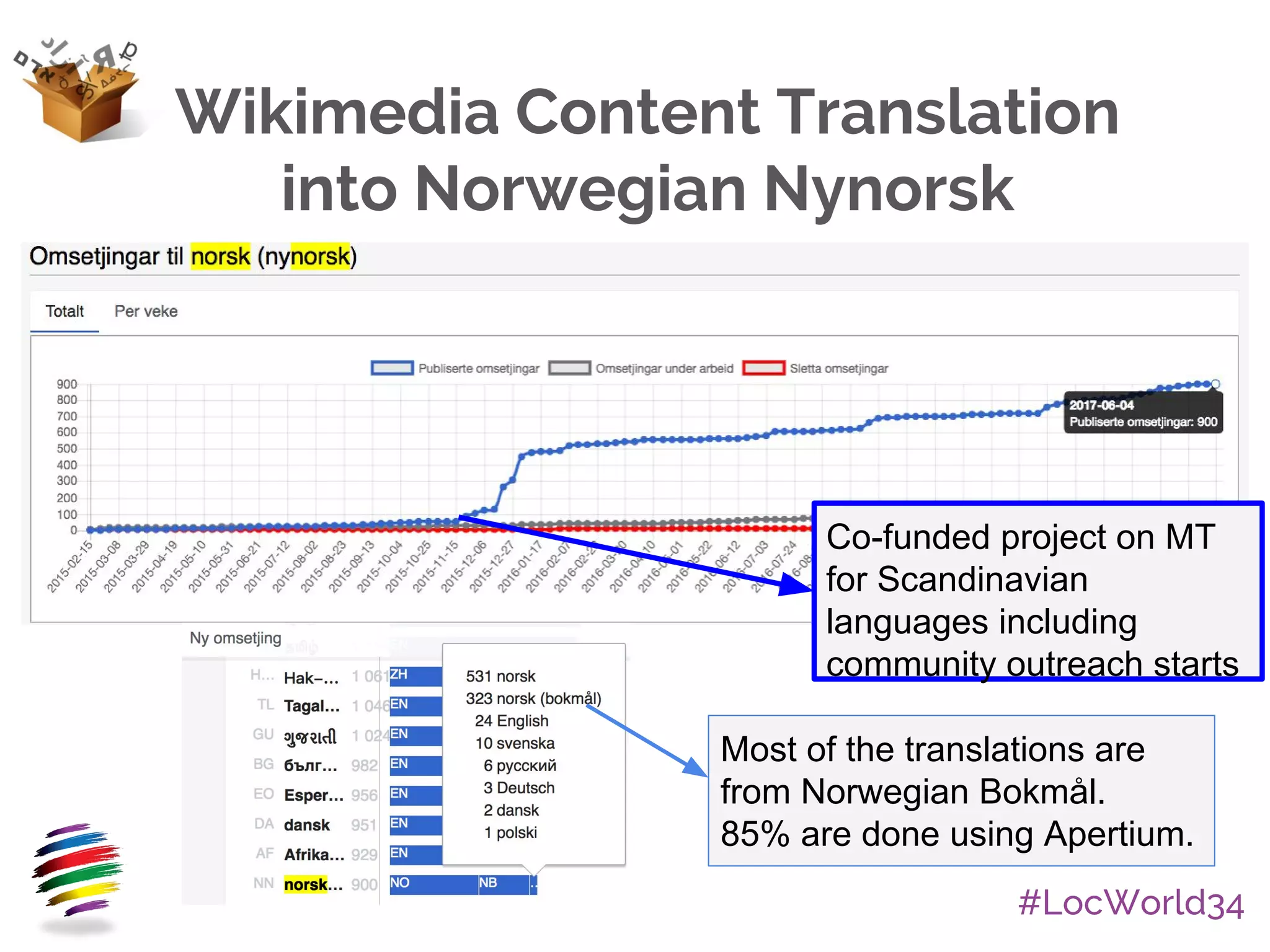
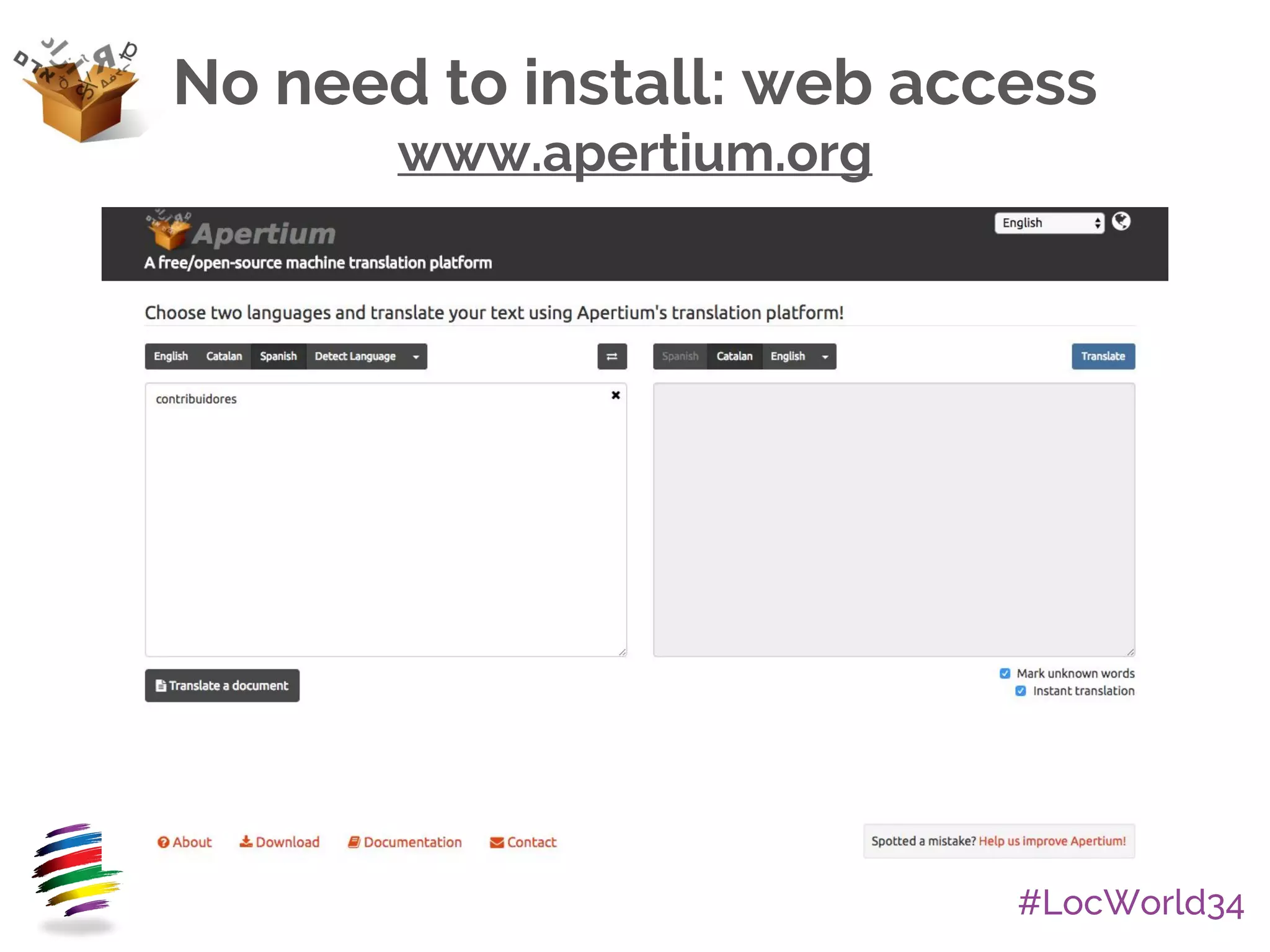
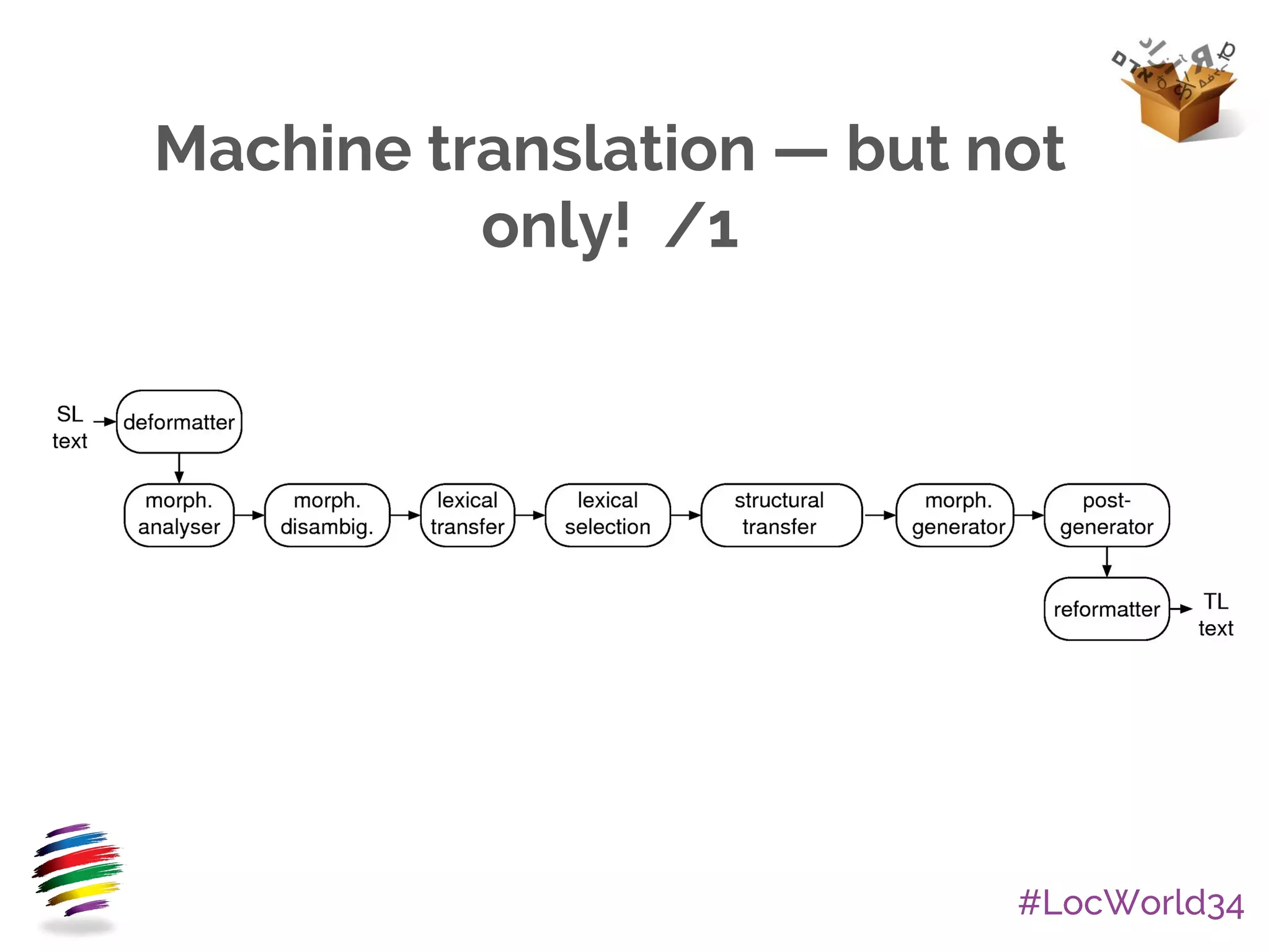
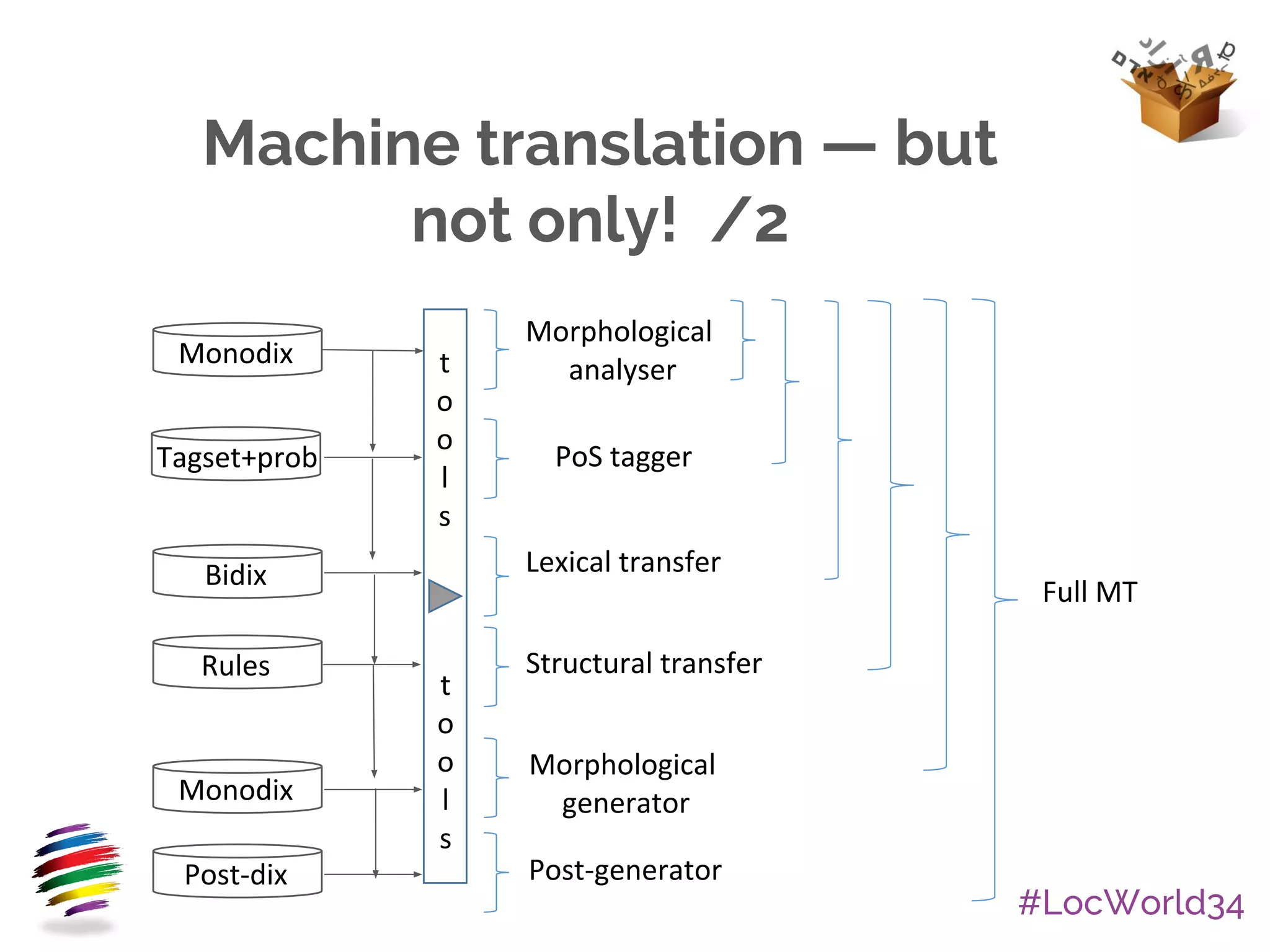
The document provides an overview of Apertium, an open-source machine translation system. It describes Apertium's main components, including its engine, data in XML formats, and tools. It also discusses Apertium's ready-to-use products, licensing as free/open-source, active community of hundreds of developers, research uses, over 40 supported language pairs including smaller languages, and some success stories in localization.
![#LocWorld34
Apertium: a Unique
Free/Open-Source MT System
for Related Languages
[but not only]
Gema Ramírez Sánchez1
Mikel L. Forcada1,2
1
Prompsit Language Engineering, Elx, Spain
1,2
Universitat d’Alacant, Alacant, Spain](https://image.slidesharecdn.com/apertium-locworld341-170620092539/75/Apertium-a-unique-free-open-source-MT-system-for-related-languages-but-not-only-1-2048.jpg)















![#LocWorld34
The Apertium community
[A search for Apertium faces in Google Images]](https://image.slidesharecdn.com/apertium-locworld341-170620092539/75/Apertium-a-unique-free-open-source-MT-system-for-related-languages-but-not-only-20-2048.jpg)
![#LocWorld34This is Francis Tyers (spectie)!
The Apertium community
[A search for Apertium faces in Google Images]](https://image.slidesharecdn.com/apertium-locworld341-170620092539/75/Apertium-a-unique-free-open-source-MT-system-for-related-languages-but-not-only-21-2048.jpg)