Downloaded 410 times






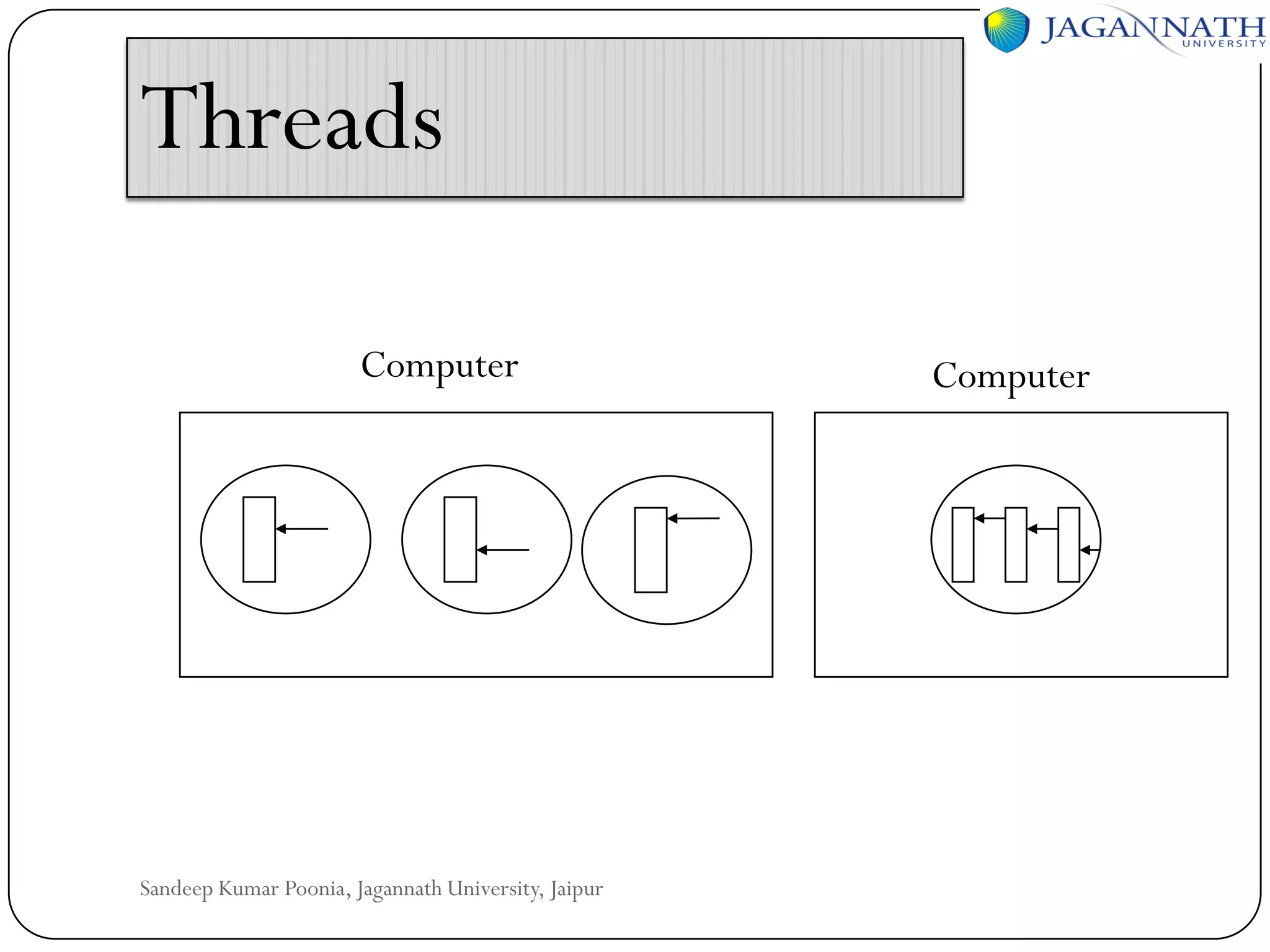
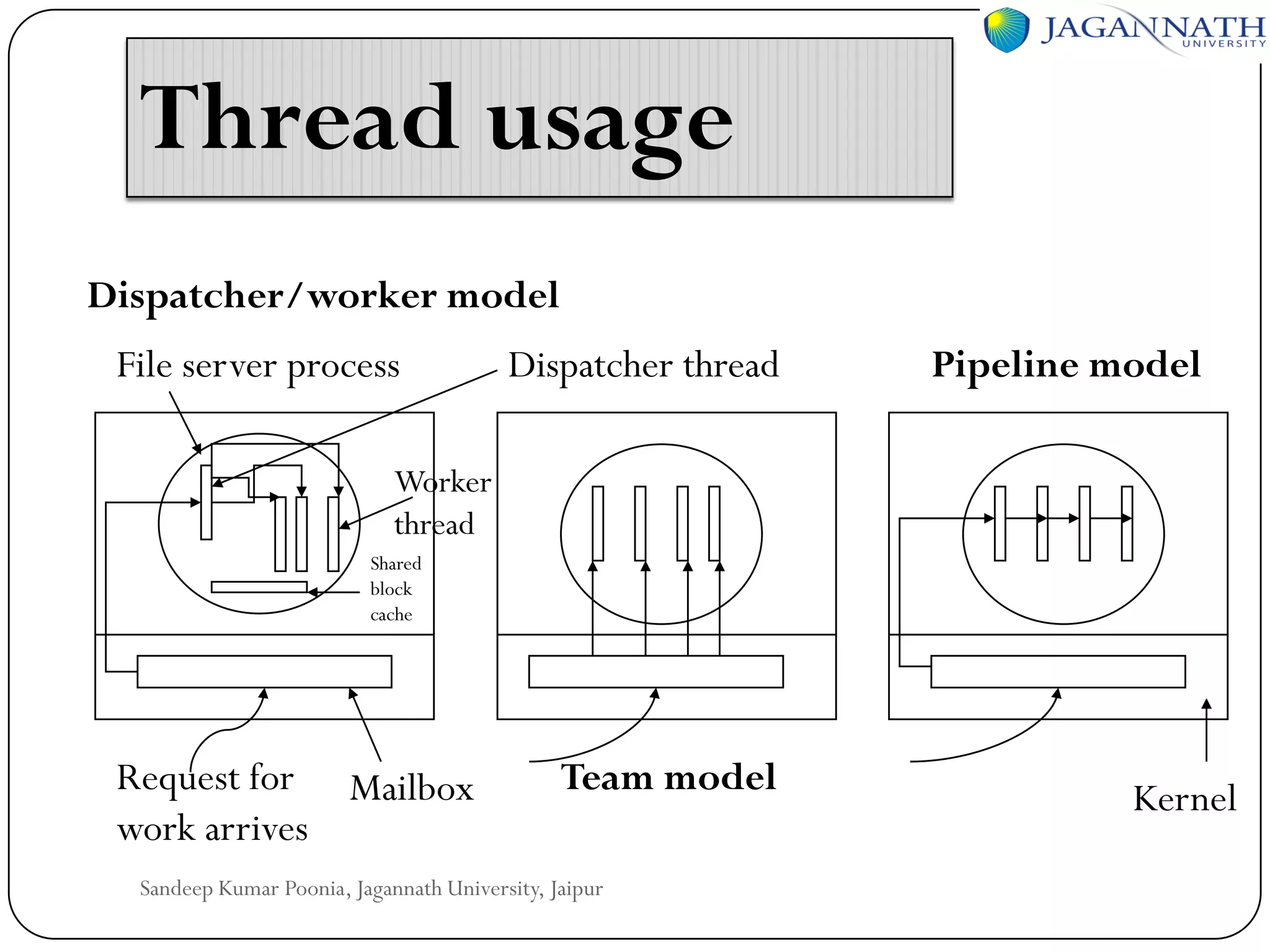



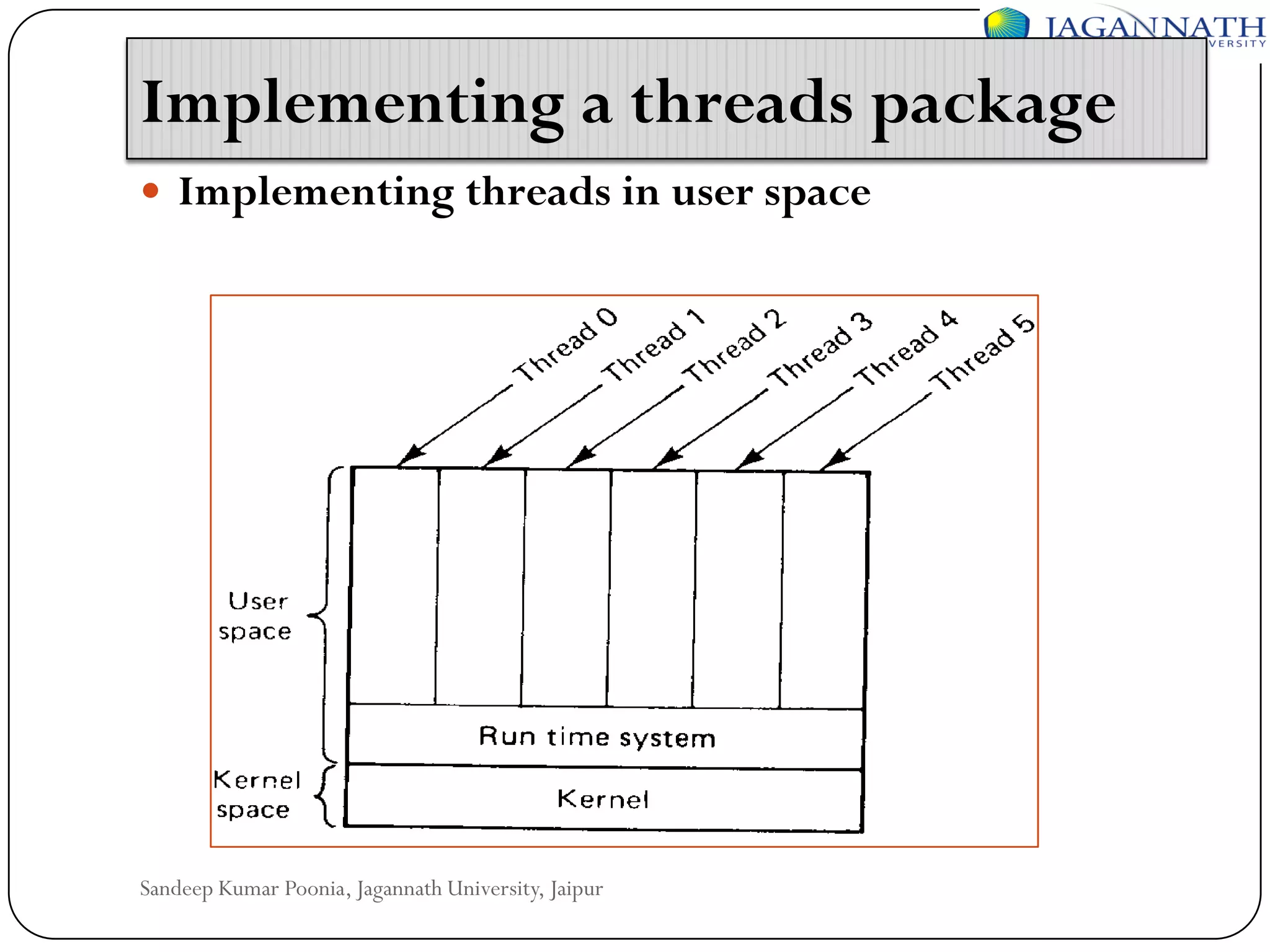

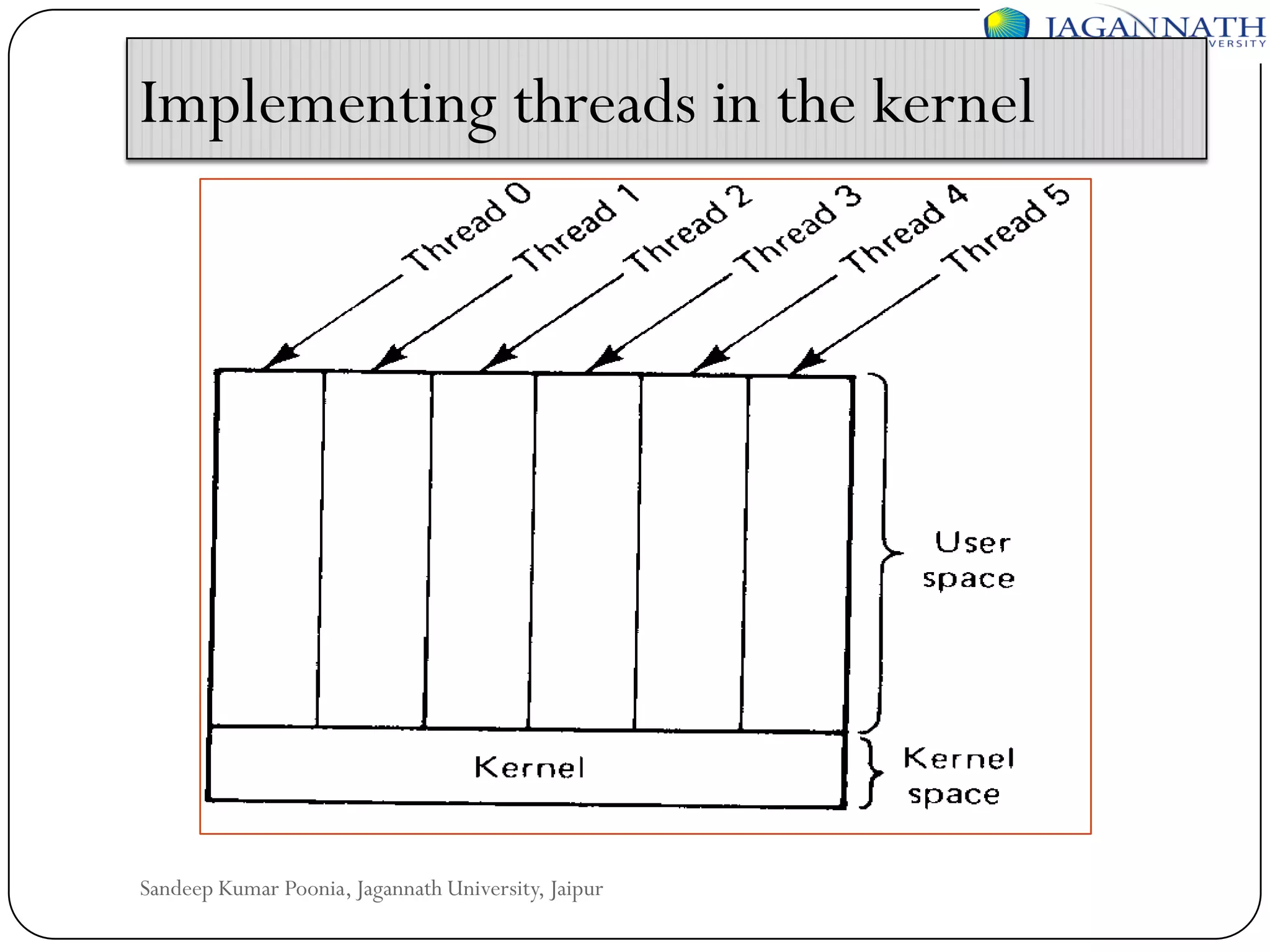








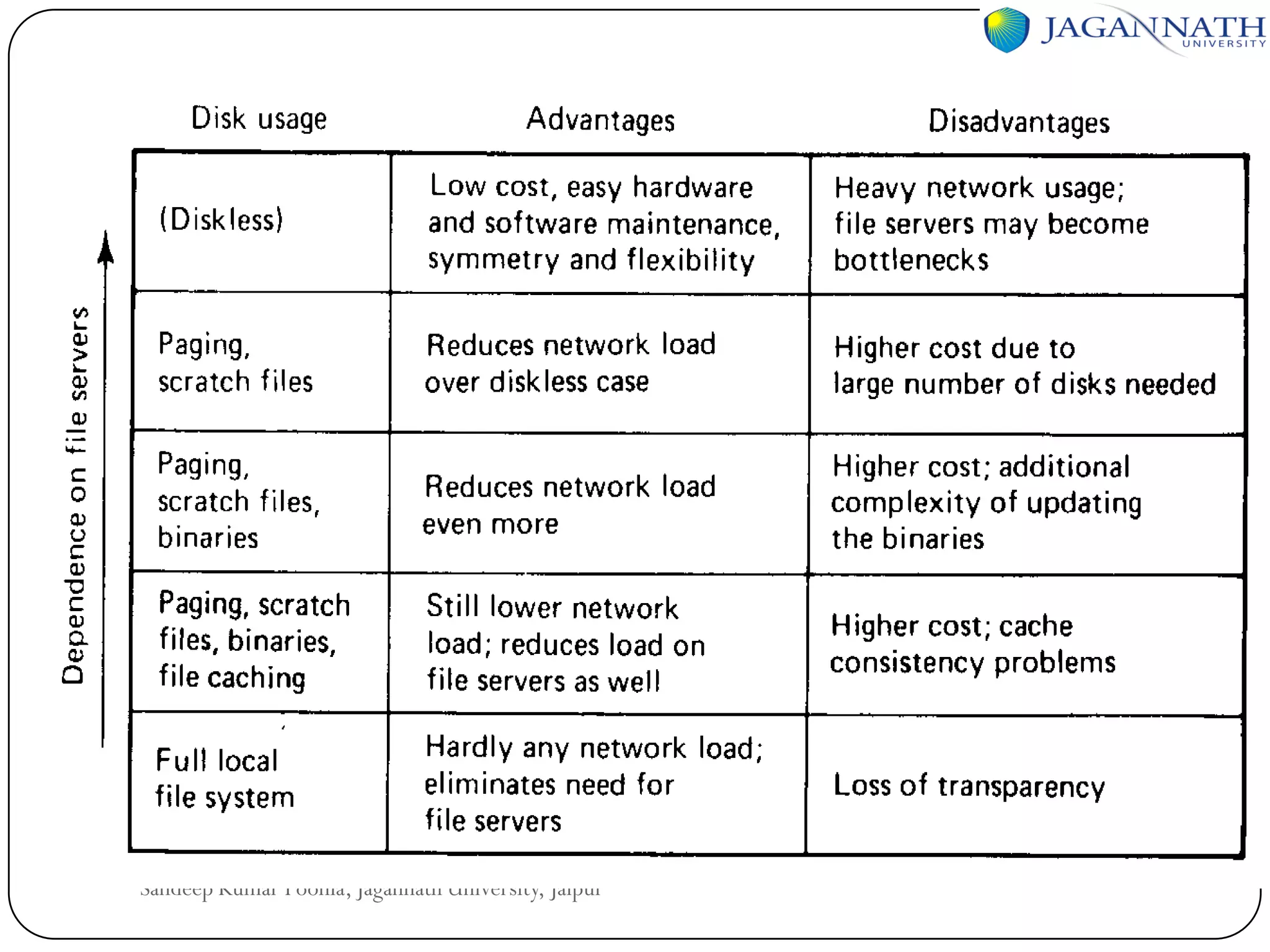



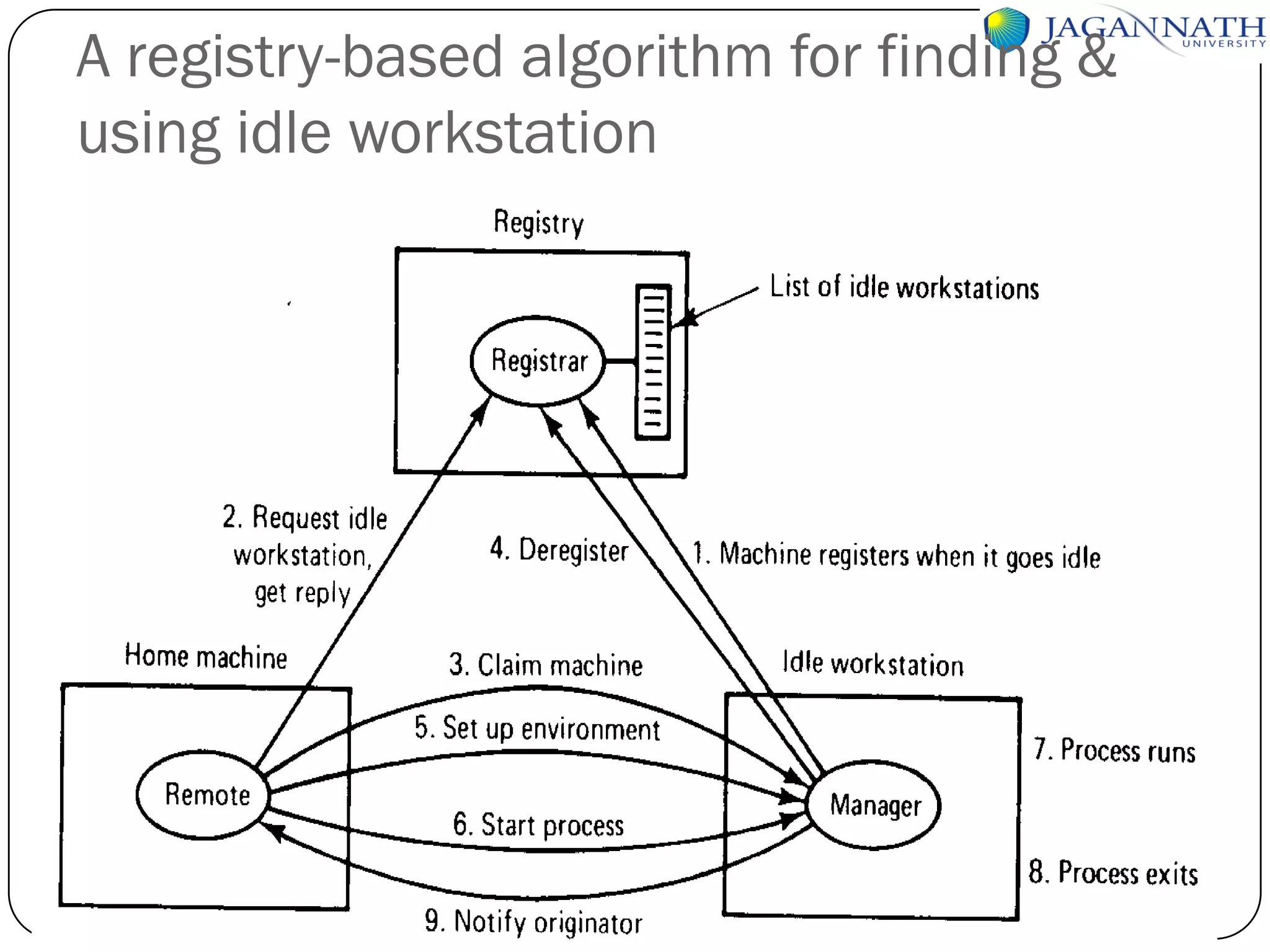

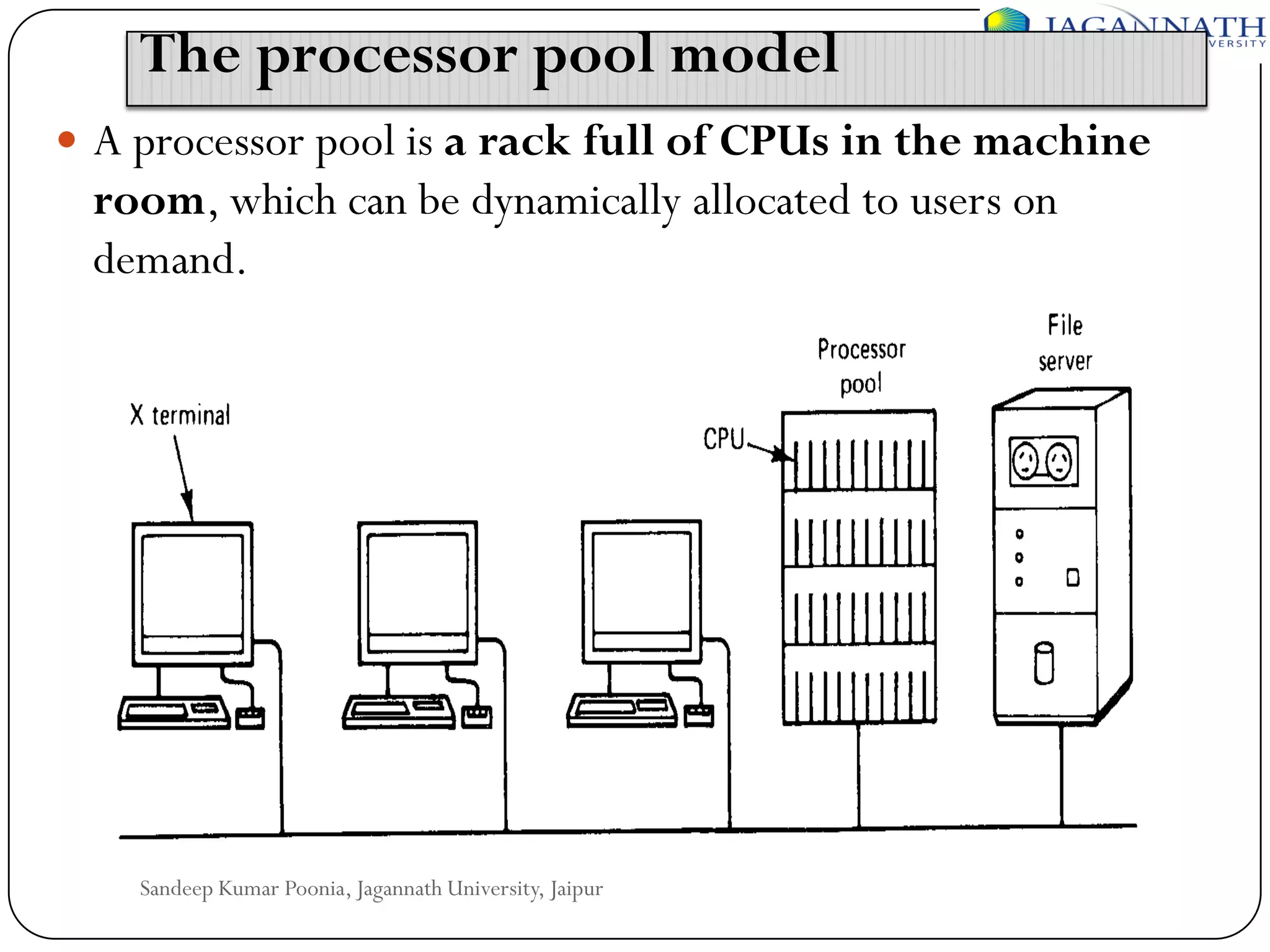
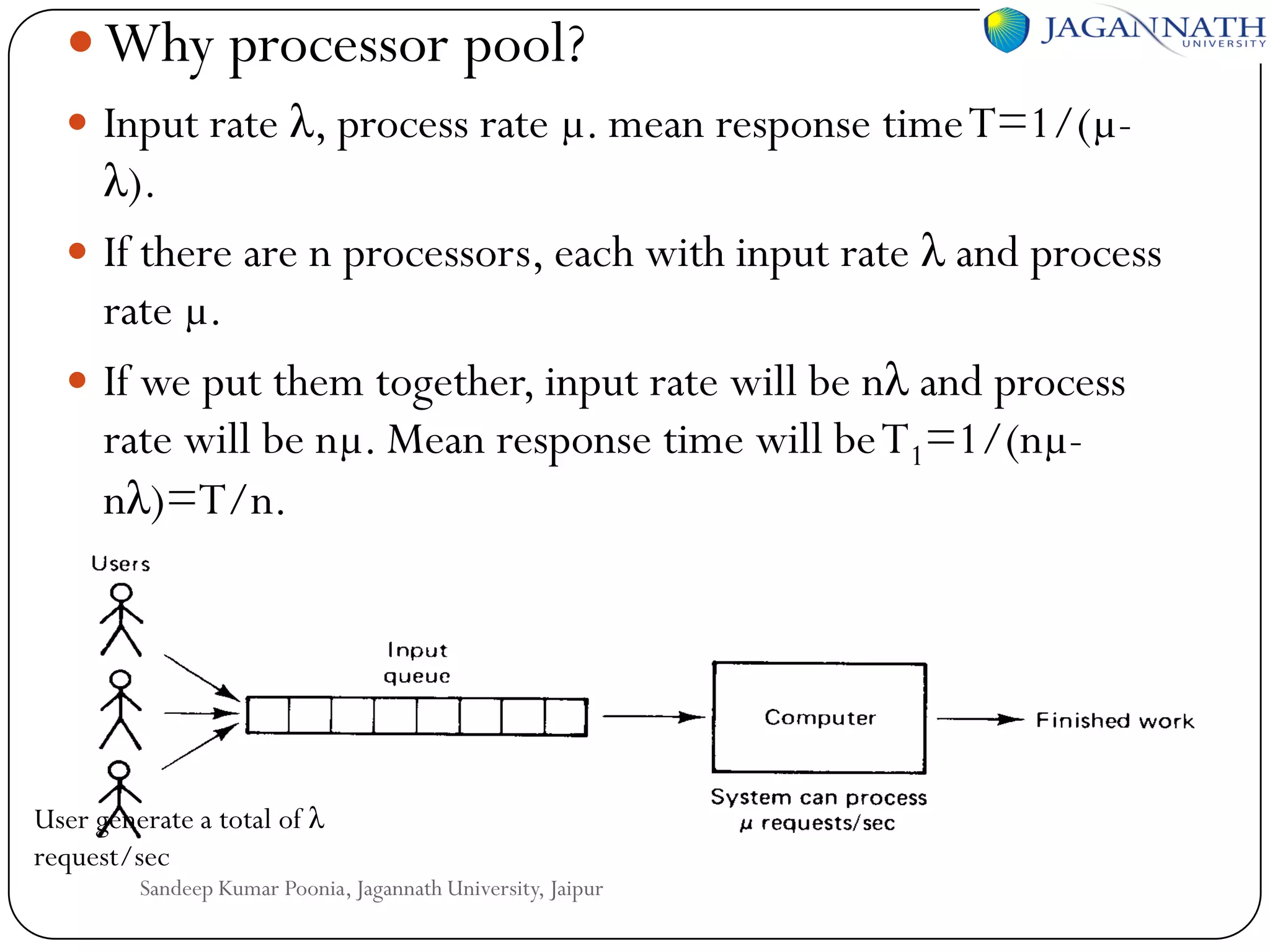



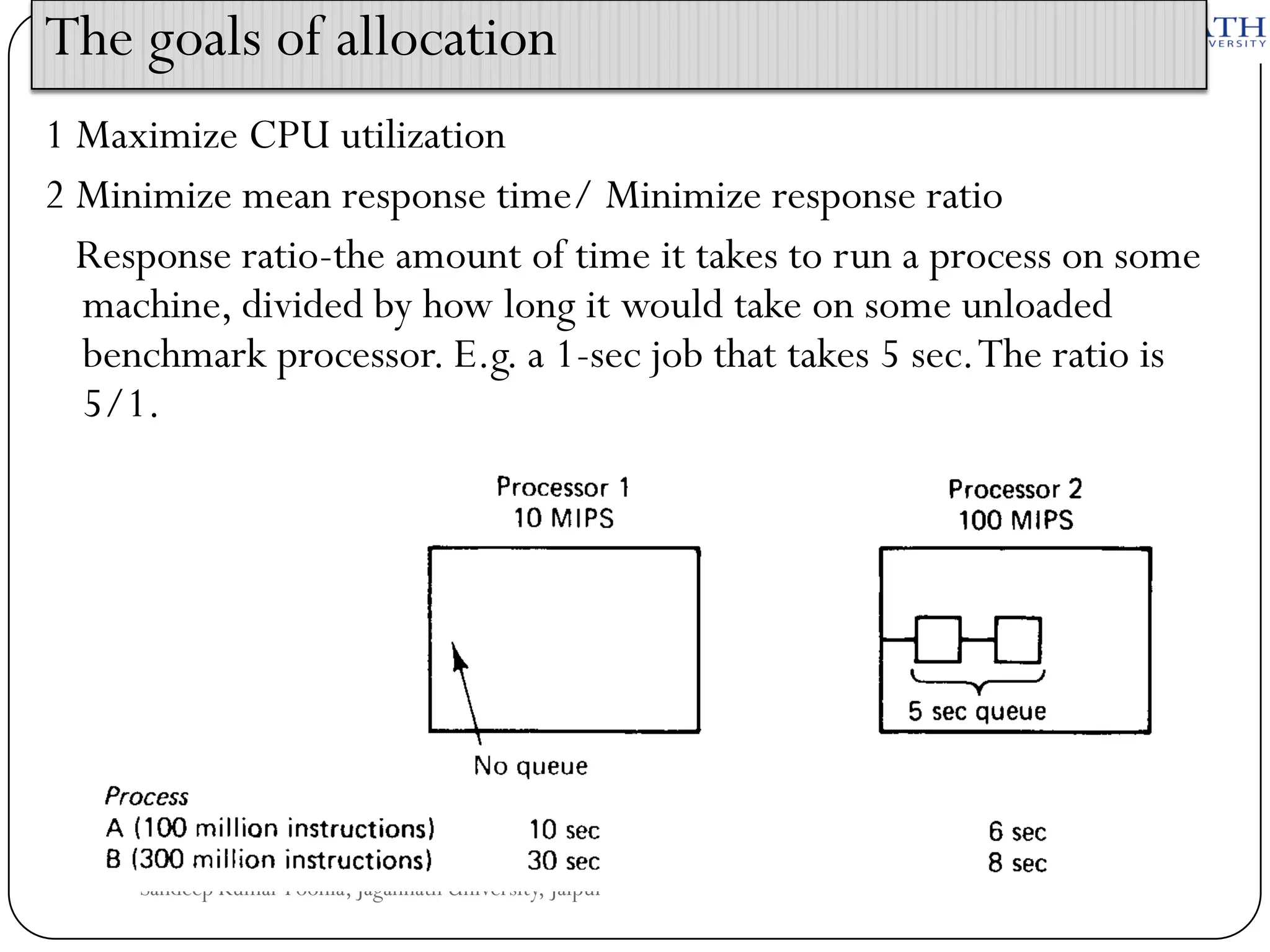



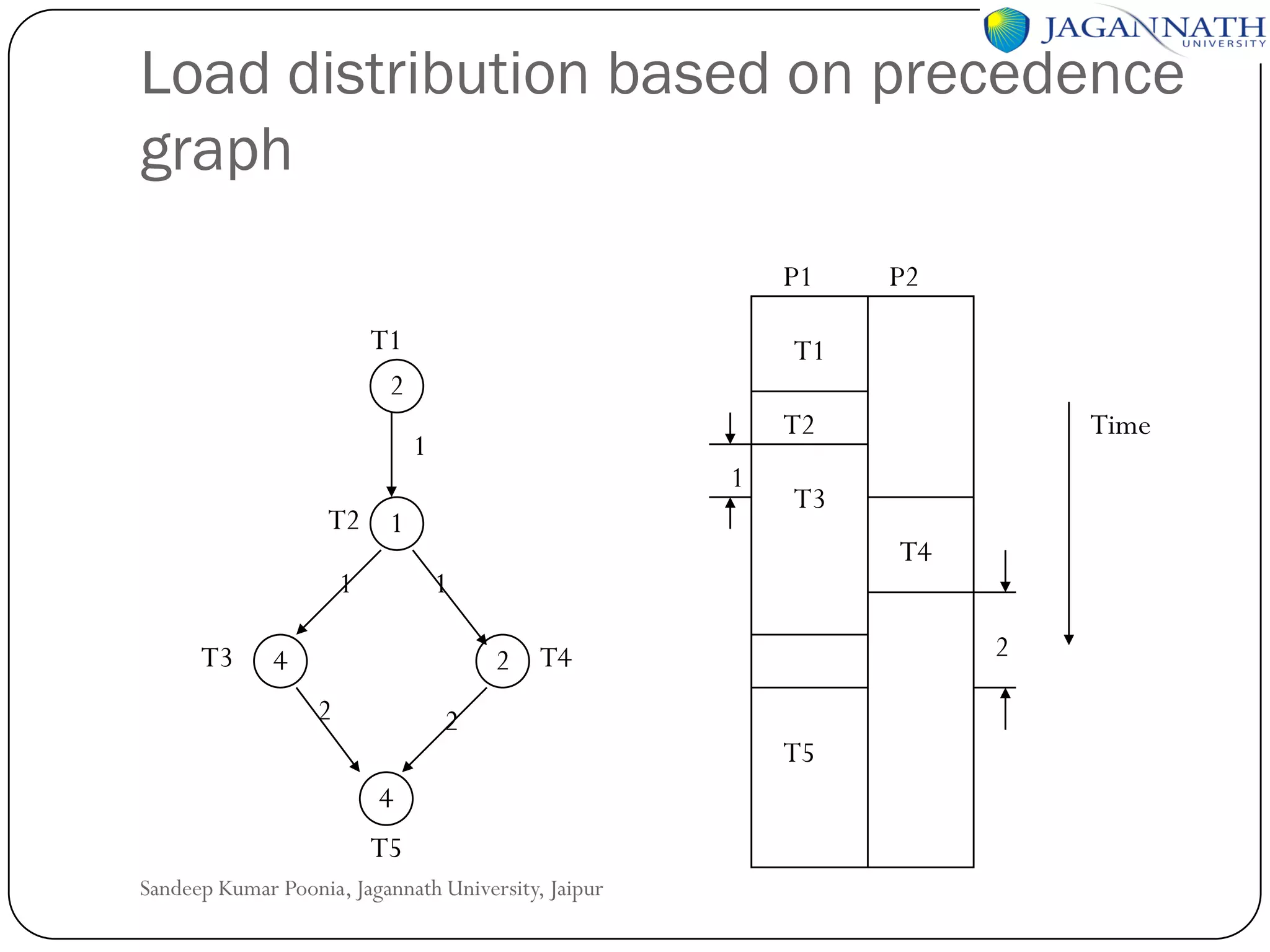
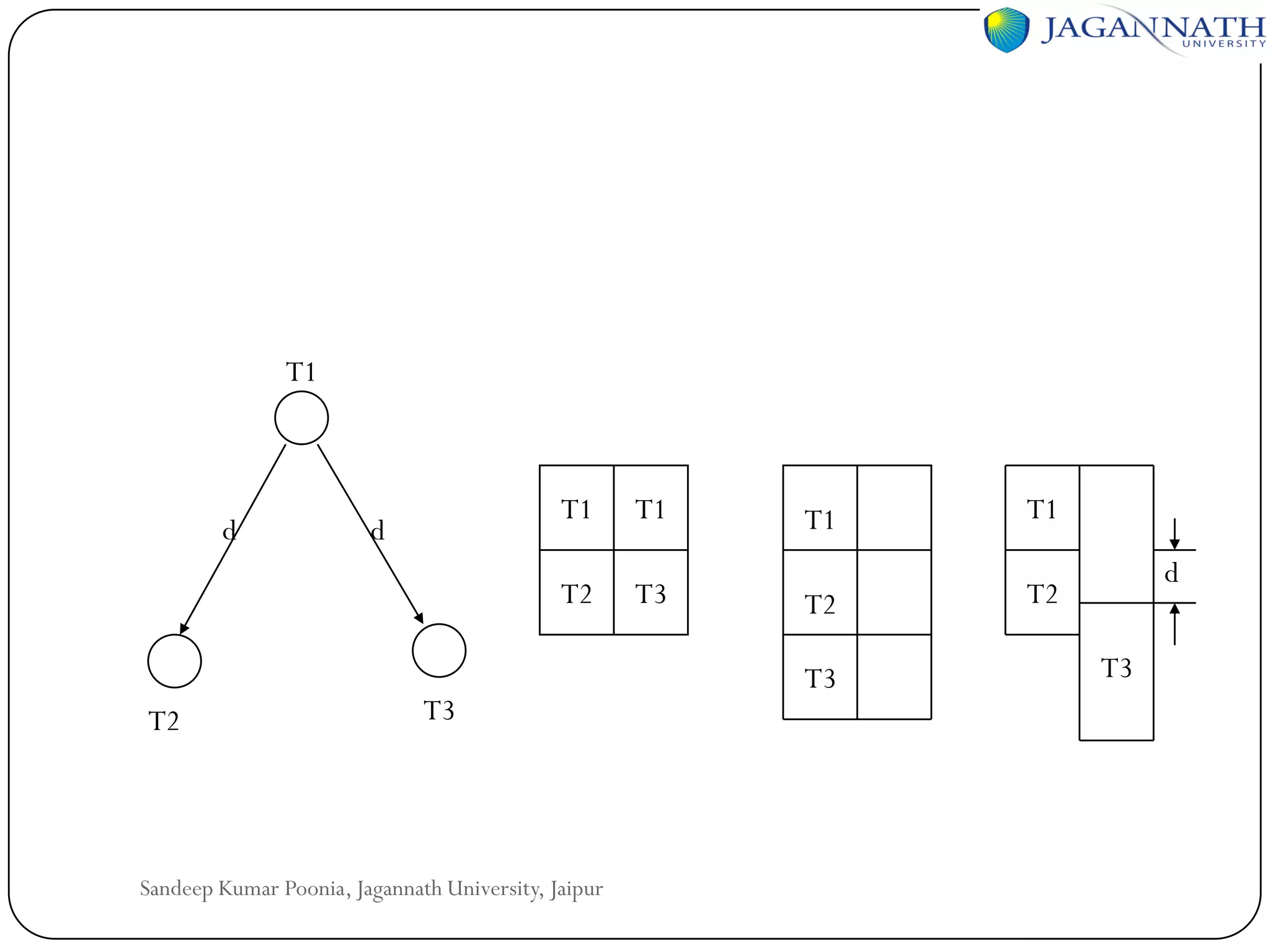
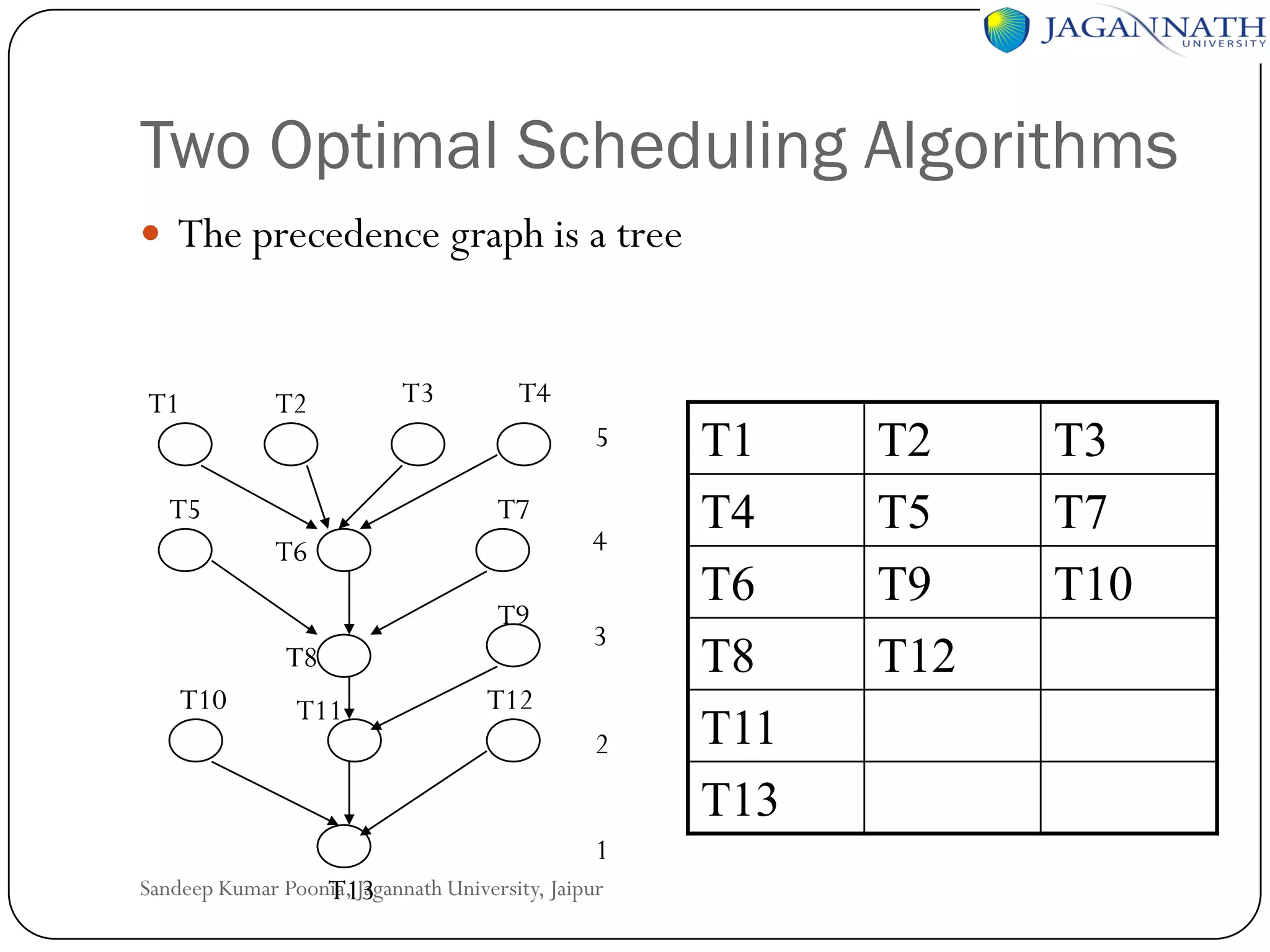
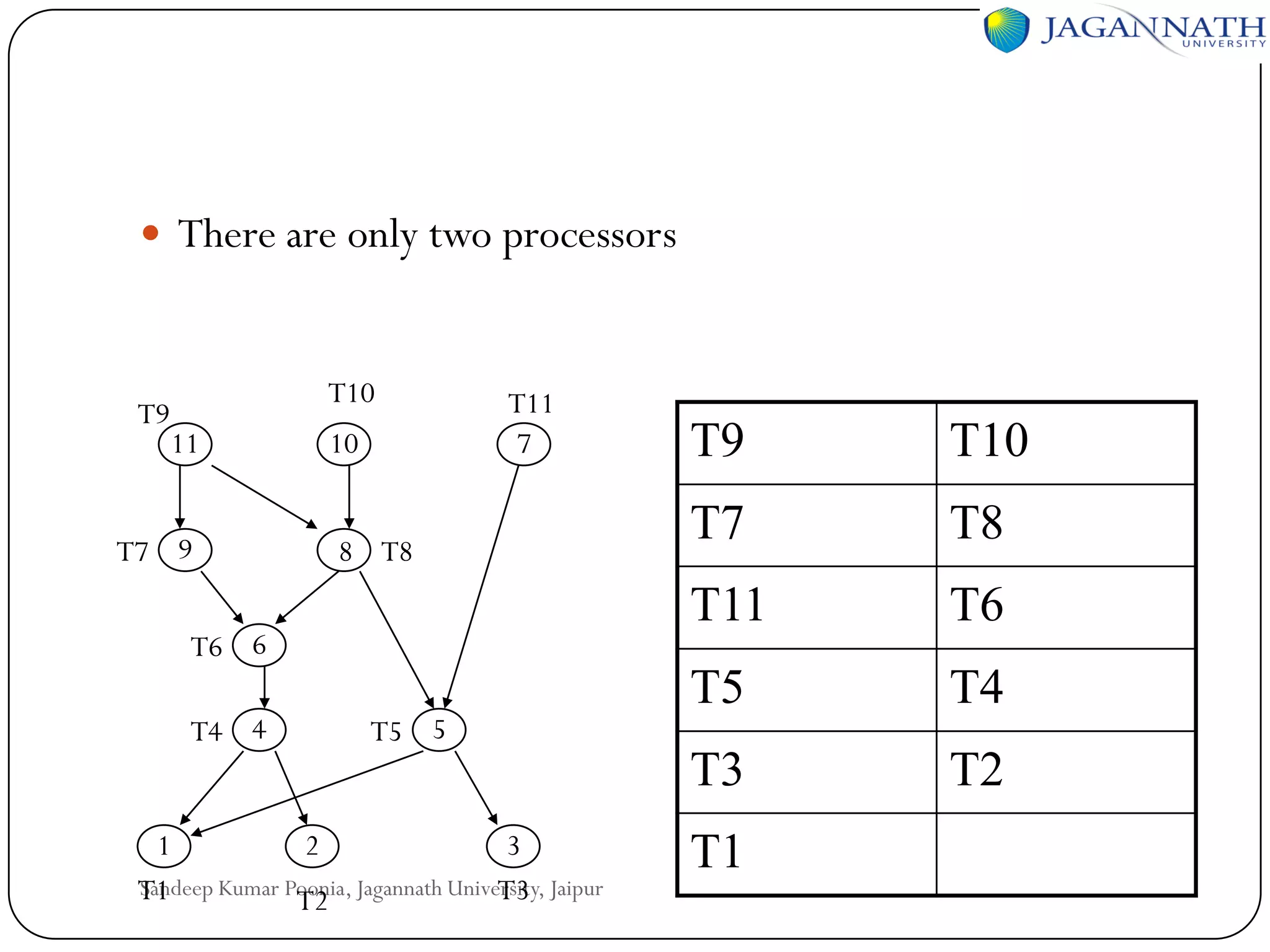
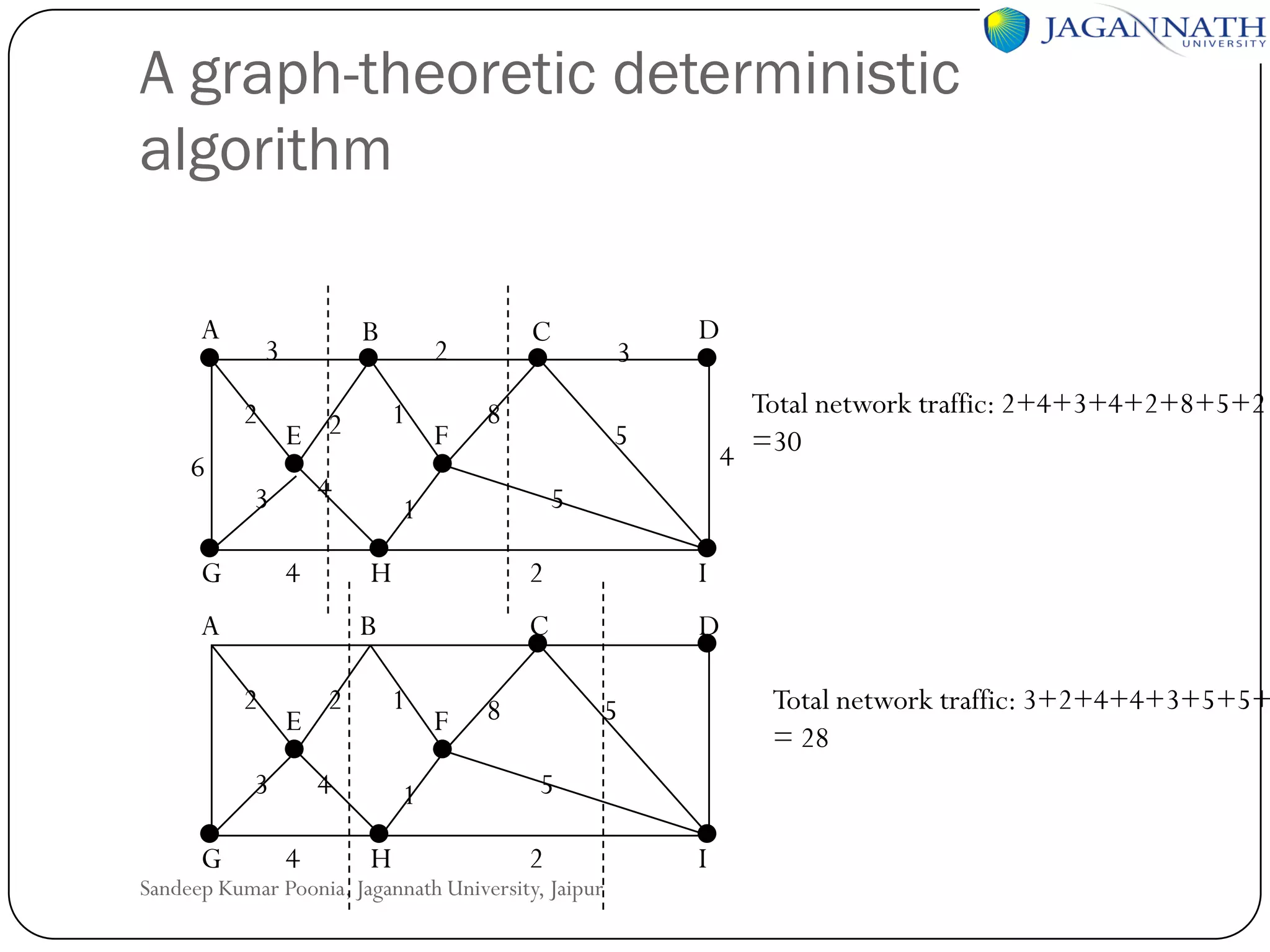

The document discusses processes and processors in distributed systems. It covers threads, system models, processor allocation, scheduling, load balancing, and process migration. Threads are lightweight processes that share an address space and resources. There are advantages to using threads like handling signals and implementing producer-consumer problems. System models for distributed systems include workstations with local disks, diskless workstations, and a processor pool model. Processor allocation aims to maximize CPU utilization and minimize response times. Algorithms must consider overhead, complexity, and stability.























































































