Downloaded 13 times


































![Pandas vs Spark Dataframe
import pandas as pd
!hive -e "select * from
users" > dt.csv
df = pd.read_csv("dt.csv")
counts = df[df.age > 30]
.groupby("sex")
.count()
from pyspark.sql import
HiveContext
ctx = HiveContext(sc)
df = ctx.sql("select * from
users")
counts = df[df.age > 30]
.groupby("sex")
.count()](https://image.slidesharecdn.com/8-161111204834/75/Apache-Spark-Rambler-Co-40-2048.jpg)


























![class SparkXGBoostClassifier(SparkSklearnClassifier):
def predict_proba(self, df):
rdd = df.map(self._create_dataset)
df = rdd.toDF()[['uid', 'feature']]
v_model = df._sc.broadcast(self.model)
res = df.rdd.mapPartitionsWithIndex(
partial(apply_model, v_model=v_model))
return res](https://image.slidesharecdn.com/8-161111204834/75/Apache-Spark-Rambler-Co-69-2048.jpg)
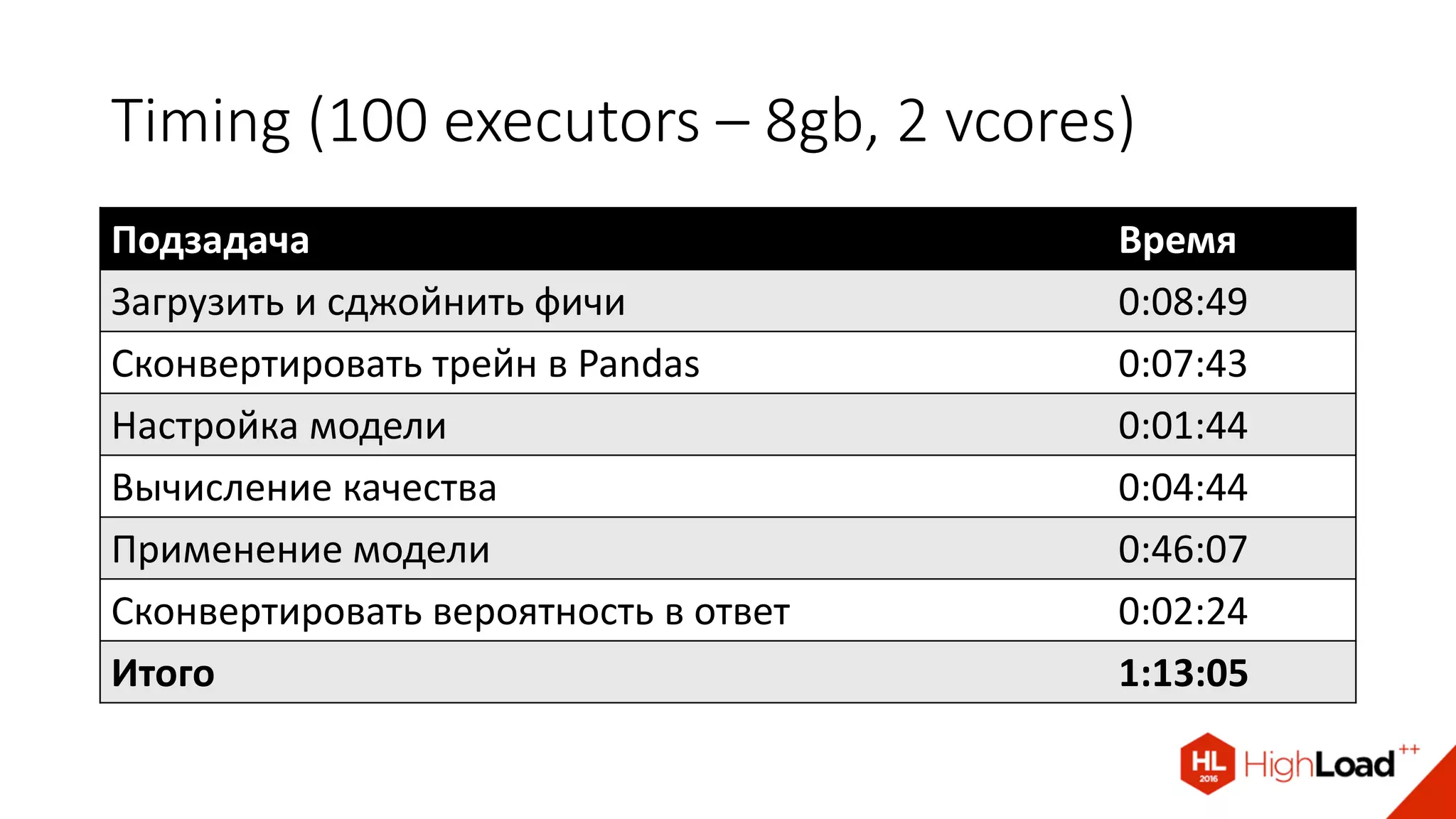


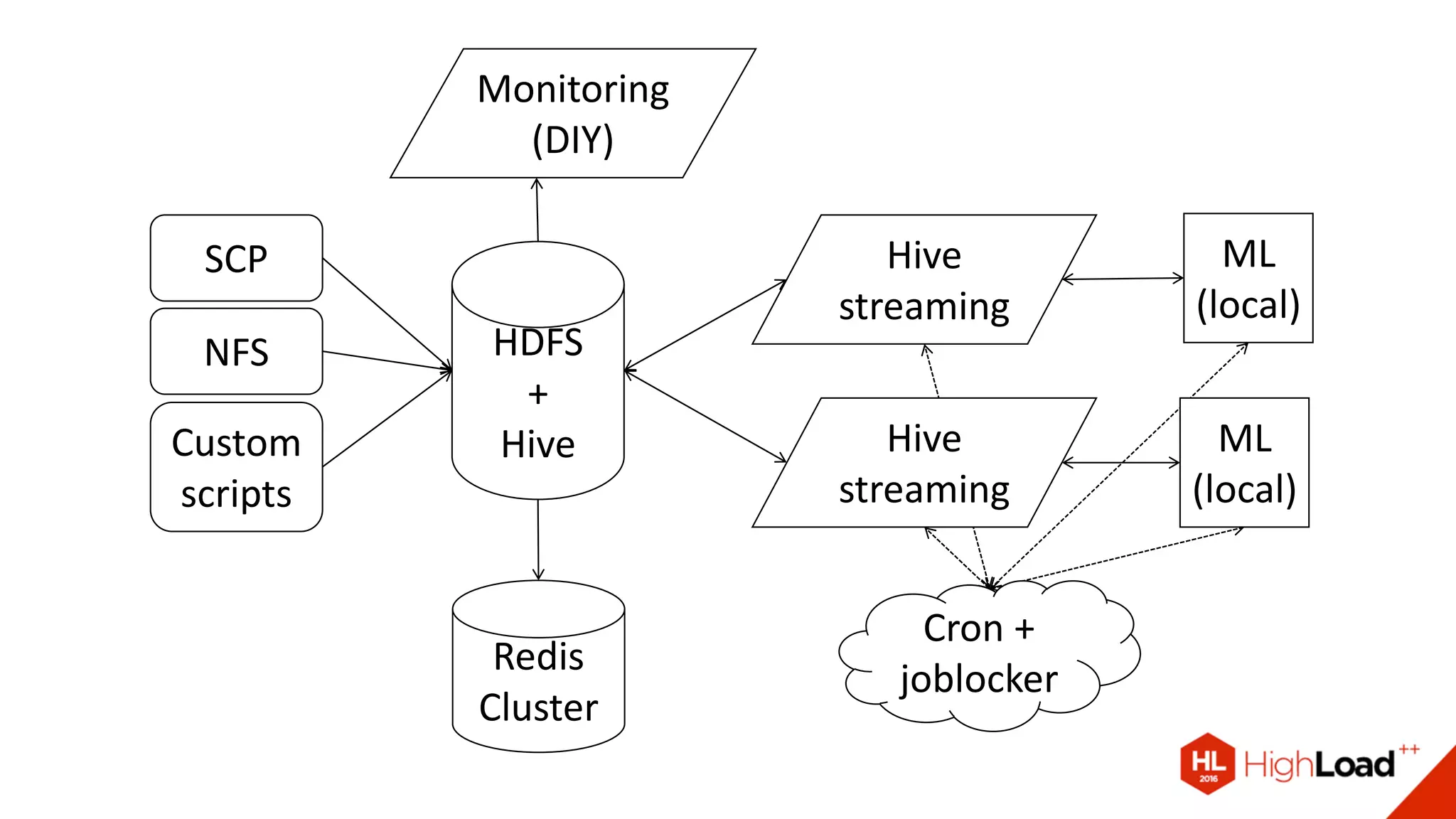
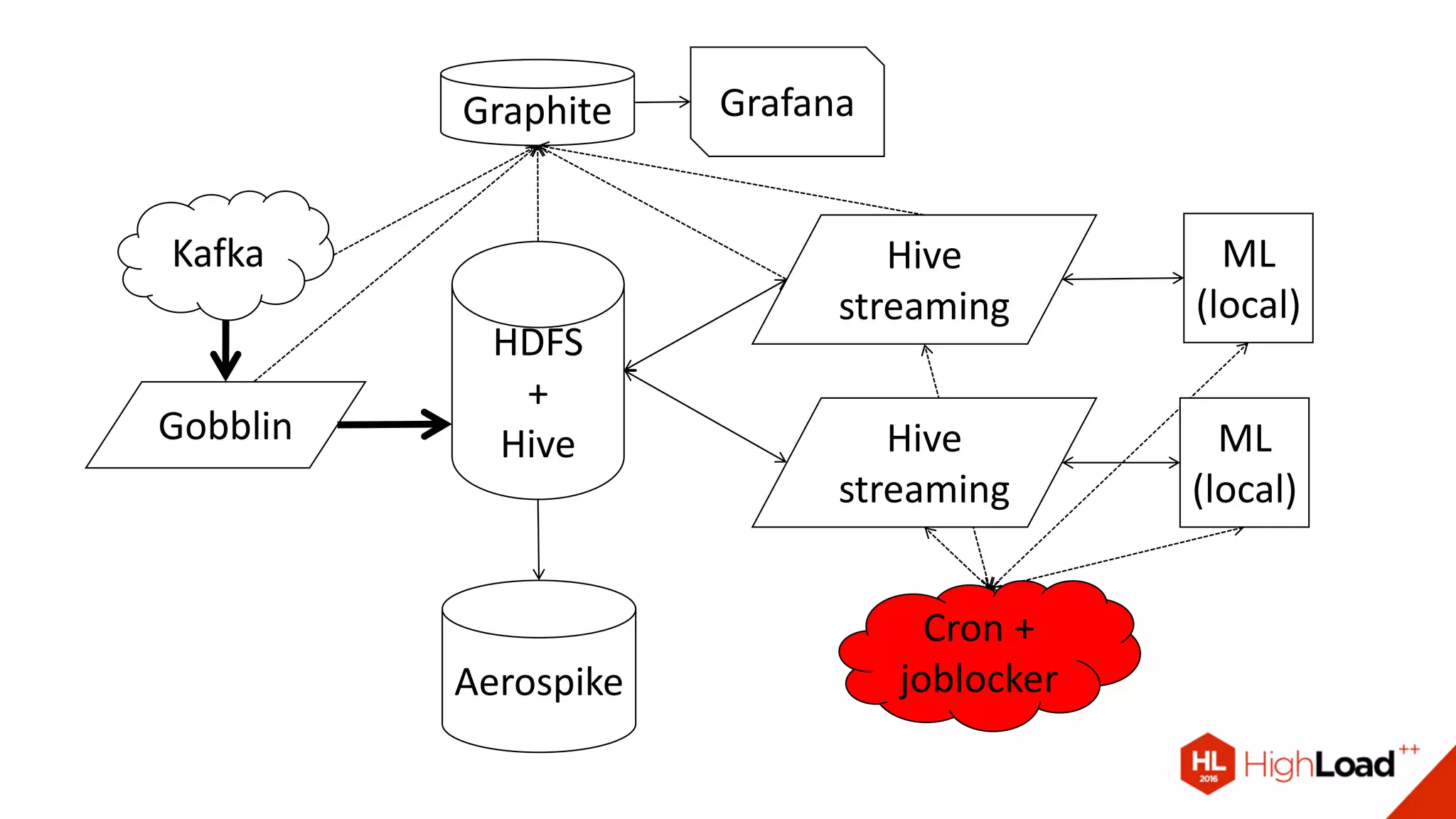
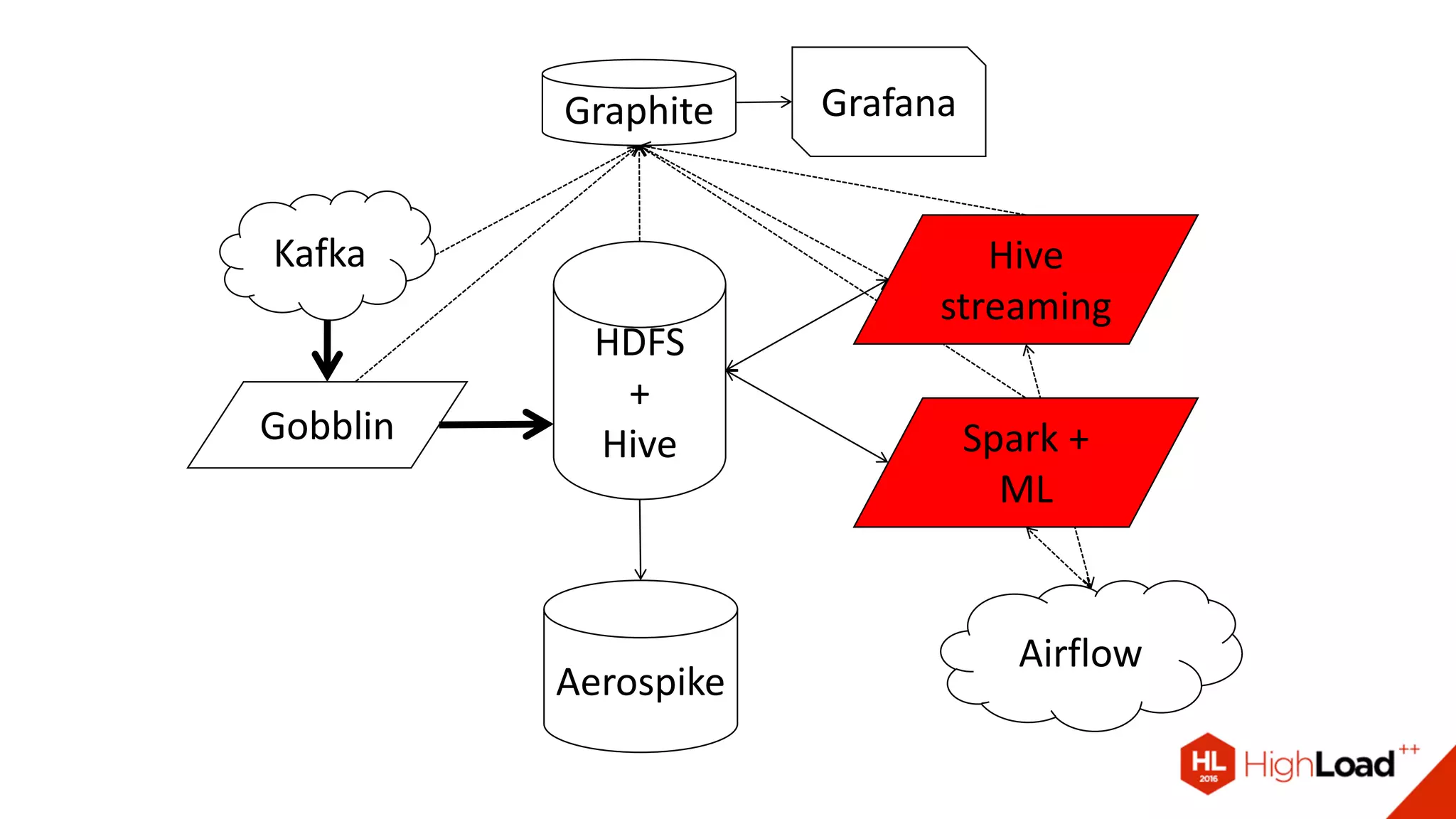
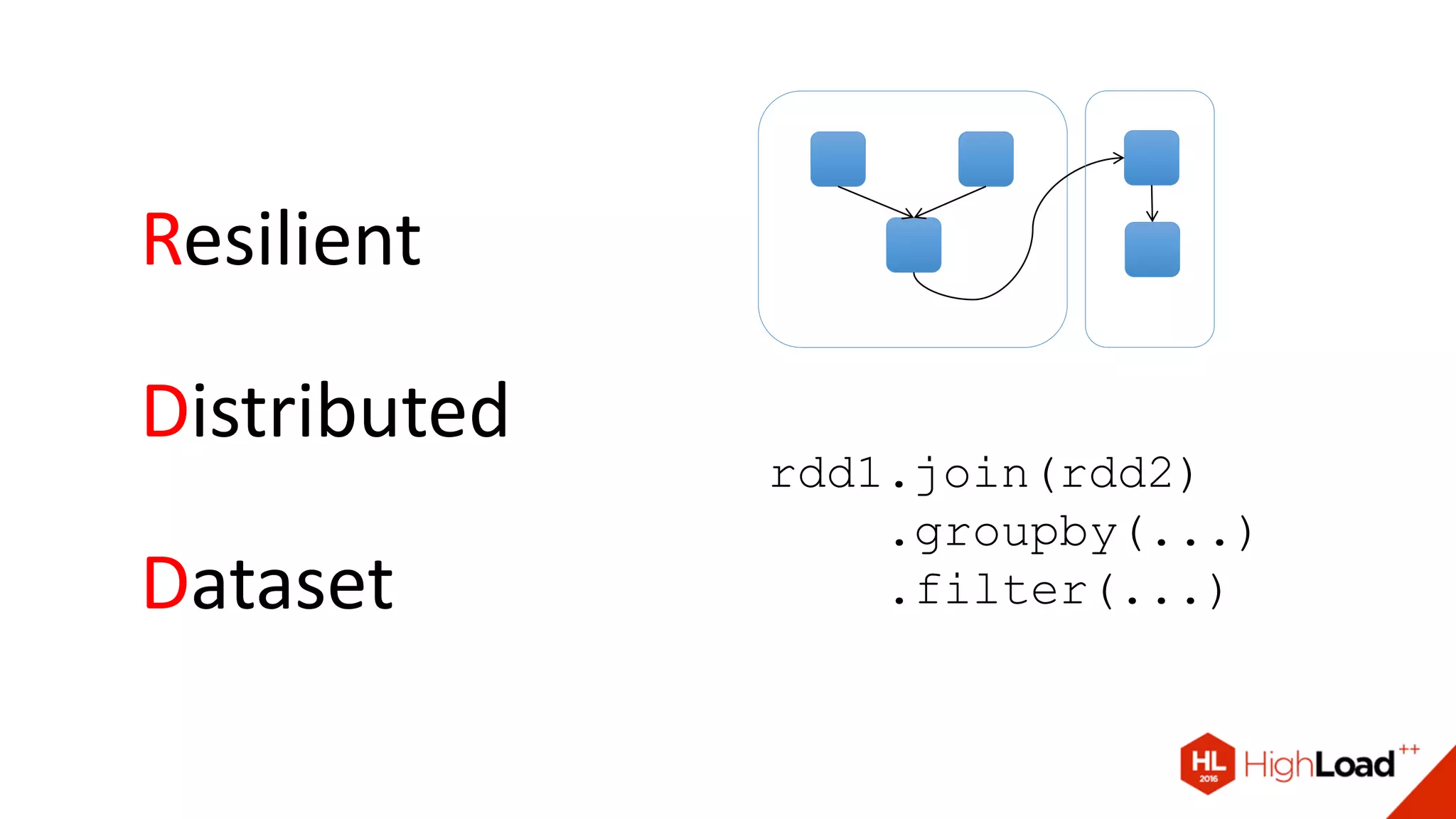
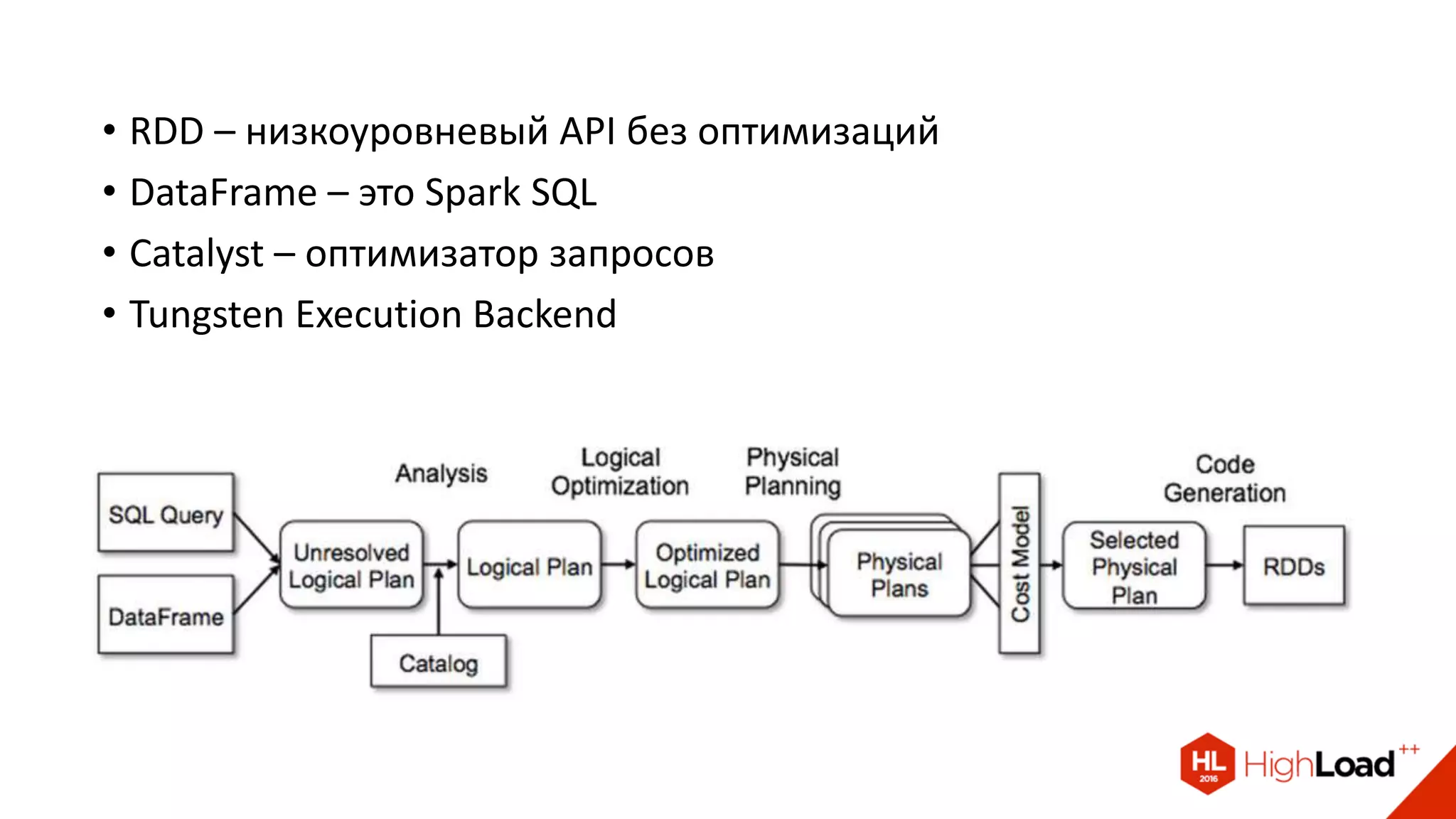
Документ описывает процесс создания и эксплуатации пайплайна машинного обучения на Apache Spark, включая проблемы с качеством данных и их обработкой. Обсуждаются различные компоненты архитектуры, такие как HDFS, Hive и Kafka, и предоставляются советы по оптимизации выполнения задач в Spark. Автор делится примерами решения проблем и оптимизации процесса в контексте использования таких библиотек, как Vowpal Wabbit и XGBoost.


































![[Expert Fridays] Python MeetUp - Леонид Блохин: "Нейросети на питоне: пфф easy"](https://cdn.slidesharecdn.com/ss_thumbnails/python-161206105218-thumbnail.jpg?width=640&height=640&fit=bounds)























