Download as PDF, PPTX




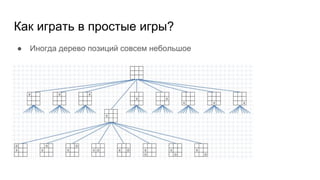
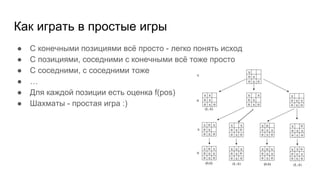





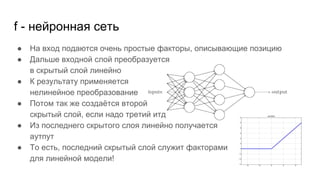


Автор делится своим опытом игры в нарды и описывает методы оценки игровых позиций с использованием вероятностей. Брошюра также затрагивает использование линейных функций и нейронных сетей для улучшения стратегии игры. В заключение, планируется создать визуализацию игры и провести турнир.






















