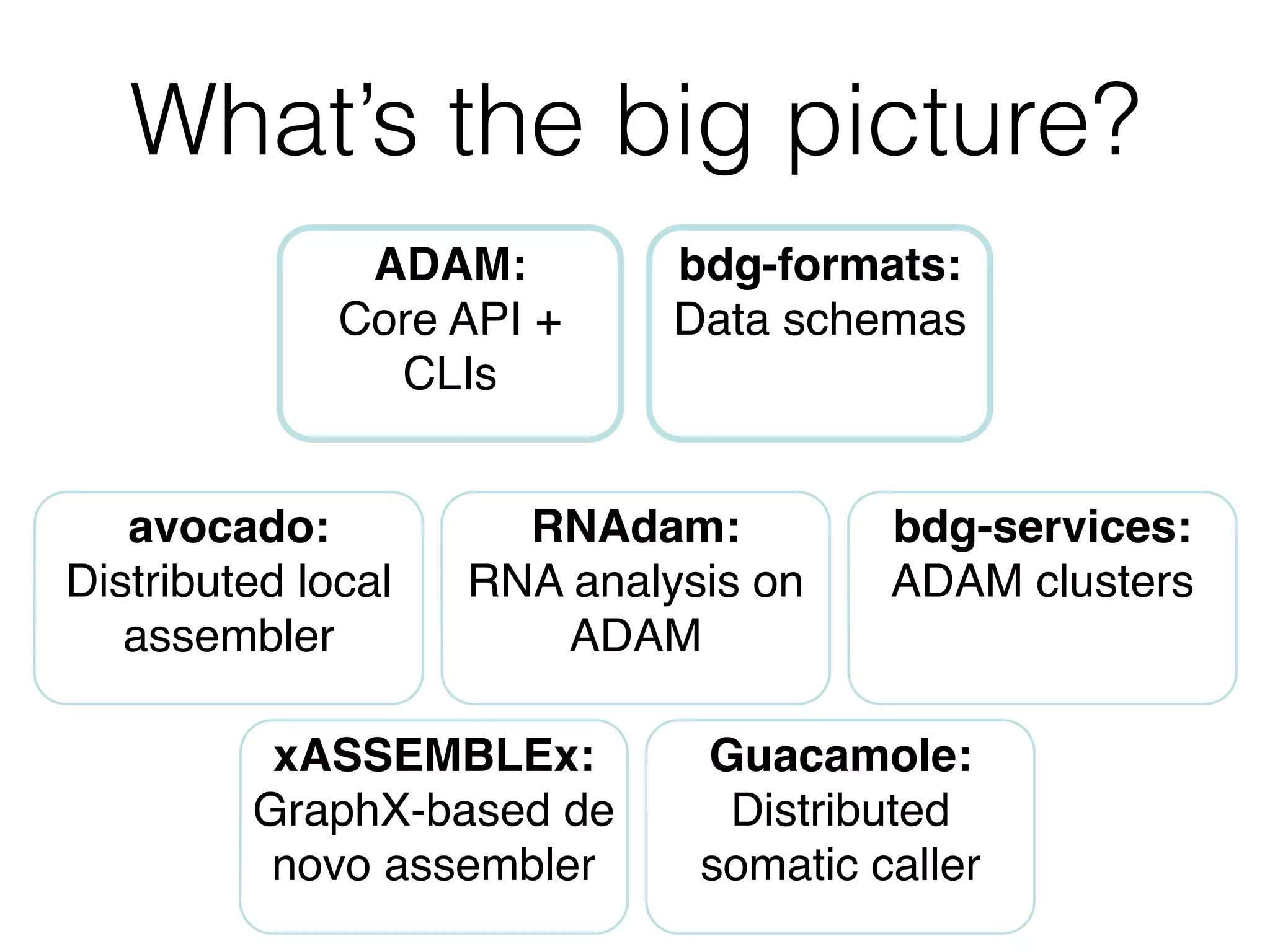
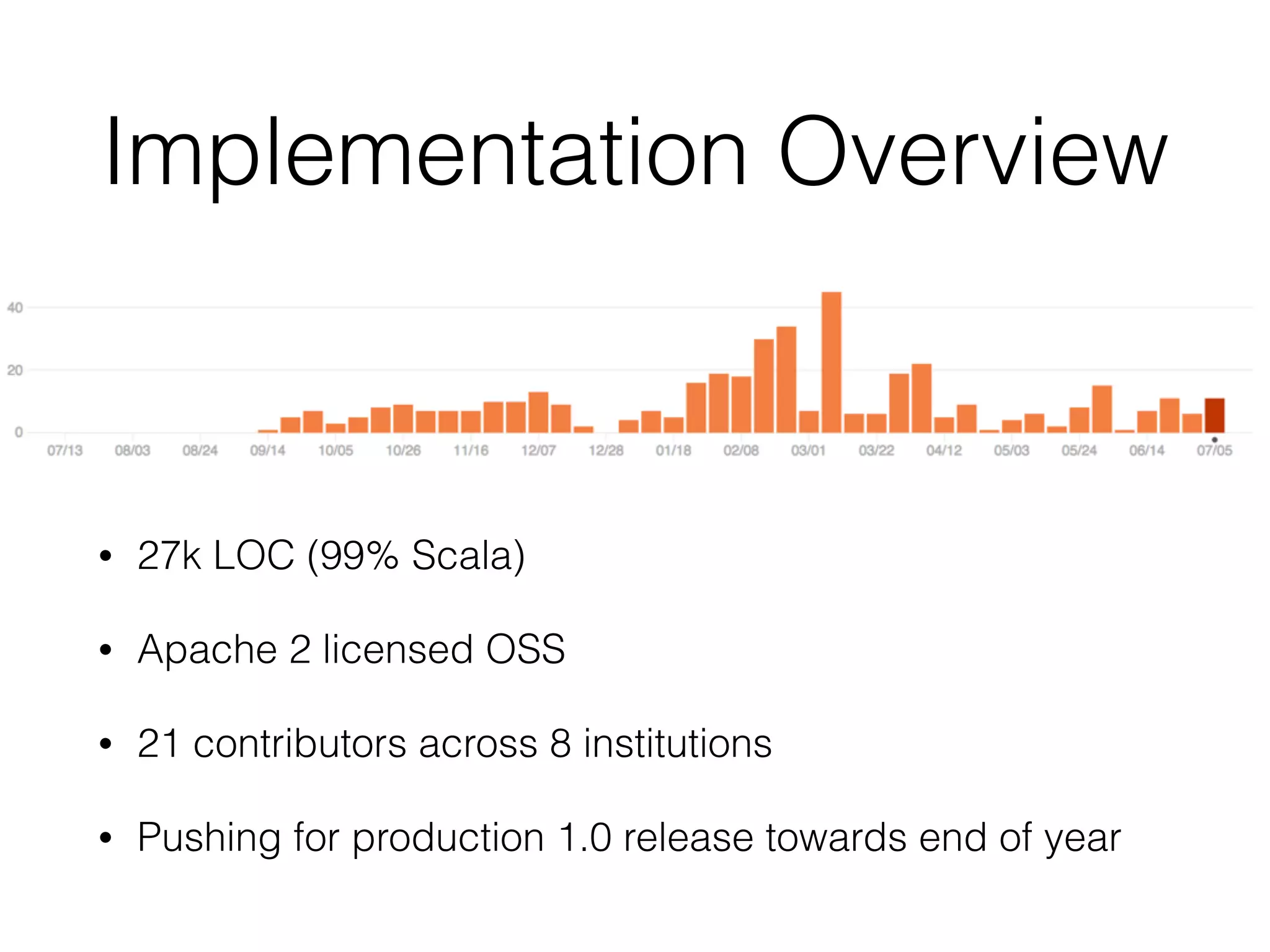
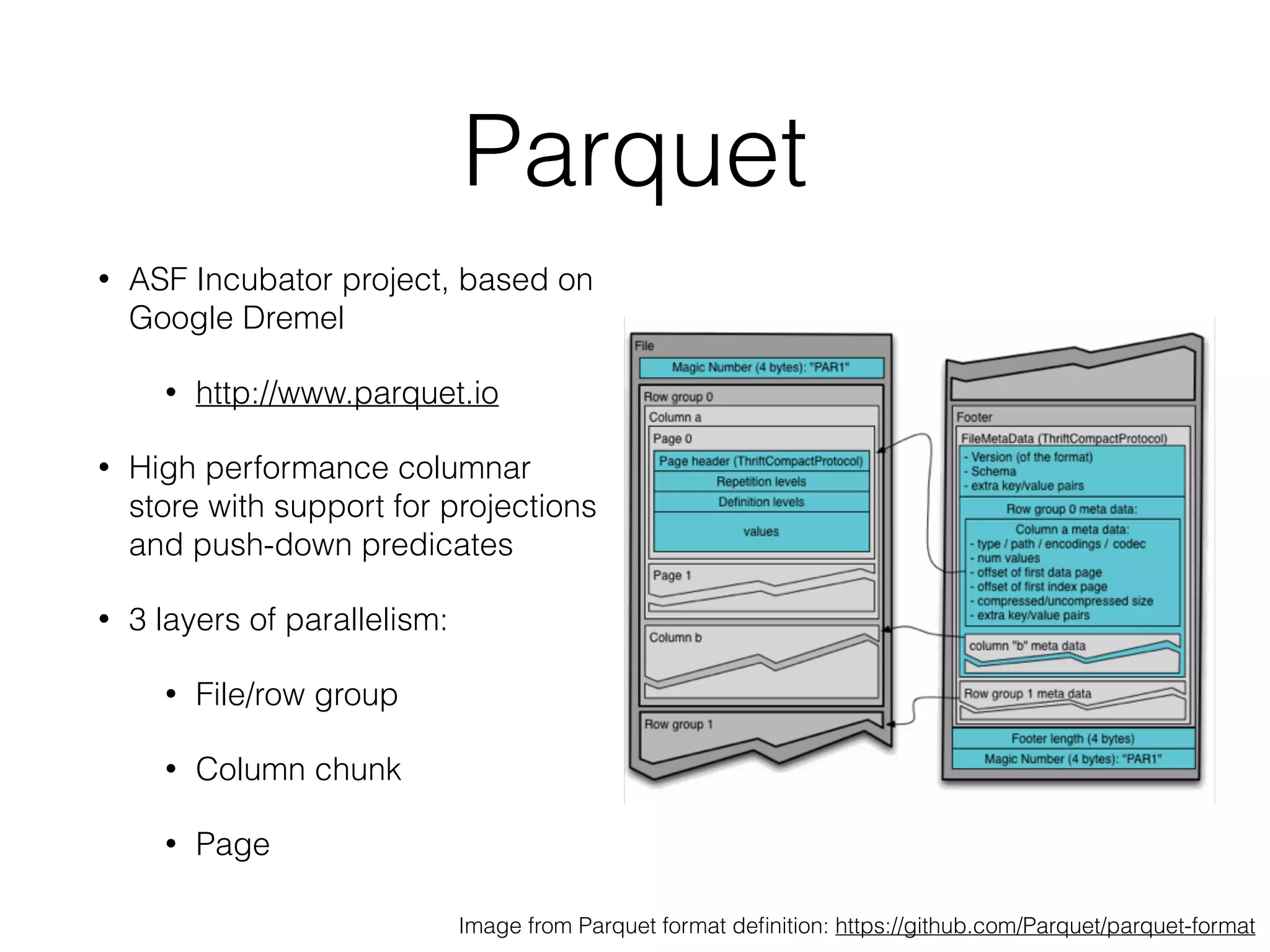
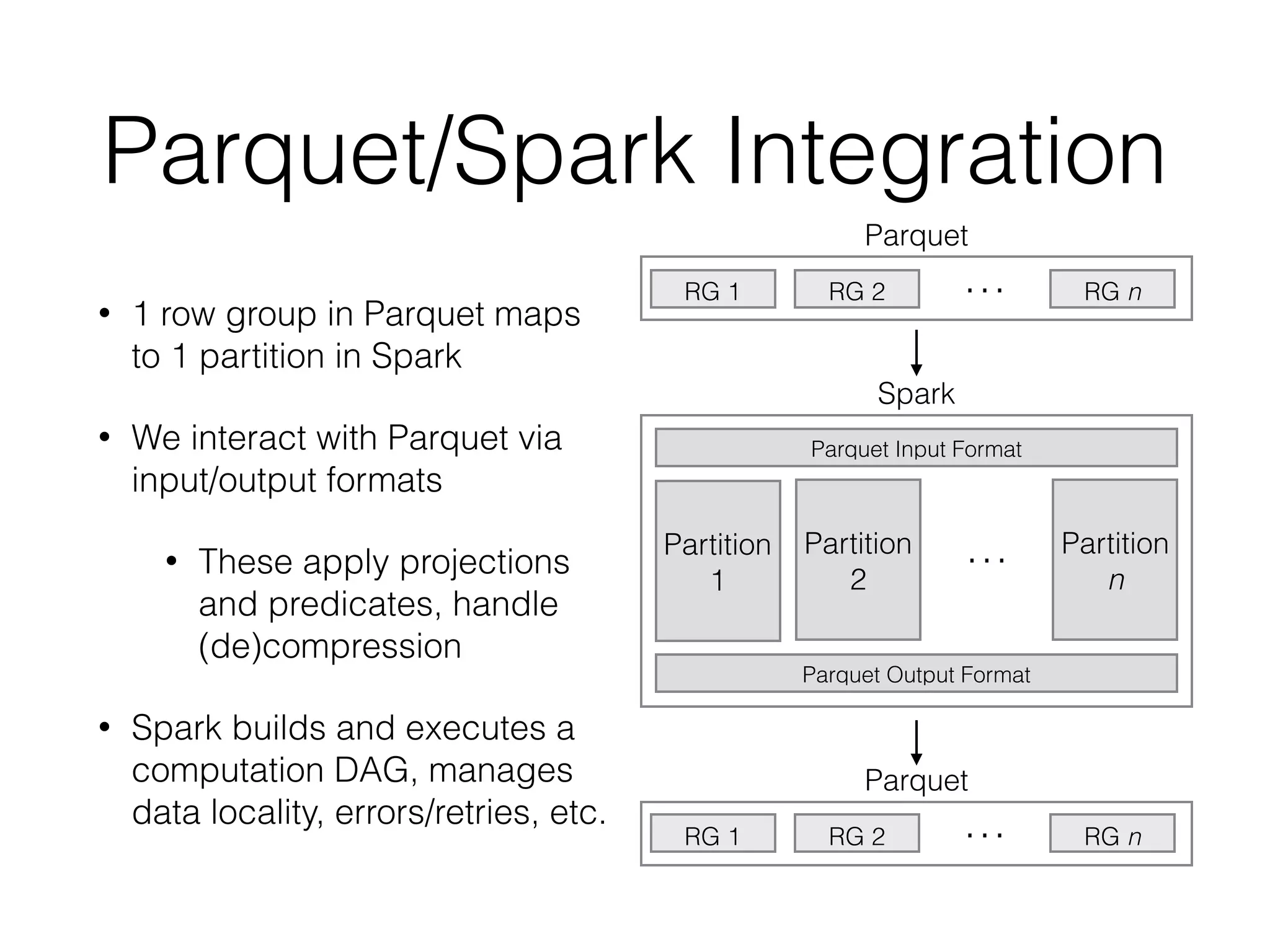
ADAM is an open source, high performance, distributed platform for genomic analysis built on Apache Spark. It defines a Scala API and data schema using Avro and Parquet to store data in a columnar format, addressing the I/O bottleneck in genomics pipelines. ADAM implements common genomics algorithms as data or graph parallel computations and minimizes data movement by sending code to the data using Spark. It is designed to scale to processing whole human genomes across distributed file systems and cloud infrastructure.