Pengertian Patial ListSquare
Partial least square atau yang biasa disingkat PLS adalah jenis analisis statistik yang
kegunaannya mirip dengan SEM di dalam analisis covariance. Oleh karena mirip SEM maka
kerangka dasar dalam PLS yang digunakan adalah berbasis regresi linear. Jadi apa yang ada
dalam regresi linear, juga ada dalam PLS. Hanya saja diberi simbol, lambang atau istilah yang
berbeda.
Tujuan Partial List Square
Walaupun Partial Least Square digunakan untuk menkonfirmasi teori, tetapi dapat juga
digunakan untuk menjelaskan ada atau tidaknya hubungan antara variabel laten. Partial Least
Square dapat menganalisis sekaligus konstruk yang dibentuk dengan indikator refleksif dan
indikator formatif dan hal ini tidak mungkin dijalankan dalam Structural Equation Model (SEM)
karena akan terjadi unidentified model.
Pengertian PLS
5.
Fungsi Partial LeastSquare
1. Partial Least Square adalah analisis yang fungsi utamanya untuk perancangan model, tetapi juga dapat digunakan
untuk konfirmasi teori.
2. PLS tidak butuh banyak syarat atau asumsi seperti SEM. Apa itu SEM nanti akan saya jelaskan lebih lanjut pada
artikel lainnya.
3. Fungsi Partial Least Square kalau dikelompokkan secara awam ada 2, yaitu inner model dan outer model. Outer
model itu lebih kearah uji validitas dan reliabilitas. Sedangkan inner model itu lebih kearah regresi yaitu untuk
menilai pengaruh satu variabel terhadap variabel lainnya.
4. Kecocokan model pada Partial Least Square tidak seperti SEM yang ada kecocokan global, seperti RMSEA, AGFI,
PGFI, PNFI, CMIN/DF, dll. Dalam PLS hanya ada 2 kriteria untuk menilai kecocokan model, yaitu kecocokan
model bagian luar yang disebut dengan outer model dan kecocokan bagian dalam yang disebut dengan inner model.
Sehingga maksud poin 3 diatas adalah menjelaskan poin 4 ini. Untuk kecocokan model bagian luar ada 2 yaitu
pengukuran reflektif dan pengukuran formatif, yang sudah dijelaskan diatas.
5. Penilaian kecocokan model bagian luar atau outer model antara lain: Reliabilitas dan validitas variabel laten
reflektif dan validitas variabel laten formatif.
6. Penilaian kecocokan model bagian dalam antara lain: Penjelasan varian variabel laten endogenous, ukuran
pengaruh yang dikontribusikan dan relevansi dalam prediksi
https://www.statistikian.com/2018/08/pengertian-partial-least-square-pls.html
Reference:
6.
PLS (Partial LeastSquares)
▪ PLS adalah sebuah teknik yang dipakai untuk memprediksi model dengan banyak factor.Tujuan menggunakan
SMART PLS adalah untuk memprediksi hubungan antar konstruk,mengkonfirmasi teori, dan hubungan antara
variable laten.
▪ SMART PLS dibagi menjadi 2 model yaitu, Outer Model dan Inner model. Outer Model terdiri dari uji reliabilitas
dan uji validitas, sedangkan inner model terdiri dari koefisien determinasi dan uji hipotesis.
▪ Adapun keunggulan SMART PLS adalah tidak perlu membutuhkan data penelitian yang terdistrubusi secara
normal. Dan kelebihan lainnya dapat digunakan dalam jumlah sampel yang sedikit.
▪ SMART PLS memiliki kekurangan yaitu, distrbusi data tidak dapat diketahui secara pasti dan menyebabkan
tidak dapat menilai signifikansi statistic, namun kelemahan ini dapat diatasi dengan metode Bootstrapping.
▪ Perbedaan fungsi masing-masing program yang sebenarnya sama sama dapat digunakan untuk
menganalisa penelitian model diagram jalur.Dalam Program SPSS,analisis jalur bisa dianalisis secara bertahap
dengan melakukan regresi linear.Sedangkan pada SMART PLS,analisis jalur dapat langsung dilakukan dalam
sekali uji saja,dan juga menggunakan SMART PLS bisa menganalisa grafik path sekaligus.
▪ Penggunaan Smart PLS sangat dianjurkan ketika kita memiliki keterbatasan jumlah sampel,padahal model yang
dibangun adalah kompleks. Tujuan menggunakan SMART PLS untuk mempridiksi hubungan antar
konstruk,mengkonfirmasi teori dan dapat juga digunakan untuk menjelaskan ada hubungan atau tidaknya
antara variable laten.
7.
SPSS ( StatisticalProduct and Service Solutions)
atau Statistical Package for the Social Sciences
▪ SPSS adalah program aplikasi yang digunakan untuk menganalis statistic.SPSS memiliki beberapa
keunggulan memberikan tampilan data yang lebih informative,informasi lebih akurat dengan
memberikan kode alasan. Dalam SPSS kita dapat melihat dari uji validitas, reliabilitas, statistic
deskriptif, distribusi frekuensi, nilai rata-rata, koefisien determinasi, regresi linear, dan hipotesis.
▪ SPSS ini juga disebut sebagai PASW ( Predictive Analytics Software), karena perusahaan IBM sudah
membeli SPSS. Sedangkan Smart PLS adalah sebuah aplikasi perangkat lunak untuk grafis
permodelan jalur dengan variable laten atau (LVP).
▪ Adapun kelebihan SPSS ialah dia mampu mengakses data penelitian dari berbagai jenis format
yang ada, sehingga data yang sudah tersedia dapat digunakan langsung untuk melakukan analisis
data.
▪ SPSS bersifat software komersial untuk lisensi berbayar. Aplikasi SPSS dapat dijalankan di Sistem
windows 7,MacOs dan Linux
https://uptjurnal.umsu.ac.id/apa-perbedaan-smart-pls-dan-spss-yuk-simak-penjelasan-berikut
Reference:
Istilah Dalam PLS
-Variabel laten adalah variabel yang tidak dapat diukur secara langsung, tetapi keberadaannya
disimpulkan melalui variabel lain yang dapat diamati (variabel manifest). Variabel ini digunakan dalam
model penelitian untuk mewakili konsep atau konstruk yang tidak bisa diukur secara langsung.
- Konstruk merujuk pada konsep atau variabel laten yang tidak dapat diukur secara langsung, tetapi
diukur melalui indikator-indikatornya (variabel manifest).
- Konstruk bisa berupa variabel independen (eksogen) atau dependen (endogen) dalam model.
- Indikator merupakan variabel terukur yang digunakan untuk merepresentasikan variabel laten
(unobserved variable) dalam model.
- Indikator ini bisa bersifat reflektif (reflective) atau formatif (formative), dan pengujiannya dilakukan
melalui outer model (model pengukuran) untuk melihat validitas dan reliabilitasnya.
- Dimensi" mengacu pada dua aspek utama: model pengukuran (outer model) dan model struktural
(inner model).
10.
Istilah dalam PLS
-Dimensi" mengacu pada dua aspek utama: model pengukuran (outer model) dan
model struktural (inner model).
- Outer model" atau model pengukuran adalah bagian dari model yang
menjelaskan hubungan antara variabel laten (konstruk) dengan indikator-
indikatornya (variabel yang diamati). Ini adalah bagian dari model SEM
(Structural Equation Modeling) yang berbasis varian dan digunakan untuk
menguji validitas dan reliabilitas indikator dalam mengukur konstruk laten
- Inner model (model struktural) adalah bagian dari model yang menggambarkan
hubungan kausal antara variabel laten atau konstruk dalam penelitian. Model ini
berfokus pada bagaimana variabel laten memengaruhi satu sama lain, dan
seringkali digunakan untuk menguji hipotesis penelitian terkait hubungan sebab-
akibat antar variabel
11.
Istilah dalam PLS
-Model pengukuran menjelaskan bagaimana variabel laten (latent
variables/constructs) diukur oleh variabel manifes (manifest variables/indicators).
- Model struktural menggambarkan hubungan antar variable laten
- Persamaan struktural dalam Partial Least Squares (PLS) adalah model matematis
yang menggambarkan hubungan antara variabel laten (tidak teramati) dalam suatu
penelitian, serta hubungan antar variabel laten tersebut. Model ini digunakan
dalam Structural Equation Modeling (SEM) berbasis PLS. Secara sederhana, model
struktural PLS menjelaskan bagaimana variabel laten independen (penyebab)
mempengaruhi variabel laten dependen (akibat) melalui persamaan matematis
12.
• Loading factordalam PLS (Partial Least Squares) adalah ukuran korelasi
antara indikator dengan variabel laten. Nilai loading factor menunjukkan
seberapa besar indikator tersebut berkontribusi dalam menjelaskan
variabel laten. Dalam PLS, loading factor yang tinggi (biasanya > 0.7)
menunjukkan bahwa indikator tersebut valid dan dapat diandalkan untuk
mengukur variabel laten.
• Dalam Structural Equation Modeling (SEM), estimate mengacu pada nilai
parameter model yang dihitung berdasarkan data sampel,
• Standard estimate (atau standar kesalahan estimasi/Standard Error of
Estimate) adalah ukuran seberapa akurat estimasi tersebut,
mengindikasikan tingkat ketidakpastian dalam estimasi parameter
Istilah dalam PLS
13.
Istilah dalam PLS
•Original sample: merujuk pada estimasi parameter model
menggunakan data asli yang anda masukkan, tanpa melalui proses
bootstrapping. Ini adalah hasil yang anda peroleh dari estimasi
algoritma PLS secara langsung pada data anda.
• Perbedaan utama antara PLS (Partial Least Squares) dan SPSS terletak
pada pendekatan analisisnya. SPSS, yang merupakan singkatan dari
Statistical Package for the Social Sciences, lebih berfokus pada analisis
statistik deskriptif dan inferensial tradisional, termasuk regresi linier,
ANOVA, dan lainnya.
Implementasi & ProsesPerhitungan PLS
Prof. Dr. Dr. Aminullah Assagaf, SE., MS., MM., M.Ak
1. INPUT DI EXCEL DATA DAN BUKA PLS
▪ Input data di Excel – Save as - Nama file.CSP (mis: A2923.CSP)
▪ Buka PLS – File – Create new project – Nama (baru, mis: A3) – Ok
▪ Bagian kiri: Doble click to input data – cari data di laptop (mis: A2923.CSP) –
Open – Nama (sesuai nama file excel di laptop) – Ok
▪ Output: (1) Statistic descriptive, (2) Correlation (indicator variabel)
2. BUAT GAMBAR
▪ Bagian kiri: klik file A3 untuk kosongkan bagian kanan
▪ Blok tiap indicator – Geser kekanan – Edit gambar Y dgn klik kanan – pilih Align
indicator right
▪ Rename tiap variable: klik kanan – Rename – Nama baru - Ok
▪ Buat garis penghubung X ke Y: Connect – hubungkan tiap variable – setelah
selesai – warna gambar merah menjadi biru
16.
3. HITUNG :GAMBAR DGN KOEFISIEN & t-STATISTIK
GAMBAR & KOEFISIE
▪ Klik Calculate – PLS Algoritm – Start calculation
▪ Buka gambar di file *A3.Splsm
GAMBAR & t-STATISTIK
▪ Klik Calculate – Bootstrapping – Start calculation
▪ Buka gambar di file *A3.Splsm
4. OUTPUT
▪ Membedakan gambar dengan koefisien atau gambar dengan t-statistik: perhatikan
bagian kiri bawah: PLS Algorthm utk koefisien, dan Bootstrapping untuk t-statistik
▪ Untuk mengganti gambar dari PLS Algorithm ke Bootstrapping: Calculate –
Bootstrapping – Start calculation – dan sebaliknya.
17.
5. EXPORT KEEXCEL
▪ EXPORT ke Excel: Posisi Bootstrapping: Save dan export data ke excel: bagian kiri
bawah Bootstrapping – pilih excel – Start export - Save – hasilnya dapat dibuka file
excel untuk: (1) Coefficient regresi, (2) t-statistik, (3) P Value, (4) data hasil
penelitian, dsb
▪ EXPORT ke Excel: Posisi PLS Algorithm: Save dan export data excel: bagian kiri
bawah PLS Algorithm – pilih excel – Start excel - Save – hasilnya dapat dibuka data
excel untuk: (1) Korelasi indicator, (2) Reliability, (3) Validity, (4) data hasil
penelitian, dsb
▪
18.
6. OUTPUT PLSALGORITHM & BOOTSTRAPPING
▪ Output PLS Algorithm dan Bootstrapping dapat juga dilihat pada bgian tengah: bagian kiri klik Report – akan terbuka output
bagian kanan – tampilkan secara bergantian dengan pilihan pada bgian bawah – Tiap pilihan menghasilkan satu atau
beberapa tampilan format – perhatikan bgian atas output tsb
▪ Tampilan output PLS Algorithm dan Blootstrapping berbeda
▪ Output dari PLS Algorithm, al: (1) gambar & koefisien, (2) korelasi indicator – di Indicator data (Correlation), (3) Data hasil
penelitian – di indicator data (original), (4) Reliability- Crombatch Alpha – di Construct reliability and validity, (5) Validity – di
Discriminant validity, (6) Statictics descriptive, dst
▪ Outrput dari Bootstrapping, al : (1) Gambar & t-statistik, (2) Coefficient, t-statistik, Pvalue – di Path coefficient atau di Total
effect, (3) Data hasil penelitian – di indicator data (original), (4) uji variable intervening (indirect effect), dst.
7. PLS belum tersedia:
▪ (1) F-statistics, (2) Uji normality, (3) Uji autocorrelation, (4) Uji heteroskedastisitas
8. Perbedaan perhitungan PLS & SPSS:
▪ (1) t-statistics di PLS= SC/Sstandar deviasi, (2) t-statistics di PSS = USC/ standar deviasi, (3) Uji variable intervening di PLS:
menggunakan uji Path, (4) Uji variable ntervening di SPSS: menggunakan Uji Sobel dan Uji Path.
Demikian, silahkan dicoba dan semoga sukses…Aamiin…...
Jakarta, 2 Juli 2025
Prof. Dr. Dr. Aminullah Assagaf, SE., MS., MM., M.Ak
Report: copy Gambar& capture utk yg lainnya
• Klik kanan – Export as image to file – Buka folder – Nama (file) – Save
• Klik kanan pada gambar – copy – Buka PPT – paste
• Untuk table dll: copy ke PPT melalui proses Capture
PLS - DataIndikator
Gambar & Coefficients, Tabel Coeffieints
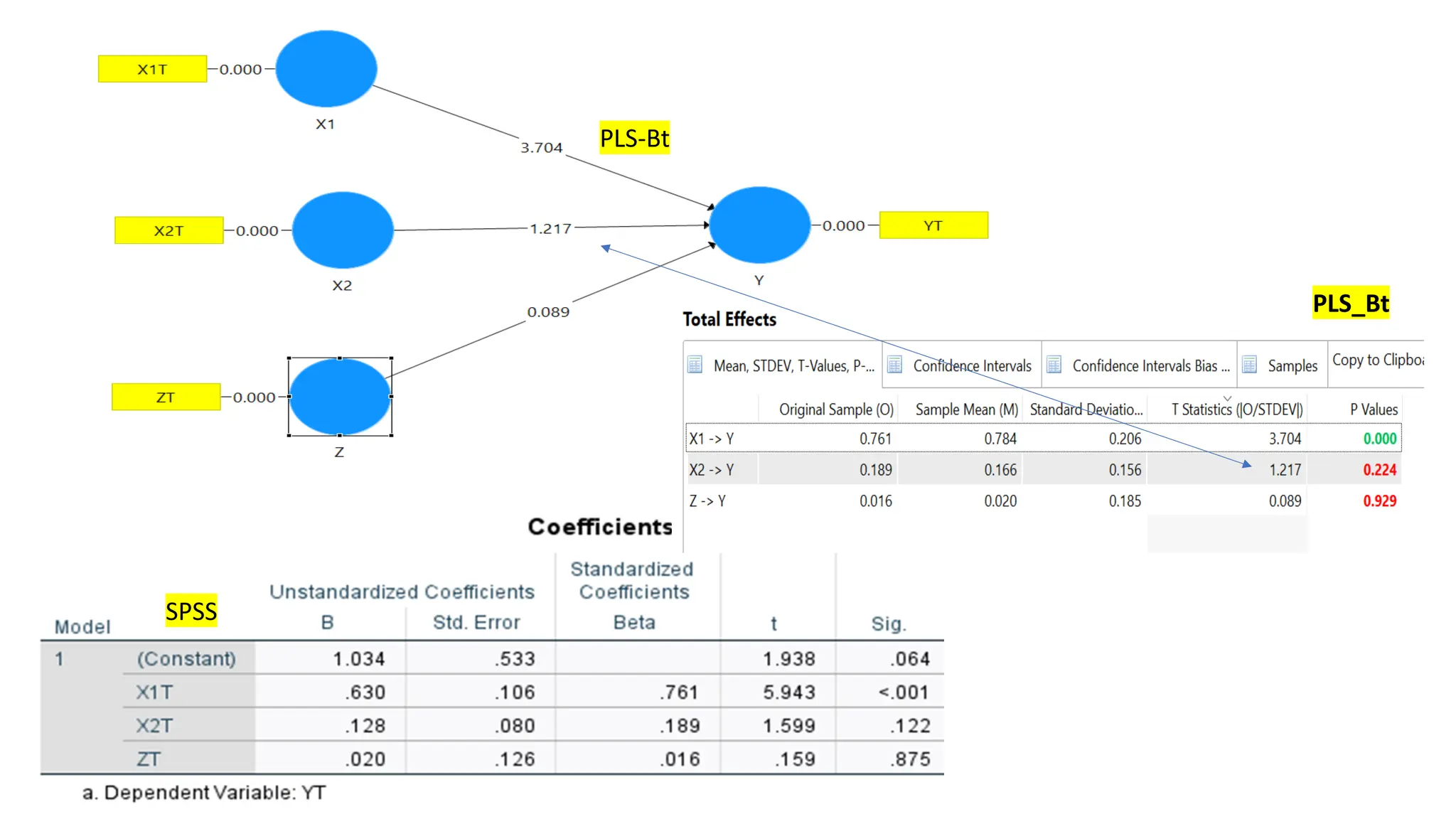
(1) Persamaan simultan dengan variable intervening (Y dan Z dlm gambar yg sama): Y=f(X1, X2, Z) dan Z=f(X1, X2, Z)
(2) Persamaan individual Y gambar terpisah: Y = f(X1, X2, Z)
(3) Persamaan individual Z gambar terpisah: Z = f(X1, X2)
Konstanta = Constant
•Konstanta" merujuk pada nilai tetap atau nilai yang tidak berubah, baik
dalam matematika maupun dalam bahasa pemrograman
• Konstanta dalam Matematika: dalam matematika, konstanta adalah suatu
nilai yang tetap dan tidak dapat diubah.
• Perbedaan dengan Variabel: Konstanta berbeda dengan variabel. Variabel
adalah suatu nama yang digunakan untuk menyimpan nilai yang dapat
berubah-ubah selama program berjalan. Sedangkan konstanta, seperti
namanya, memiliki nilai yang tetap dan tidak bisa diubah.
• Dengan demikian, baik dalam konteks matematika maupun pemrograman,
istilah yang benar adalah konstanta. Mis: Fungsi cost=FC + VCQ, dimana FC
sebagai konstanta
94.
Perbandingan: SPSS, PLSdan Manual
Prof. Dr. Dr. Aminullah Assagaf, SE., MS., MM., M.Ak
Email: assagaf29@yahoo.com
HP : +628113543409
Jakarta, 15 Juli 2023
95.
SPSS & PLS
•SPSS mengolah data real
• PLS mengolah data: Data real tiap pengamatan variable dikurangi nilai rata2 dari variable itu , kemudian
dibagi Standar deviasi
Mis: untuk Y pada PLS, diperoleh dari = y/ SDY ➔ y = (Y-Ybar)
Untuk X pada PLS, diperoleh dari = x/ SDX ➔ x = (X-Xbar)
• SDY = VarY0.5 ➔ VarY = y2/(n-1)
• SDX = VarX0.5 ➔ VarX = x2/(n-1)
•
• Jumlah (Y-Ybar) = 0, dan Jumlah (X-Xbar) = 0, maka:
- Jumlah X dan Y pada PLS =0
- Rata2 (bar) : X dan Y = 0
- Constanta atau Bo = 0 ➔ Rumus Bo = Ybar – B1(Xbar) = 0
96.
SPSS & PLS
•SPSS : mencatat (a) koefisien unstandardized, dan (b) koefisien
standardize. Sedangkan t-statistic dihitung dari koefisien
unstandardized dibagi Standar deviasi
• PLS: mencatat koefisien standardize., sedangkan t-statistic dihitung
dari koefisien standardize dibagi standar deviasi.
• Untuk data sekunder atau time series (tanpa indicator) hasil
perhitungan koefisien standardize PLS = SPSS
• Untuk data primer atau data dari questioner, koefisien berbeda
karena pada PLS dihitung dari indicator, sedangkan SPSS dihitung dari
rata-2 atau total nilai indicator tiap variable.
97.
Data SPSS danPLS (α = 0)
• SPSS mengolah data real
• PLS mengolah data: Data real tiap pengamatan variable dikurangi nilai rata2 dari variable
itu (mis: y=Y-Yrata2) , kemudian dibagi Standar deviasi (mis: y/SDY).
• SDY=
∑(Y−Yrata2)2
(𝑛−1)
, atau SDY=
∑y2
(𝑛−1)
• SDX=
∑(X−Xrata2)2
(𝑛−1)
, atau SDX=
∑ x2
(𝑛−1)
• Data Y pd PLS diperoleh dari y/SDY, dan data X diperoleh dari x/SDX
• Jumlah y atau ∑(Y-Ybar) = 0, dan Jumlah x atau ∑(X-Xbar) = 0, yang berarti bahwa:
- Pada PLS: ∑Y=0 dan ∑X =0, yang berarti rata2 Y atau Ybar=0 dan Xbar = 0
- Konstanta atau α = 0 ➔ karena formula α = Ybar – B1(Xbar) = 0
99.
SPSS
Standardized
Coefficients
B Std. ErrorBeta
(Constant) 4.565 0.751 6.078 0.000
X -0.048 0.210 -0.081 -0.231 0.823
a. Dependent Variable: Y
Coefficientsa
Model
Unstandardized
Coefficients
t Sig.
1
Untuk analisis Jalur(Standardize): Standardize
n X1 Y X-Xbar Y-Ybar xy x^2 Yest Y-Yest SD Y(Yest) (SD.Y)+Ybar Selisih Yest
x y e 0.5 4.4 Unstd-Std
1 0.51 0.86 0.511 0.858 0.439 0.261 -0.04 0.90 (0.02) 4.38 (0.01)
1 0.51 0.86 0.511 0.858 0.439 0.261 -0.04 0.90 (0.02) 4.38 (0.01)
1 0.51 0.86 0.511 0.858 0.439 0.261 -0.04 0.90 (0.02) 4.38 (0.01)
1 1.36 -0.57 1.363 (0.572) (0.780) 1.858 -0.11 -0.46 (0.05) 4.35 (0.02)
1 1.36 -0.57 1.363 (0.572) (0.780) 1.858 -0.11 -0.46 (0.05) 4.35 (0.02)
1 -0.34 -0.57 (0.341) (0.572) 0.195 0.116 0.03 -0.60 0.01 4.41 0.01
1 -0.34 -2.00 (0.341) (2.002) 0.682 0.116 0.03 -2.03 0.01 4.41 0.01
1 -1.19 -0.57 (1.193) (0.572) 0.682 1.423 0.10 -0.67 0.05 4.45 0.02
1 -1.19 0.86 (1.193) 0.858 (1.023) 1.423 0.10 0.76 0.05 4.45 0.02
1 -1.19 0.86 (1.193) 0.858 (1.023) 1.423 0.10 0.76 0.05 4.45 0.02
10 - (0) - - (0.73) 9.00 (0) - (0) 44 (0)
Xbar - b = xy/x^2 = -0.081
Ybar (0.00) a = Ybar - b(Xbar) = 0.00 CATATAN :
- UTK ESTIMASI HASILNYA SAMA ANTARA
Xstd = (X - Xbar)/SD, sehingga untuk mengembalikan ke X maka : STANDIZE DENGAN UNSTANDARDIZE
=> Xstd dikalikan SD, misalnya 0,86 x SD = 0,86 x 8,4 = -1.4 - Formulanya :
=> jadi (X - Xbar ) = 7,2 (1) Standardise : (Yest x SDY) + Ybar
=> jika Xbar = 33,8 maka X = Xbar + 7,2 = 2 Yest : standardize
SDY : SD dari Y unstandardize
Ybar : Y rata2 dari unstandardize
(2) Unstandardize : Yest
103.
SPSS
Standardized
Coefficients
B Std. ErrorBeta
(Constant) 4.565 0.751 6.078 0.000
X1 -0.048 0.210 -0.081 -0.231 0.823
PLS
bo
b1
Prediksi S
a. Dependent Variable: Y
Coefficients
a
Model
Unstandardized
Coefficients
t Sig.
1
104.
Beta_Unstd SPSS_Pred Beta-StdPLS-Pred
bo 4.565 4.565 0 0
b1 -0.048 -0.194 -0.081 -0.162
Prediksi SPSS: Y (X=2)= 4.4 -0.162 Prediksi PLS Pers
Realisasi Y th 10 ========> 5 -0.114 kali SDY 0.699
Prediksi PLS Y ( X=2) ========> 4.3 plus rt2 Y 4.4
PREDIKSI SPSS & PLS (bila X=2))
Standardized
Coefficients
B Std. ErrorBeta
(Constant) 6.401 1.666 3.841 0.006
X1 0.115 0.244 0.194 0.474 0.650
X2 -0.725 0.592 -0.501 -1.225 0.260
1
a. Dependent Variable: Y
Coefficientsa
Model
Unstandardized
Coefficients
t Sig.
SPSS
PLS
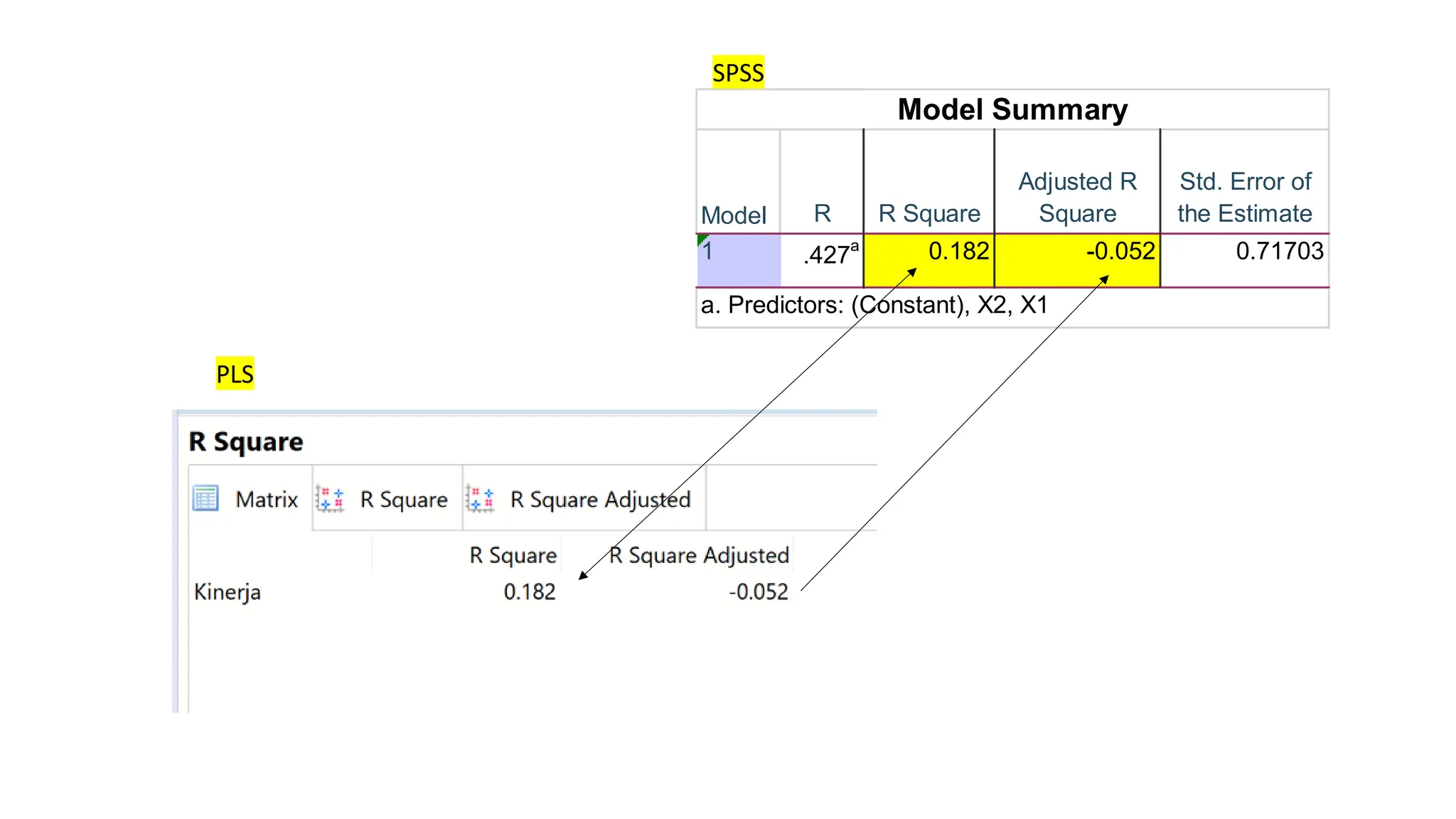
109.
R R Square
AdjustedR
Square
Std. Error of
the Estimate
1 .427
a
0.182 -0.052 0.71703
Model Summary
Model
a. Predictors: (Constant), X2, X1
PLS
SPSS
110.
Y X1 X2
Pears
on
1-0.081 -0.395
Sig. (2-
tailed)
0.823 0.259
N 10 10 10
Pears
on
-0.081 1 0.549
Sig. (2-
tailed)
0.823 0.100
N 10 10 10
Pears
on
-0.395 0.549 1
Sig. (2-
tailed)
0.259 0.100
N 10 10 10
Correlations
Y
X1
X2
PLS SPSSS
111.
Beta_Unstd
SPSS_Pred
Beta-Std PLS-Pred
bo 6.4016.401 0 0
b1 0.115 0.462 0.194 0.775
b2 -0.725 -2.176 -0.501 -1.503
Prediksi SPSS: Y (X1=4, X2=3)=
4.7 -0.728 Prediksi PLS
Realisasi Y th 10 ========>5 -0.509 kali SDY 0.699
Prediksi PLS Y ( X1=2, X2=3) ========>
3.9 plus rt2 Y 4.4
PREDIKSI SPSS & PLS (bila X1=4 dan X2=3)
Standardized
Coefficients
B Std. Error Beta
(Constant) 6.401 1.666 3.841 0.006
X1 0.115 0.244 0.194 0.474 0.650
X2 -0.725 0.592 -0.501 -1.225 0.260
a. Dependent Variable: Y
Coefficientsa
Model
Unstandardized
Coefficients
t Sig.
1
Keunggulan & KeterbatasanSPSS dibanding
PLS
1. Hasil perhitungan coefficient regresi terdiri dari (a) Unstandardize
coefficient Beta, dan (b) Standardize coefficient Beta
2. Unstandardize coefficient digunakan secara langsung dalam perhitungan
prediksi variable dependent bila terjadi perubahan variable independent
3. Uji asumsi klasik regresi linear, tersedia (a) multicollinearity, (b)
Autocorrelation, (c)Hetersocedasticity, (d) Linearity, dan (e) Normality
4. Uji variable intervening, dihitung secara terpisah diluar sistem SPSS, mis:
Sobel Test, Peth test.
5. Model structural disajikan terpisah melalui AMOS, dll
114.
Keunggulan dan KeterbatasanPLS dibanding SPSS
1. Hasil perhitungan coefficient regresi hanya Standardize coefficient Beta,
sedangkan Coefficient regresi Unstandardize Beta belum tersedia
2. Standardize coefficient Beta tidak dapat digunakan secara langsung
dalam membuat prediksi. Proses prediksi menggunakan dengan koefisien
tsb, kemudian dikali standar deviasi data real, dan ditambah rata-rata
data real.
3. Hasil perhitungan dilengkapi dengan : (a) model structural dan koefisien,
melalui PLS Algorithm, dan (b) model structural dan t-statistics, melalui
Blootstrapping
4. Tersedia asumsi klasik regresi linaer Collinearity, sedangkan asumsi
lainnya belum tersedia (Autocorrelation, Hetersocedasticity, Linearity,
dan Normality)
5. Uji variable intervening dihitung dalam sistem aplikasi PLS, dll
KESIMPULAN
1) SPSS menggunakandata real sesuai pengamatan atau riset dilapangan
2) Formula perhitungan regresi SPSS dan PLS adalah sama, yg berbeda hanya pada data yang dioleh untuk
menghasilkan koefisien variabel independent. Hal ini telah dibuktikan dengan perhitungan manual
dibanding hasil perhitungan dari SPSS dan PLS.
3) Smart PLS atau SEM menggunakan data dari: selisih antara data pengamatan dengan rata2 total
pengamatan (mis: Y – Ybar, X1 – X1bar…dst), kemudian dibagi standar deviasi variabel tsb (mis: SDY,
SDX1…dst)
4) Selisih antara data pengamatan dengan rata2 total pengamatan, jumlahnya nol dan rata2 nol, sehingga
data yg diolah PLS seperti butir 3 diatas, menghasilkan konstanta nol. Konstanta dihitung dari rata-rata
variabel dependen Y dikurangi (koefisien kali rata-rata variabel independent Xi), sehingga nilai konstanta
nol.
5) Koefisien dari PLS tidak dapat digunakan untuk prediksi secara langsung, tetapi harus dikembalikan
perhitungannya, yaitu hasil prediksi Y yang diperoleh dari perkalian koefisien variabel independent Xi
dikali data prediksi Xi menghasilkan nilai yang tidak sesuai prediksi sebagaimana perhitungan SPSS.
6) Prediksi Y sebagaimana butir 5, kemudian dikalikan dengan standar deviasi Y (SDY), dan ditambahkan
nilai rata-rata Y. Hasilnya mendekati perhitungan prediksi SPSS dan relevan dengan kondisi empiris,
terutama bila diuji dengan angka realisasi dengan asumsi dipakai pada prediksi periode sebelumnya.
117.
KESIMPULAN
7) Perhitungan SPSSdan PLS memiliki kesamaan dalam formula perhitungan koefisien regresi. Hasil
perhitungan coefficients SPSS menunjukkan koefisien Unstandardized (menggunakan data real) dan
koefisien Standardized (menggunakan data sebagaimana butir 3) dengan hasil yang sama dengan PLS
8) Model SPSS dan PLS dapat digunakan untuk prediksi dengan hasil yang hampir sama, bila menggunakan
data realisasi dengan asumsi prediksi pada periode sebelumnya.
9) Perbandingan perhitungan manual, SPSS, PLS adalah penting dipahami oleh mahasiswa atau peneliti
yang menggunakan PLS untuk menjelaskan perbedaan hasil perhitungan dan menggunakannya pada
kebijakan terhadap variabel independent Xi yang berdampak terhadap variabel dependen Y.
10) Koefisien regresi dari PLS tidak dapat digunakan secara langsung untuk melakukan prediksi variabek
dependen Y, tetapi harus mengembalikan perhitungannya dengan cara kalikan dengan standar deviasi Y,
kemudian tambahkan nilai rata2 total Y, sebagaimana butir 3 diatas.
11) Hal ini juga dapat digunakan untuk menjelaskan hasil dan pembahasan pada hasil penelitian yang
menggunakan PLS. Bila menggunakan secara langsung maka hasilnya menjadi tidak rasional, dan sangat
signifikan perbedaannya dengan prediksi SPSS maupun kondisi empiris sesuai data hasil penelitian.
118.
Kesimpulan
▪ Perbedaan utamaantara SEM (Structural Equation Modeling) yang menggunakan PLS
(Partial Least Squares) dan Lisrel terletak pada pendekatan pemodelan dan asumsi yang
mendasarinya.
▪ PLS-SEM lebih fleksibel, cocok untuk model kompleks dan data yang tidak memenuhi
asumsi normalitas.
▪ Lisrel - SEM berbasis kovarian, lebih cocok untuk pengujian teori dan membutuhkan data
yang memenuhi asumsi normalitas.
▪ CB SEM adalah singkatan dari Covarians Based Structural Equation Modelling yaitu model
analisis struktural yang menggunakan basis covarians, dimana berbeda dengan analisis
yang berbasis varians seperti Partial Least Square (PLS).
▪ Secara garis besar metode SEM dapat digolongkan menjadi dua jenis:
1) SEM berbasis kovarian atau Covariance Based Structural Equation Modeling (CB-SEM),
2) SEM berbasis varian atau komponen yaitu Variance atau Component Based SEM (VB-SEM) yang
meliputi Partial Least Square (PLS) dan Generalized Structural Component Analysis (GSCA).