Download as PDF, PPTX






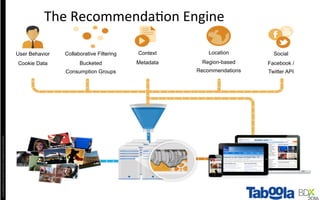
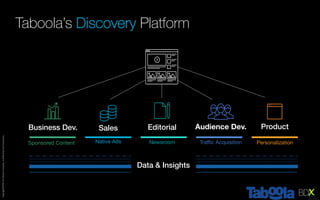
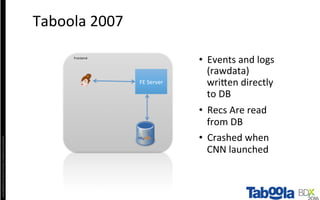
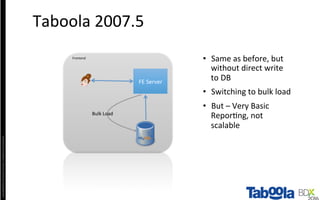
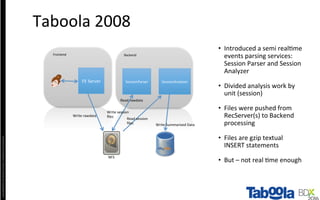
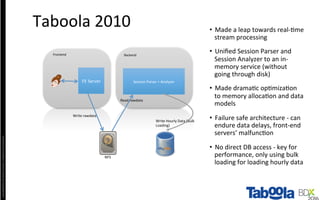
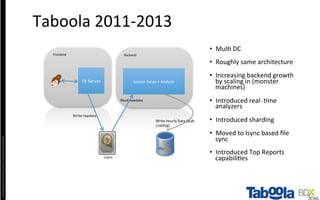


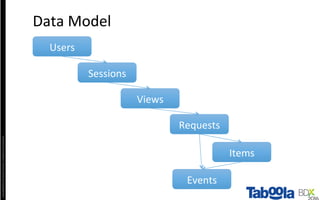


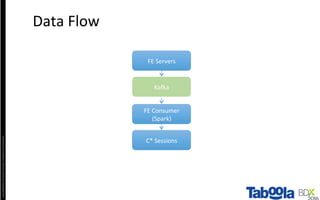

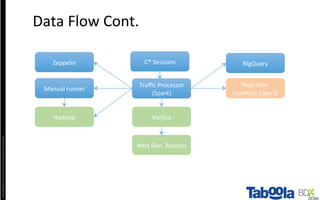




The document discusses Taboola's data infrastructure and how it has evolved over time. Some key points: - Taboola processes large amounts of data (5+ TB daily) from 750M monthly users to power recommendations. - Earlier systems struggled to handle the scale and lacked analytics capabilities. The current system uses Apache Spark and Cassandra for real-time and historical data processing and analytics. - Data flows from servers into Apache Spark for joining and analysis, then into Cassandra for querying and Hadoop for long-term storage. This allows real-time and historical access and analytics across petabytes of user behavior data.



















