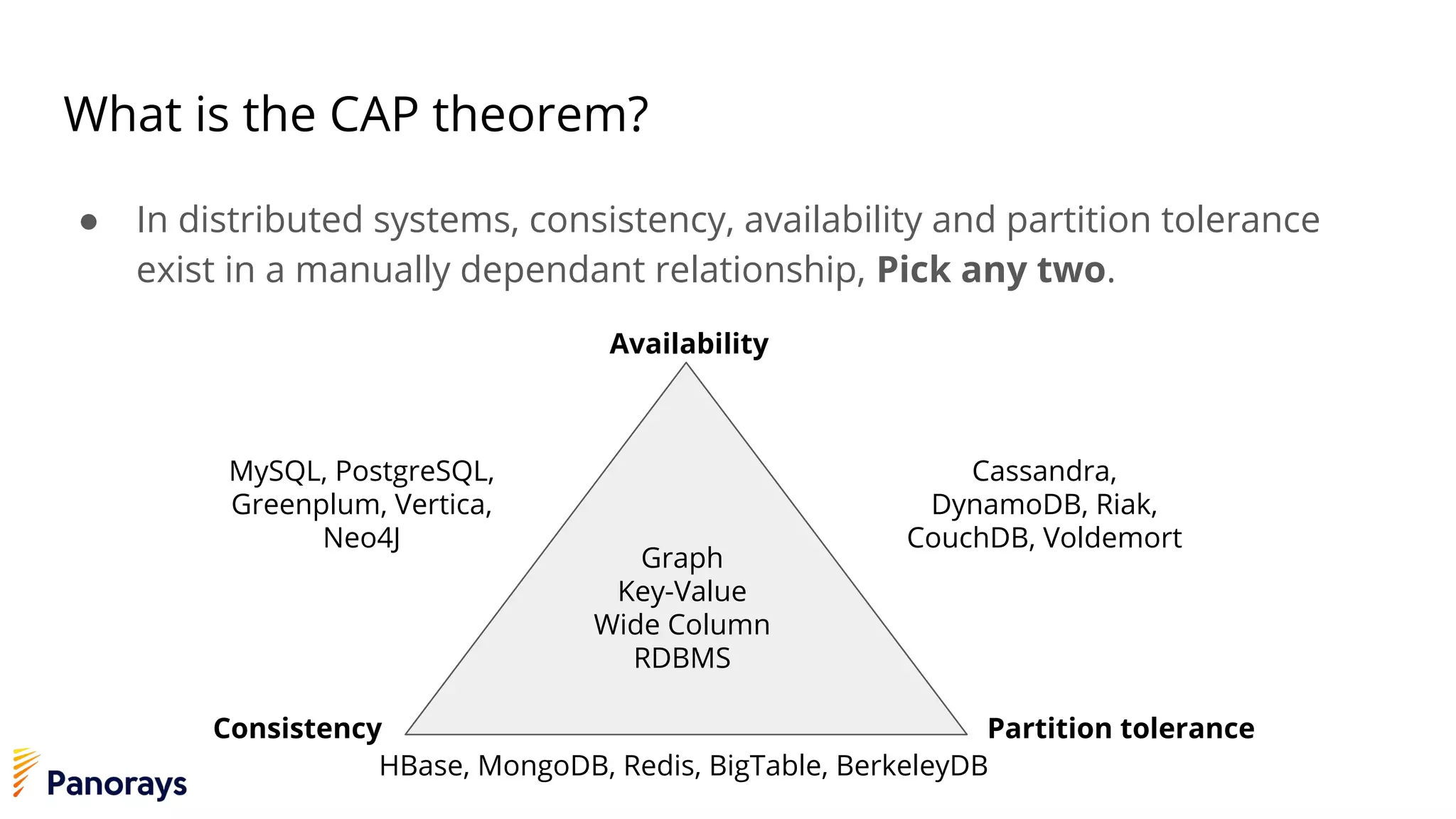

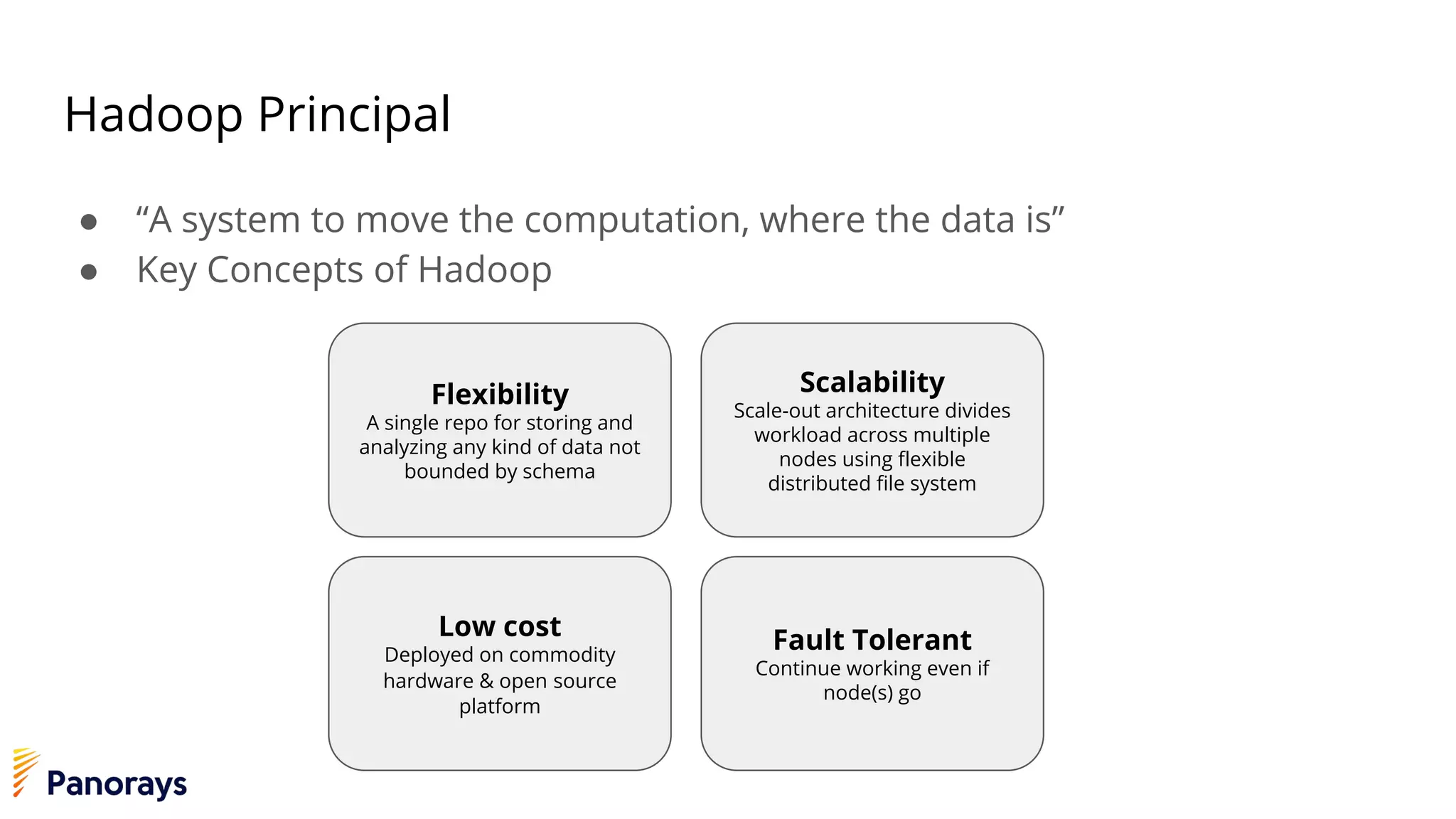

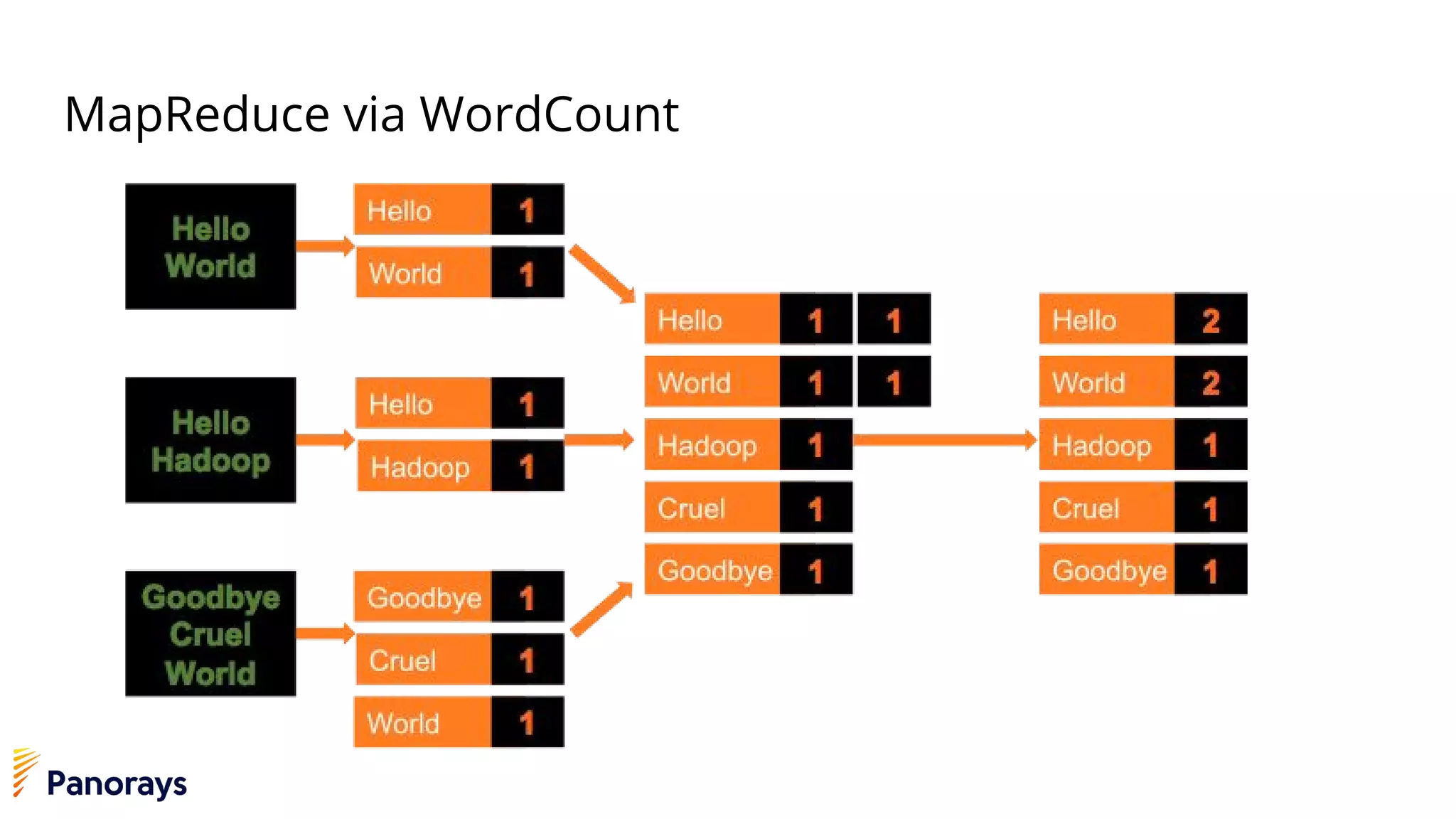
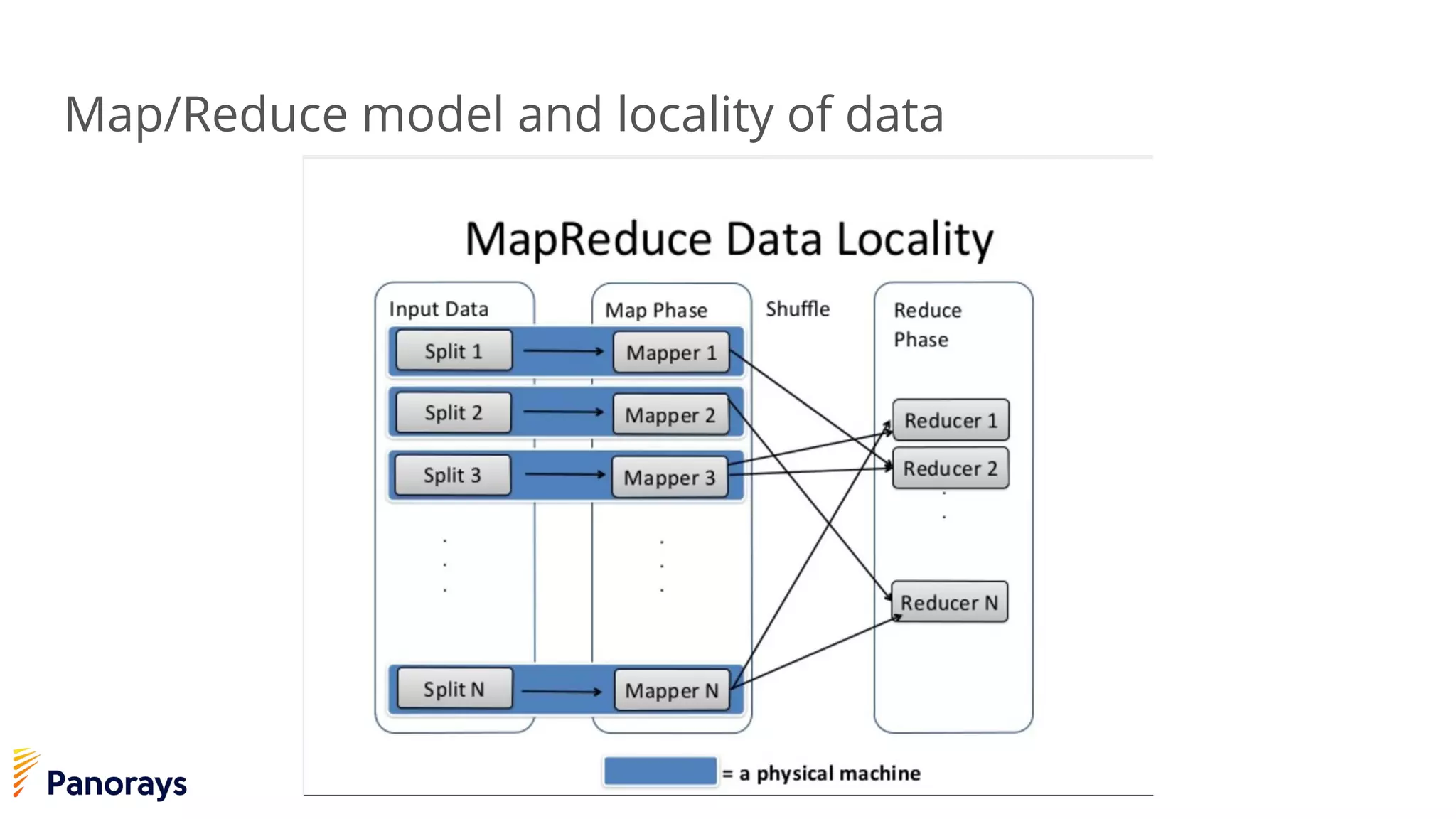
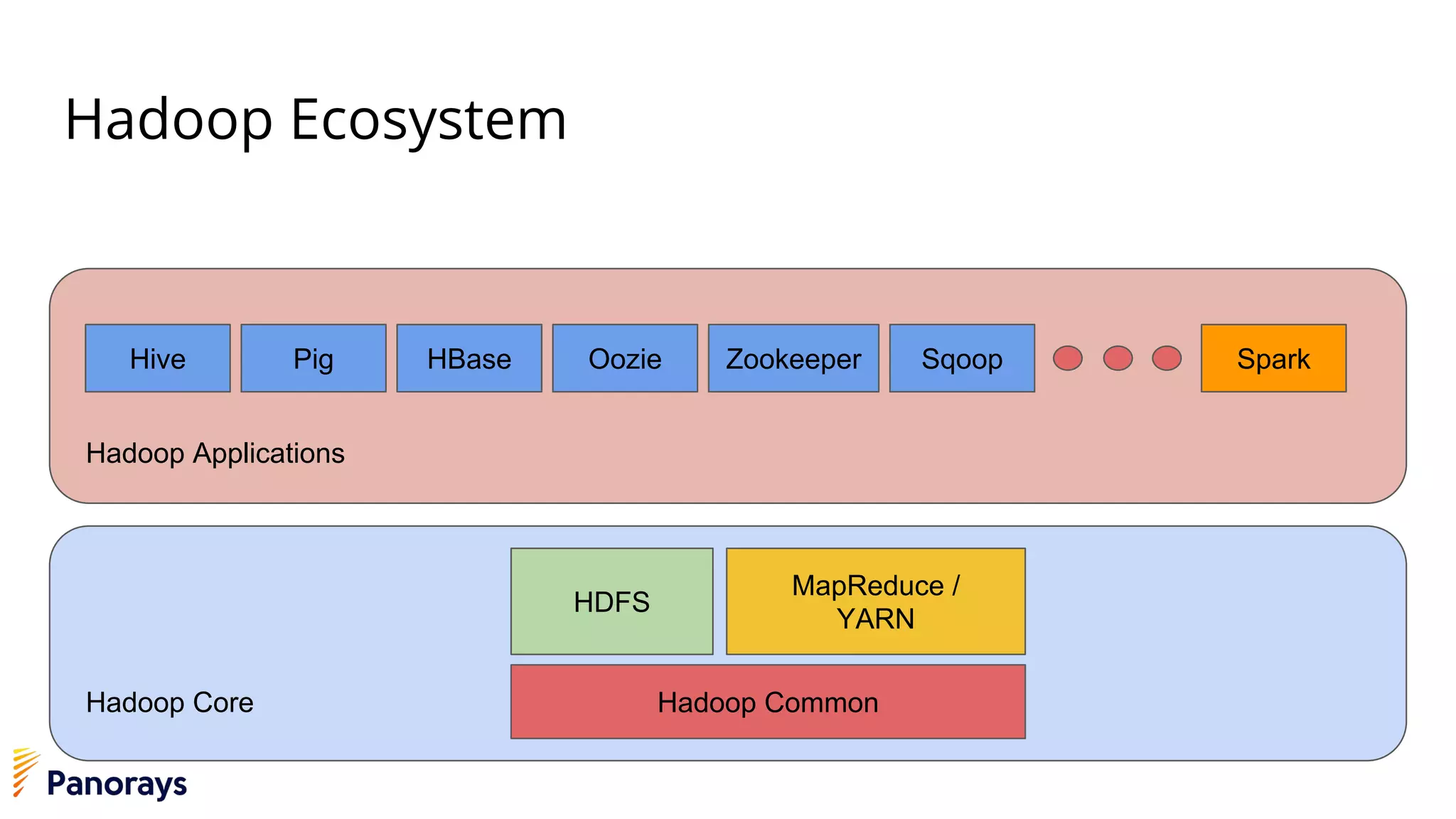






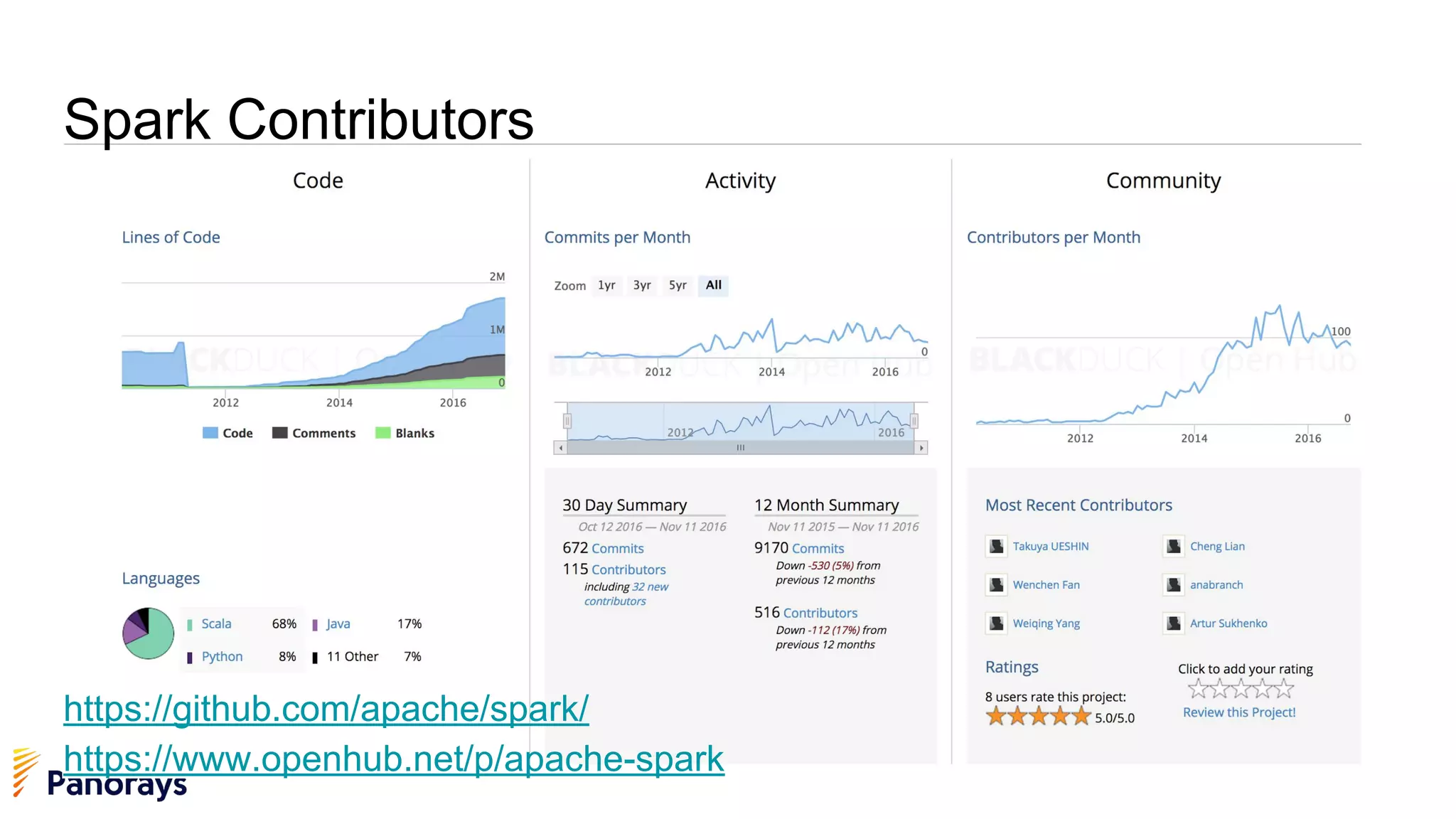

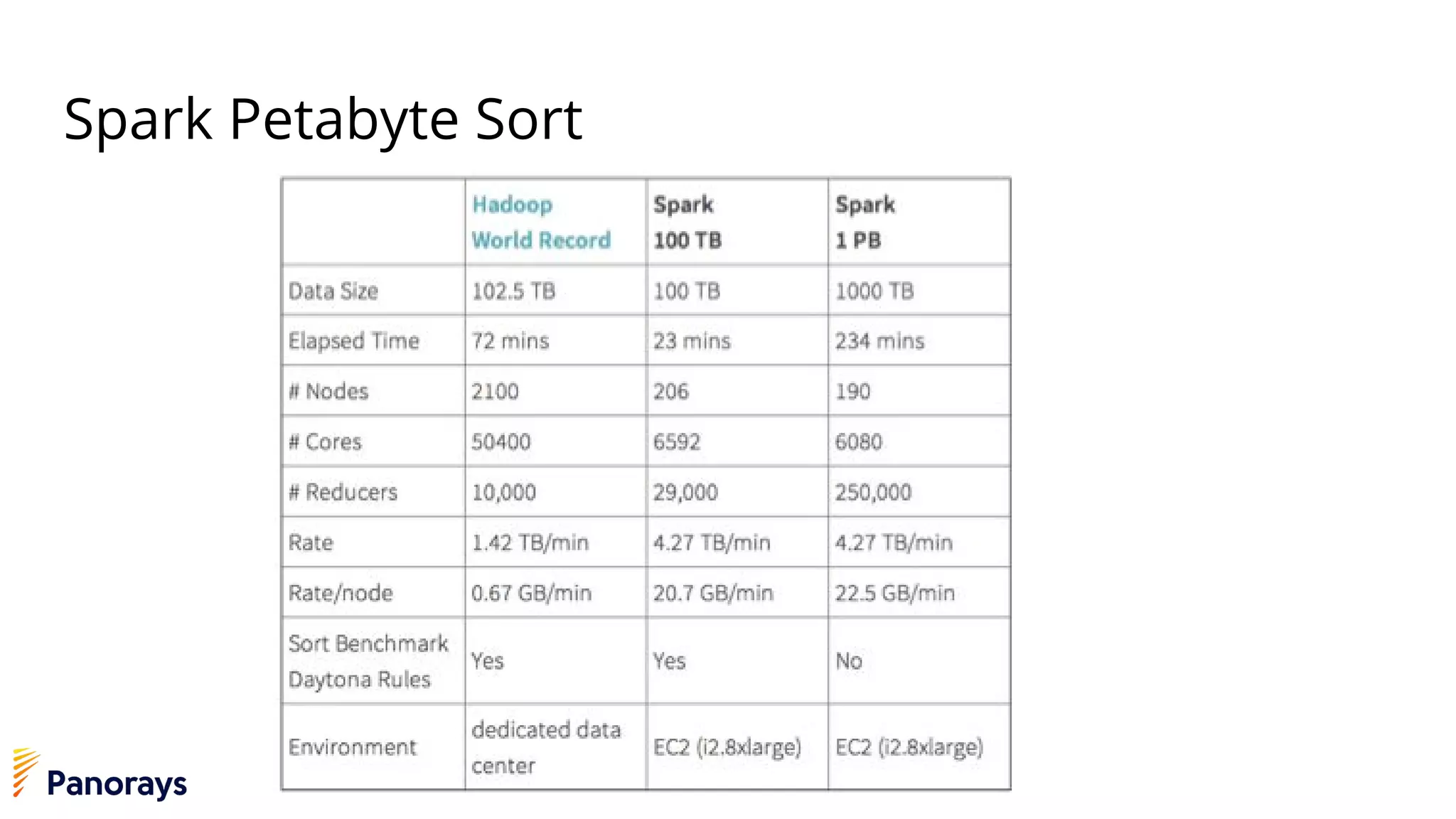
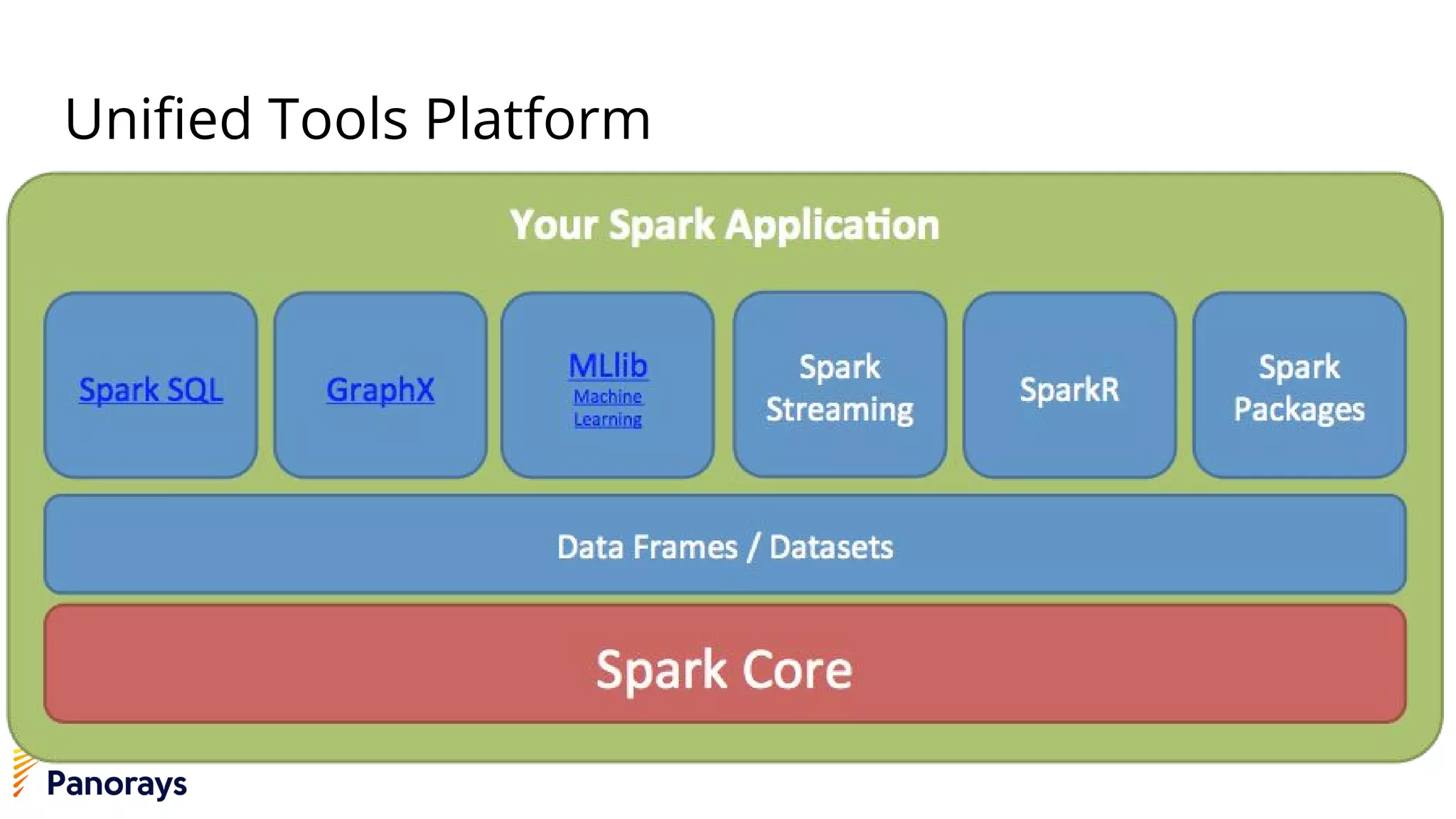



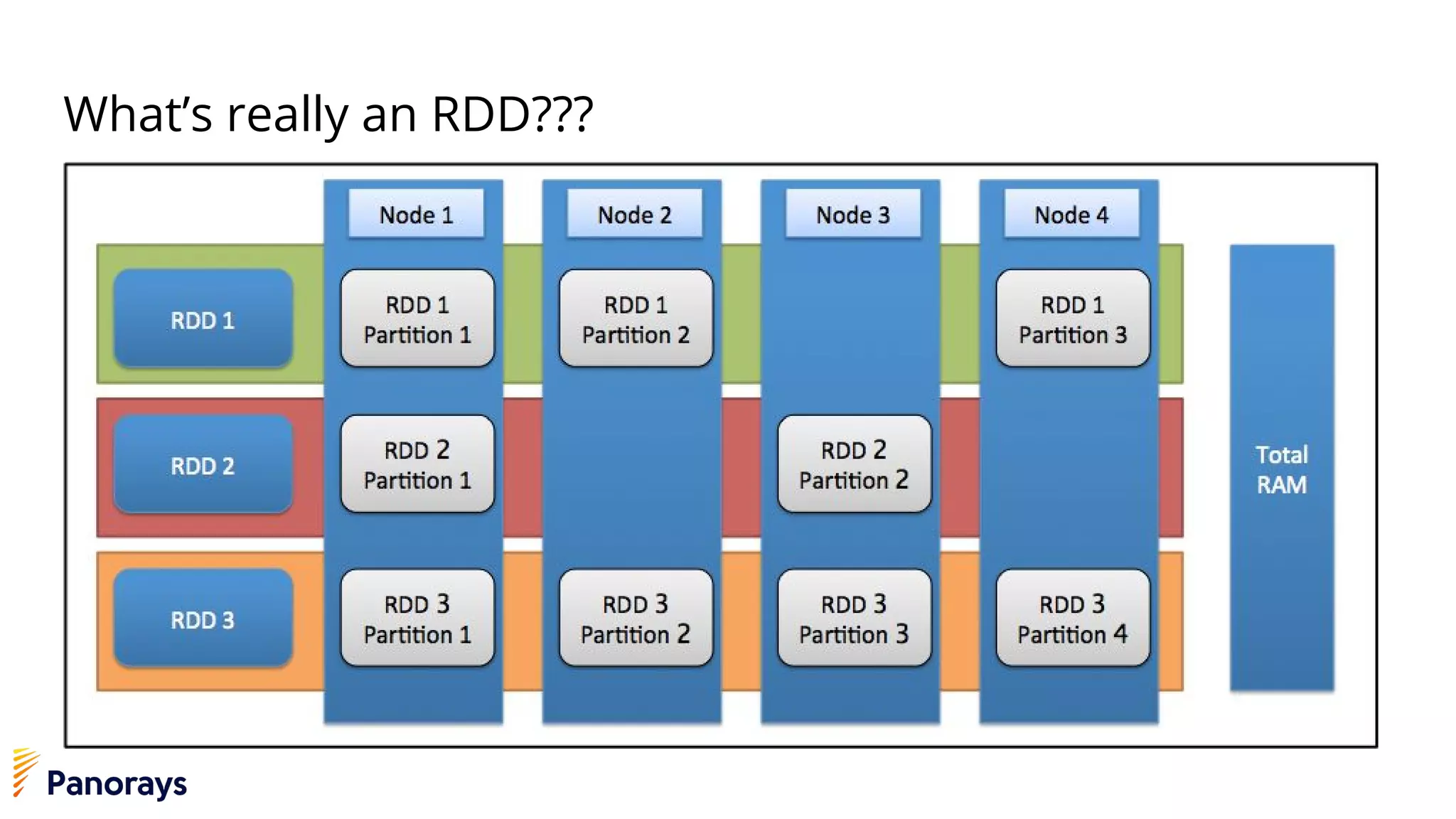
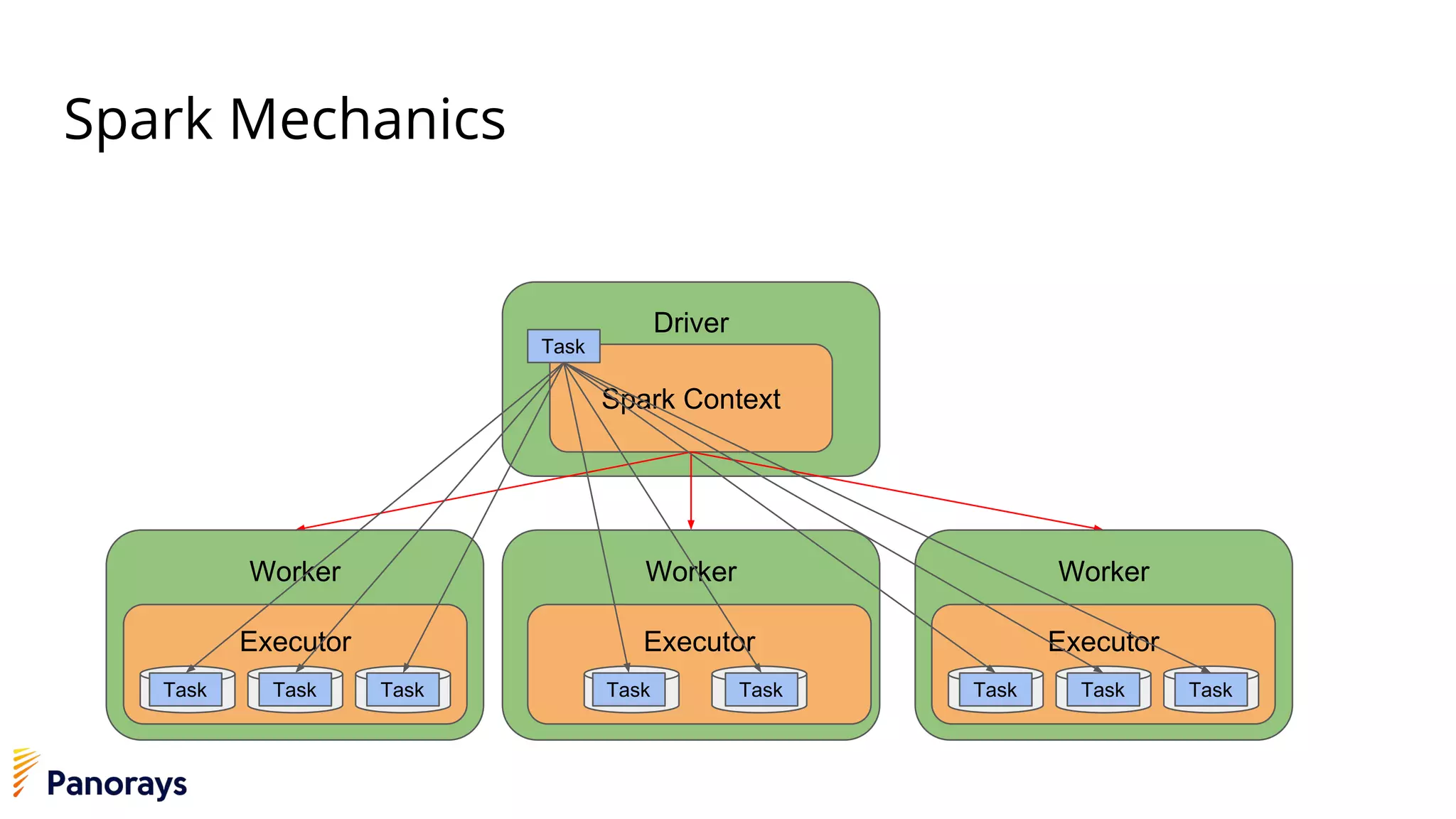

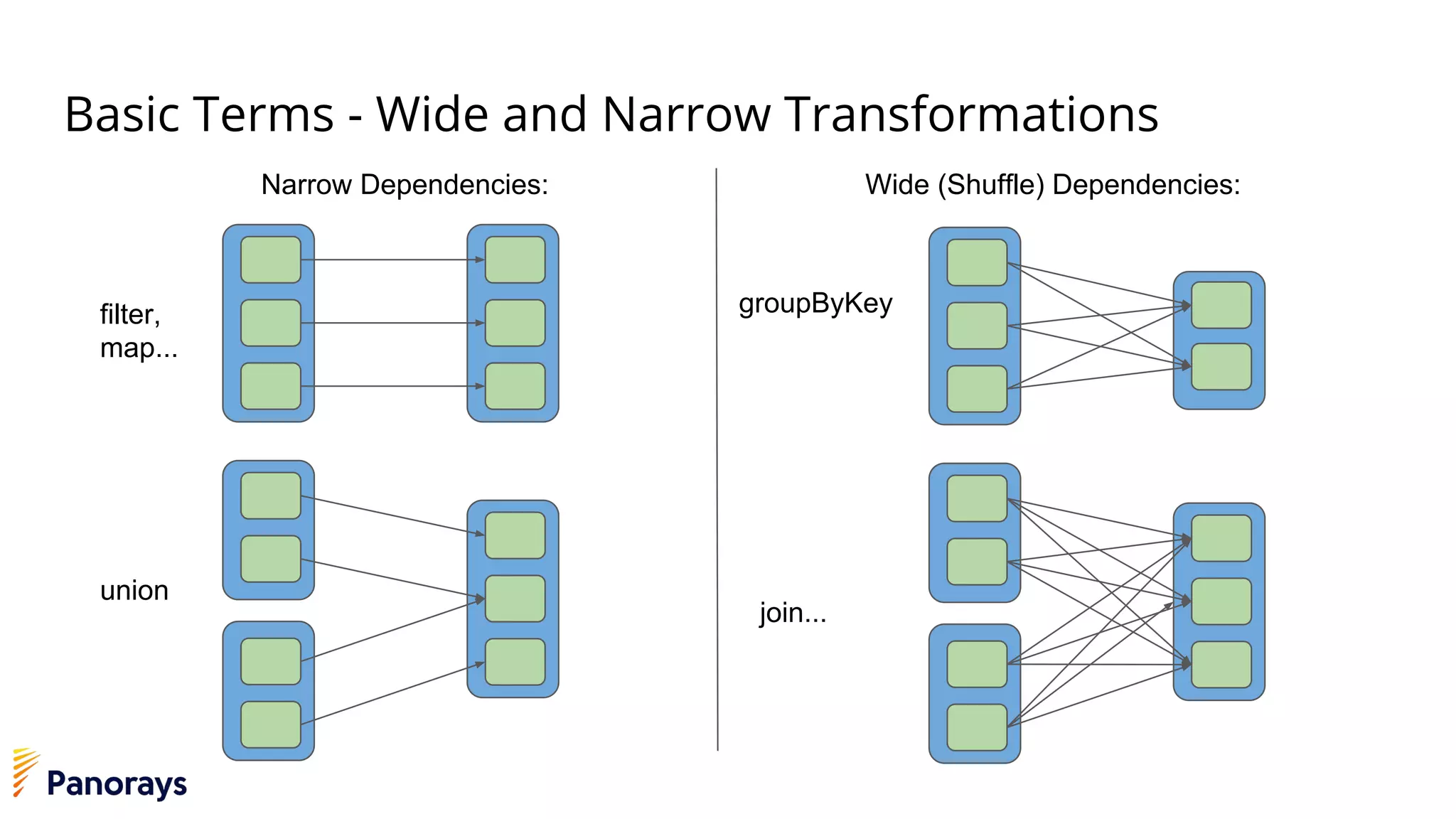















The document provides an introduction to big data and its management, detailing the characteristics, applications, and differences between relational and non-relational databases. It explains key concepts including the 3 Vs of big data (volume, velocity, variety), NoSQL database types, and the CAP theorem. Additionally, the document covers Apache Spark, its components, and use cases, emphasizing its efficiency for processing large datasets in a distributed computing environment.