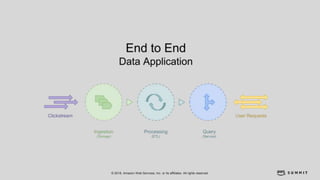
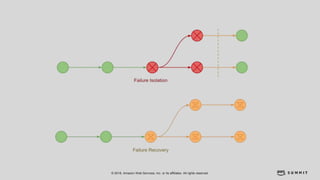
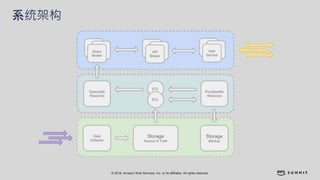
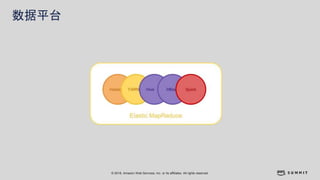
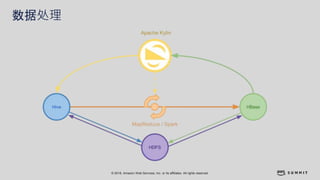
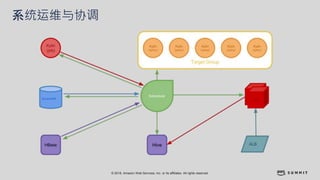
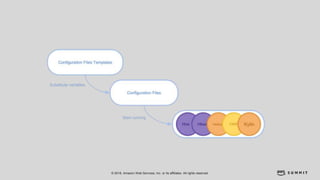
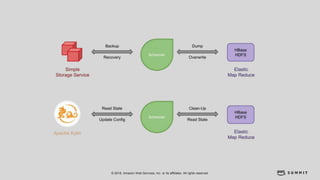
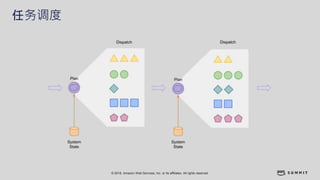
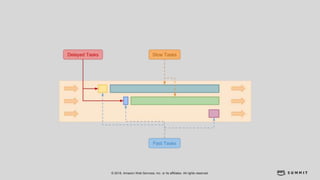
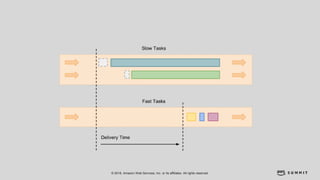
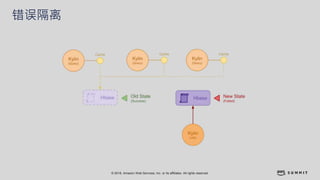
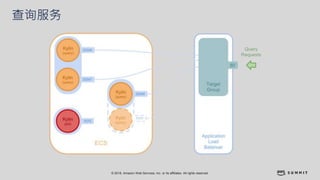
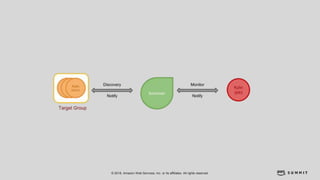
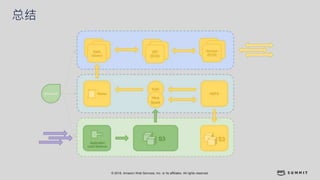
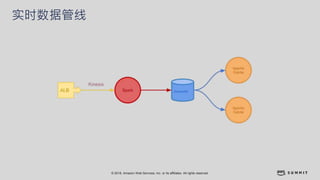
文档介绍了 Strikingly 如何利用 AWS 和 Apache Kylin 提供高效的大数据分析和建站服务。该公司自2012年成立以来,服务全球数百万用户,通过实时数据管道与多维分析支持商业智能决策。挑战包括确保系统稳定、数据处理的灵活性及运维的可定制性。