proc/meminfo
MemFree보다
MemAvailable을 이용하세요.
Ubuntu 14.04이상
MemFree:
The amount of physical RAM, in kilobytes,
left unused by the system.
MemAvailable:
An estimate of how much memory is available
for starting new application
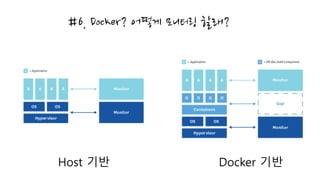
#5. 운영시 최소한챙겨야 하는 이벤트 (윈도우)
윈도우 EventID 윈도우 비스타 EventID 이벤트 타입 설명
512, 513, 514, 515, 516,
518, 519, 520
4608, 4609, 4610, 4611, 4
612, 4614, 4615, 4616
System Events Identifies local system processes such as system startup and shutdown and changes to the system time
517 4612 Audit Logs Cleared Identifies all the audit logs clearing events
528, 540 4624 Successful User Logons Identifies all the user logon events
529, 530, 531, 532, 533,
534, 535, 536, 537, 539
4625 Logon Failures Identifies all the failed user logon events
538 4634 Successful User Logoff Identifies all the user logoff events
560, 563, 565, 566
4656, 4658, 4659, 4660, 4
661, 4662, 4663, 4664, 51
47
Object Access
Identifies when a given object (File, Directory, etc.) is accessed, the type of access (e.g. read, write, del
ete) and whether or not access was successful/failed, and who performed the action
612 4719 Audit Policy Changes Identifies all the changes done in the audit policy
624, 625, 626, 627, 628,
629, 630, 642, 644
4720, 4722, 4723, 4724, 4
725, 4726, 4738, 4740
User Account Changes
Identifies all the changes done on an user account like user account creation,deletion, password change
, etc.
(631 to 641) and (643, 6
45 to 666)
4727 to 4737, 4739 to 476
2
User Group Changes
Identifies all the changes done on an user group such as adding or removing a global or local group, ad
ding or removing members from a global or local group, etc.
672, 680 4768, 4776 Successful User Account Validation
Identifies successful user account logon events, which are generated when a domain user account is au
thenticated on a domain controller
675, 681 4771, 4777 Failed User Account Validation
Identifies unsuccessful user account logon events, which are generated when a domain user account is
authenticated on a domain controller
682, 683 4778, 4779 Device Session Status Identifies the session re-connection or disconnection
27.
운영시 최소 한챙겨야 하는 syslog (리눅스)
/var/log/messages : General message and system related stuff
/var/log/auth.log : Authenication logs
/var/log/kern.log : Kernel logs
/var/log/cron.log : Crond logs (cron job)
/var/log/maillog : Mail server logs
/var/log/qmail/ : Qmail log directory (more files inside this directory)
/var/log/httpd/ : Apache access and error logs directory
/var/log/lighttpd/ : Lighttpd access and error logs directory
/var/log/boot.log : System boot log
/var/log/mysqld.log : MySQL database server log file
/var/log/secure or /var/log/auth.log : Authentication log
/var/log/utmp or /var/log/wtmp : Login records file
/var/log/yum.log : Yum command log file.
추가 정보는 http://bit.ly/2ujaNJm 를 참고
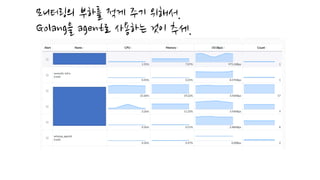
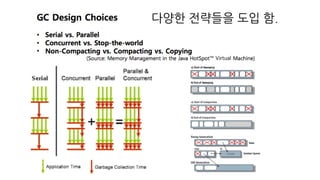
개발 편의성/ 관리를위해 직접 메모리를 관리하고 싶지만..
Java에서는
C, C++에서 사용하는 ‘free’, ‘delete’가 없기 때문에
주기적으로 혹은 특정 조건일 때 GC를 하게 됩니다.
이로인해 프로그래머는 메모리 관리에 대해서 고민을 적게 할 수 있습니다.
하지만 임베디드 환경에서는 메모리 하나 하나가 매우 소중합니다.
기본적으로 할당하는 방식은
StrongReference 입니다.
Strong
- 기본적으로 할당하는 방식을 Strong Reference 라고 부릅니다.
mLauncher = new <Launcher>(launcher);
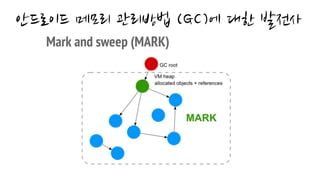
- GC과정에서 연결된 객체들을 Mark하고 Mark되지 않은 객체들을 Sweep합니다.
48.
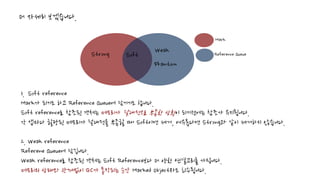
Strong 이외에 3가지가더 있습니다.
1. 종류
Soft reference, Weak reference, Phantom reference
Private WeakReference<Launcher> mLauncher;
mLauncher = new WeakReference<Launcher>(launcher);
2. 원리
- GC동작에서 Strong이 아닌 경우 Mark하지 않고
Reference Queue라는 공간에 객체를 넣고,
Sweep하는 과정에서 제거 Queue에 있는 객체들을 제거 합니다.
49.
더 자세히 보겠습니다.
1.Soft reference
Mark가 되기도 하고 Reference Queue에 담기기도 합니다.
Soft reference로 참조된 객체는 메모리가 절대적으로 부족한 상황이 되기전에는 참조가 유지됩니다.
각 앱마다 할당된 메모리가 절대적을 부족할 때 Soft이면 제거, 여유롭다면 Strong과 같이 제거하지 않습니다.
2. Weak reference
Referene Queue에 담깁니다.
Weak reference로 참조된 객체는 Soft Reference보다 더 약한 연결고리를 가집니다.
메모리의 상태와 관계없이 GC가 동작되는 순간 Marked Object라도 회수됩니다.
Strong Soft
Weak
Phantom
Mark
Reference Queue
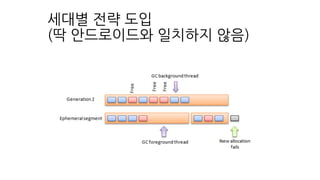
Rosalloc 이란
(Runs ofSlots Allocator)
작은 객체들을 위한
thread local storage를 만들자.
Bulk free를 위하여.
작은 객체를 할당하는 영역과
큰 객체를 할당하는 영역을 구분하자
하나의 영역에 객체를 할당하니,
GC가 빈번하게 발생해서,
역할을 나누자!
추가적인 기교들을 더함.
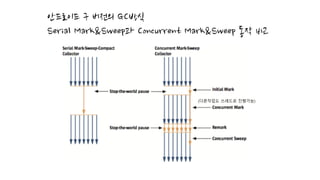
•Dalvik이 두번 Pause(mark remark) 해서 객체 mark-sweep 함
• ART에서는 한번 pause(mark를 병렬로 진행 remark에서만 멈춤).
• 그래도 mark-sweep은 느리니 병렬로 해서 빠르게 정리하자.
• 최근 생성(sticky)하거나, 짧은 수명의 객체는 빨리 제거하자.
• 메모리가 부족해 GC를 돌리면 OOM이 날수 있으니, 더 낮은 상한성 (GC Timelier) 만들
어서 돌리자.
56.
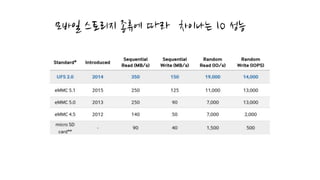
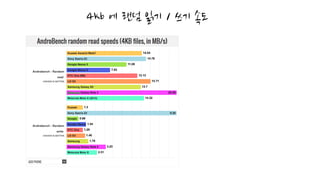
CPU, UI Rendering은추후 시간이 되면..
우리가 간과하는 큰 부분이 있습니다.
심지어 프로파일러 마저도.. 없는 영역??
I/O


















































![[133] 브라우저는 vsync를 어떻게 활용하고 있을까](https://cdn.slidesharecdn.com/ss_thumbnails/133vsync-150914020334-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[121]네이버 효과툰 구현 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/121-150914011346-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[111] 네이버효과툰어떻게만들어졌나](https://cdn.slidesharecdn.com/ss_thumbnails/111-150913113917-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[145]5년간의네이버웹엔진개발삽질기그리고 김효](https://cdn.slidesharecdn.com/ss_thumbnails/1455-161023163929-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC10] Unity Build 로 빌드타임 반토막내기 - 송창규](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2010-unitybuild-130427234602-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC 2016] 유니티코리아 오지현 - “뭣이 중헌디? 성능 프로파일링도 모름서”: 유니티 성능 프로파일링 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/6-161009024341-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC 2017] 오토데스크 박준석 - 3ds Max 2018과 Shotgun을 이용한 게임 제작 Pipeline 소개](https://cdn.slidesharecdn.com/ss_thumbnails/gameassetworkflowautodesk-170905075140-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC12] 변화량 분석을 중심으로 한 저비용 고효율의 지속가능한 코드퀄리티 관리법 - 송창규](https://cdn.slidesharecdn.com/ss_thumbnails/final-110606220457-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 2014] 던전앤파이터 클라이언트 로딩 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/ndc201420140605-140604221309-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[C5]deview 2012 nodejs](https://cdn.slidesharecdn.com/ss_thumbnails/c5deview2012nodejs-120920013859-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC 2017] 엔지메이킹 이대희 - 이제는 웹에서 게임을 만들 수 있는 환경 'Construct3를 바탕으로'](https://cdn.slidesharecdn.com/ss_thumbnails/igc-170905073407-thumbnail.jpg?width=640&height=640&fit=bounds)

![[124] 하이브리드 앱 개발기 김한솔](https://cdn.slidesharecdn.com/ss_thumbnails/124-161023163714-thumbnail.jpg?width=640&height=640&fit=bounds)












![[MGDC] 리눅스 게임 서버 성능 분석하기 - 아이펀팩토리 김진욱 CTO](https://cdn.slidesharecdn.com/ss_thumbnails/mgdcifunfactoryjinukkim-181018053904-thumbnail.jpg?width=640&height=640&fit=bounds)








![[오픈소스컨설팅]파일럿진행예제 on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/osconaws-151026093255-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)












![[NEXT] Android Profiler 사용법](https://cdn.slidesharecdn.com/ss_thumbnails/day6profiler150810-150811041218-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NEXT] Flask 로 Restful API 서버 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/flask2-141209115126-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NEXT] GCM을 이용한 게시글 자동 갱신](https://cdn.slidesharecdn.com/ss_thumbnails/day10gcm-141209112851-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NEXT] Andorid에 MVC 패턴 적용하기](https://cdn.slidesharecdn.com/ss_thumbnails/day9mvc-141209112818-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NEXT] 화면 재갱신이 되는 안드로이드 앱 만들기 - 네트워크에 독립하는 구조로 변경](https://cdn.slidesharecdn.com/ss_thumbnails/day8networkaloneapp-141209112528-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NEXT] Nextgram Refactoring](https://cdn.slidesharecdn.com/ss_thumbnails/android-day7refactoring-140818221826-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)