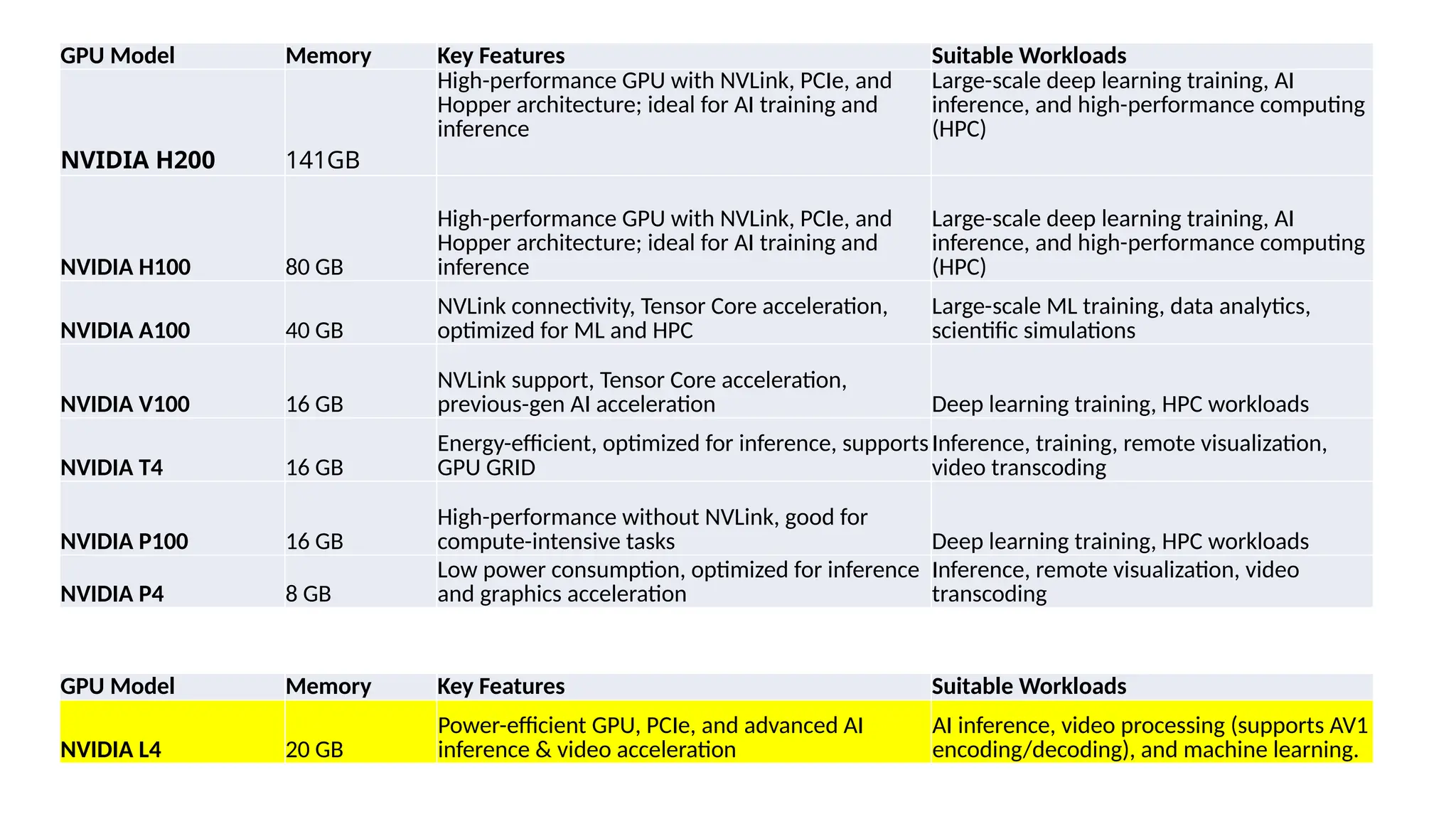
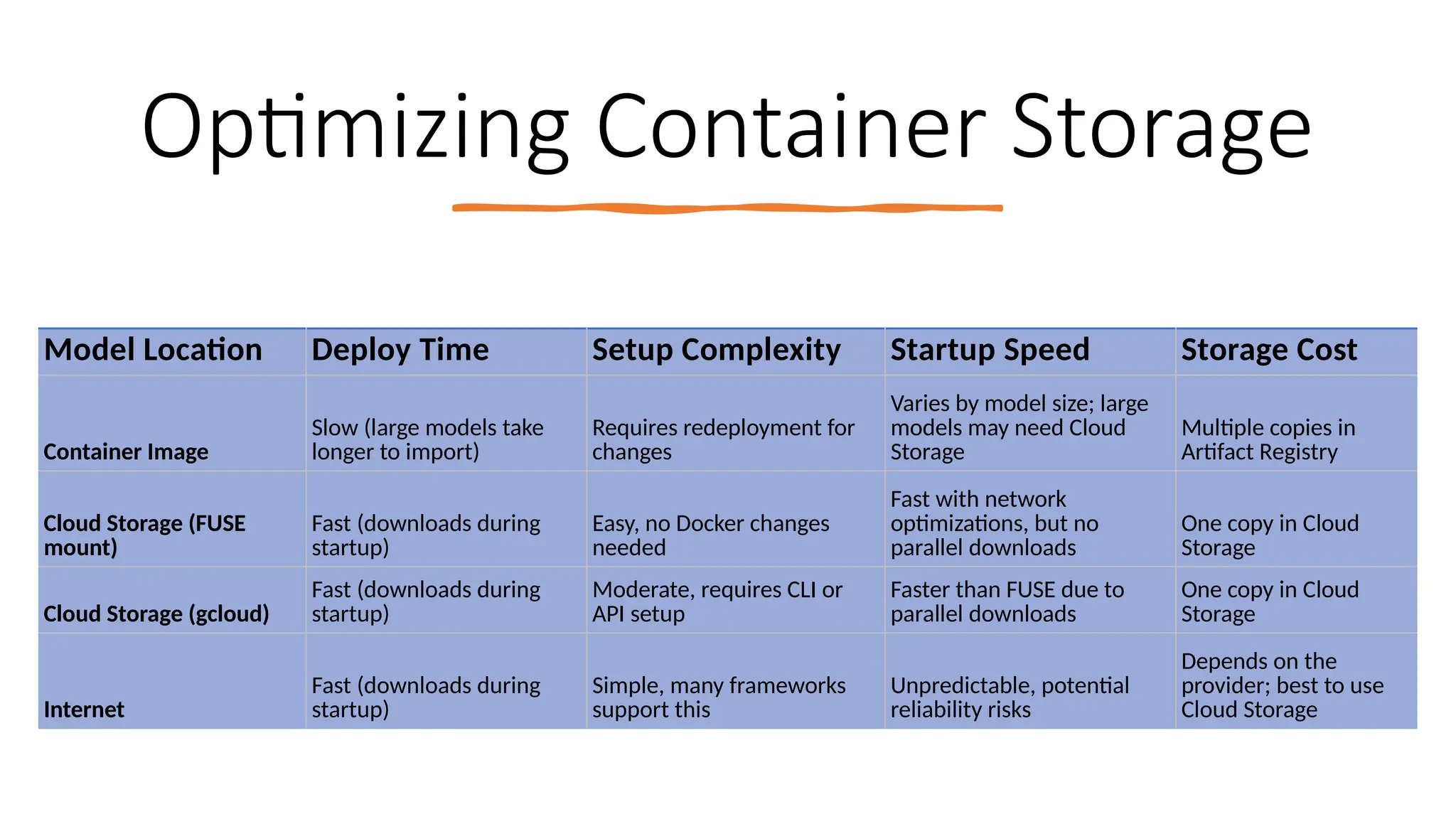
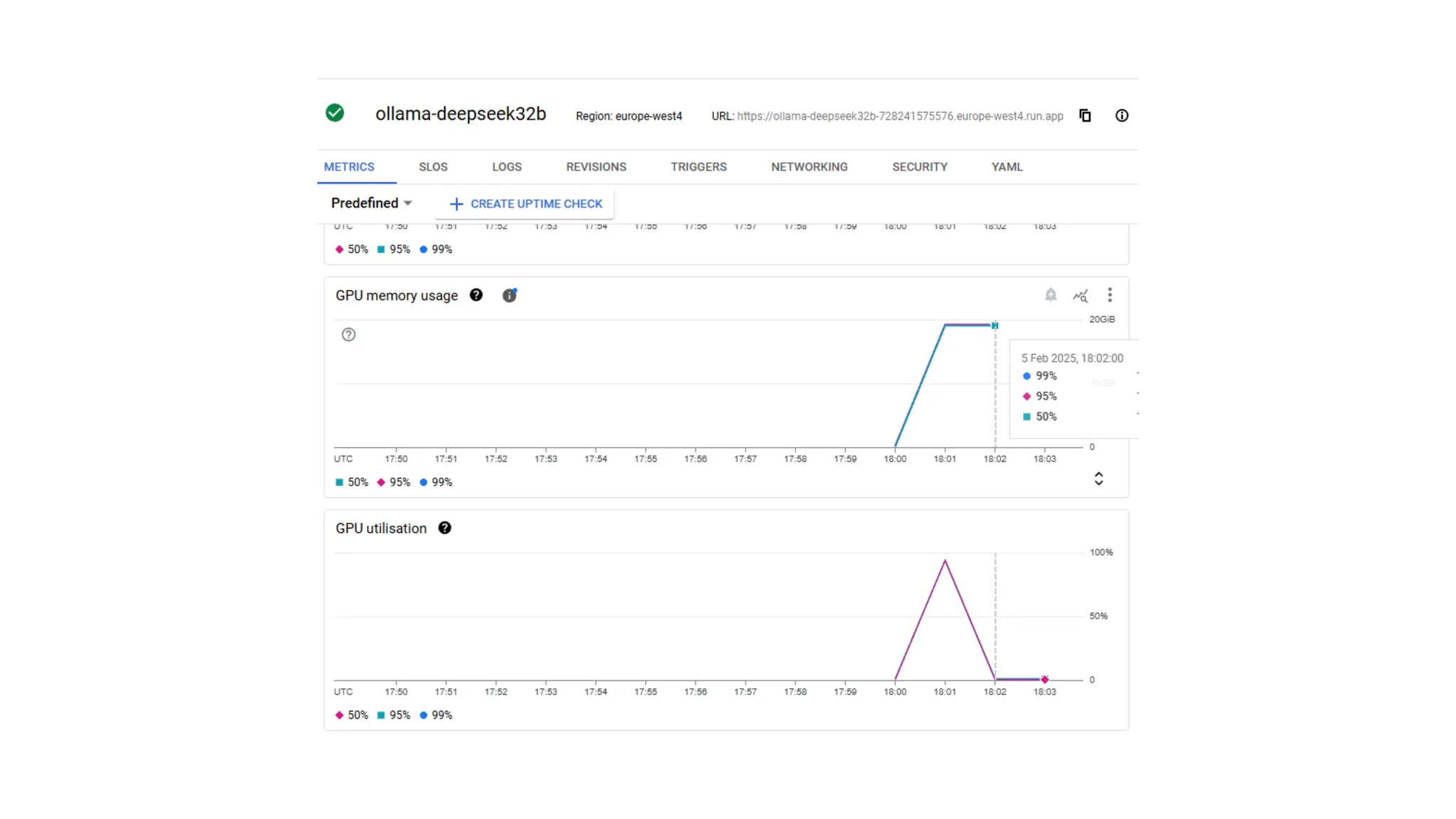
Google has introduced NVIDIA L4 GPUs with 20GB memory for Cloud Run instances in public preview, enabling optimized AI workloads and video processing. The GPUs offer on-demand availability, auto-scaling to zero for cost efficiency, and support various AI and machine learning applications. Additionally, the document discusses practical demos, challenges, and relevant resources for utilizing these GPUs effectively.






















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















