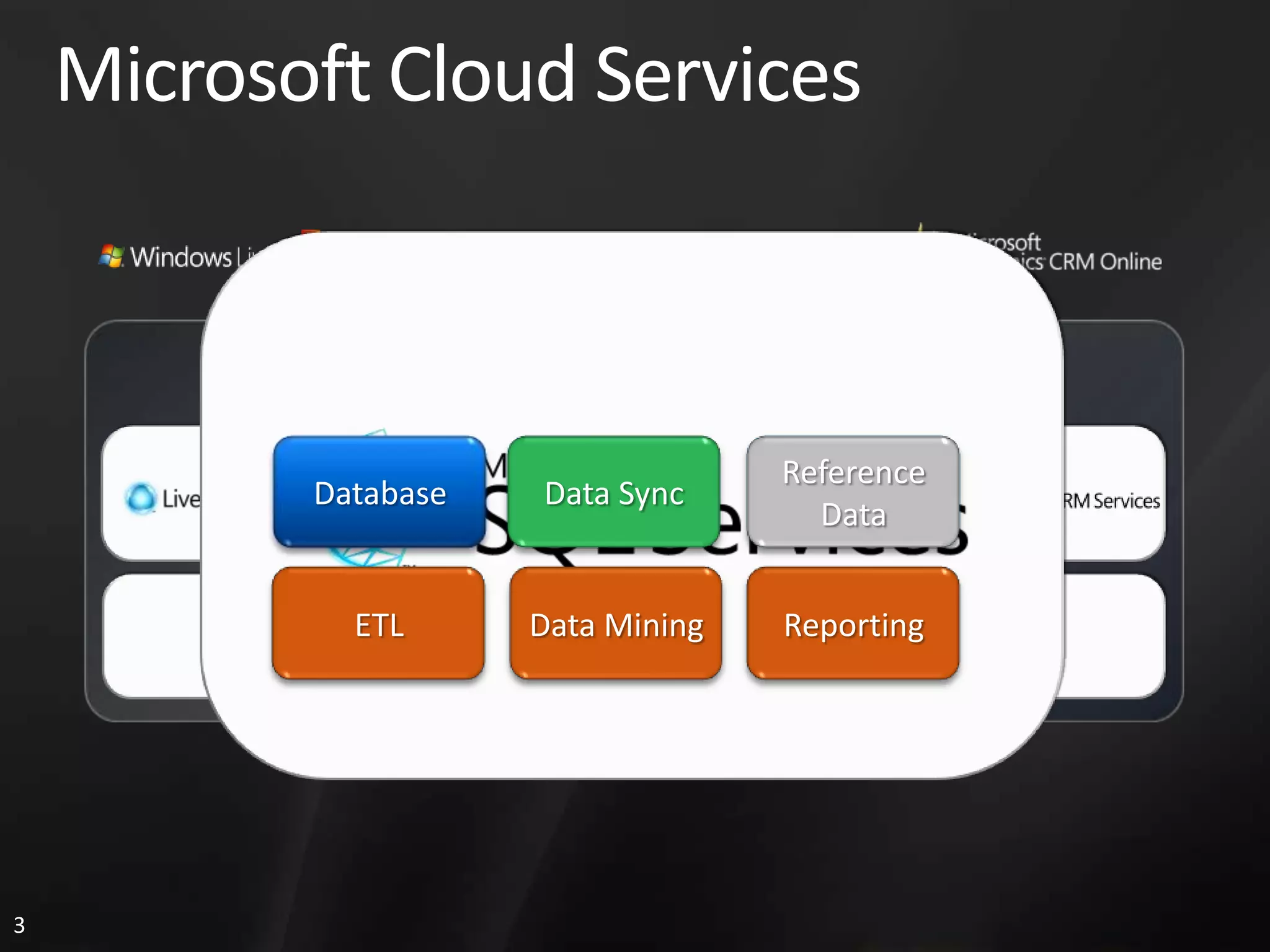
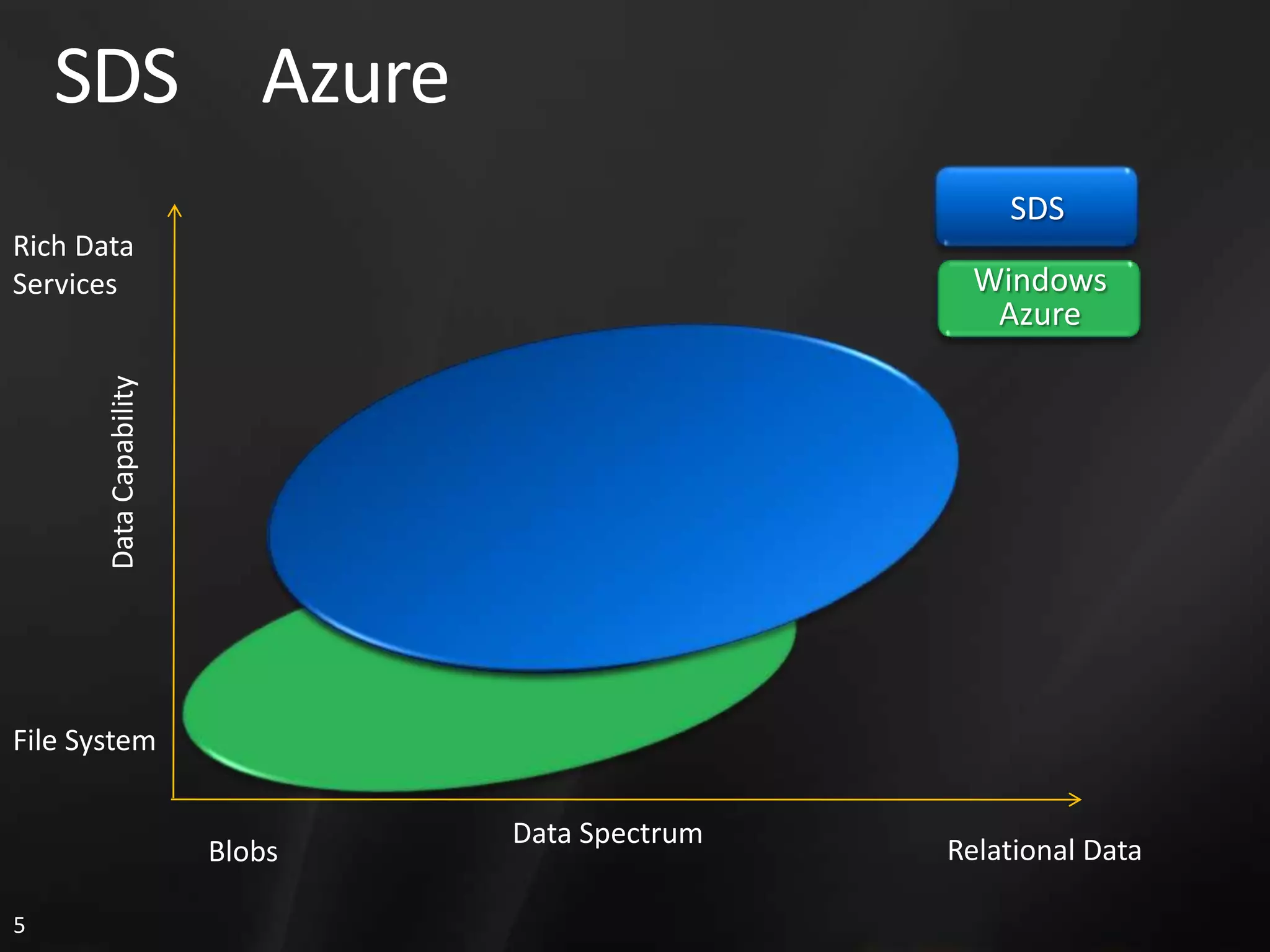
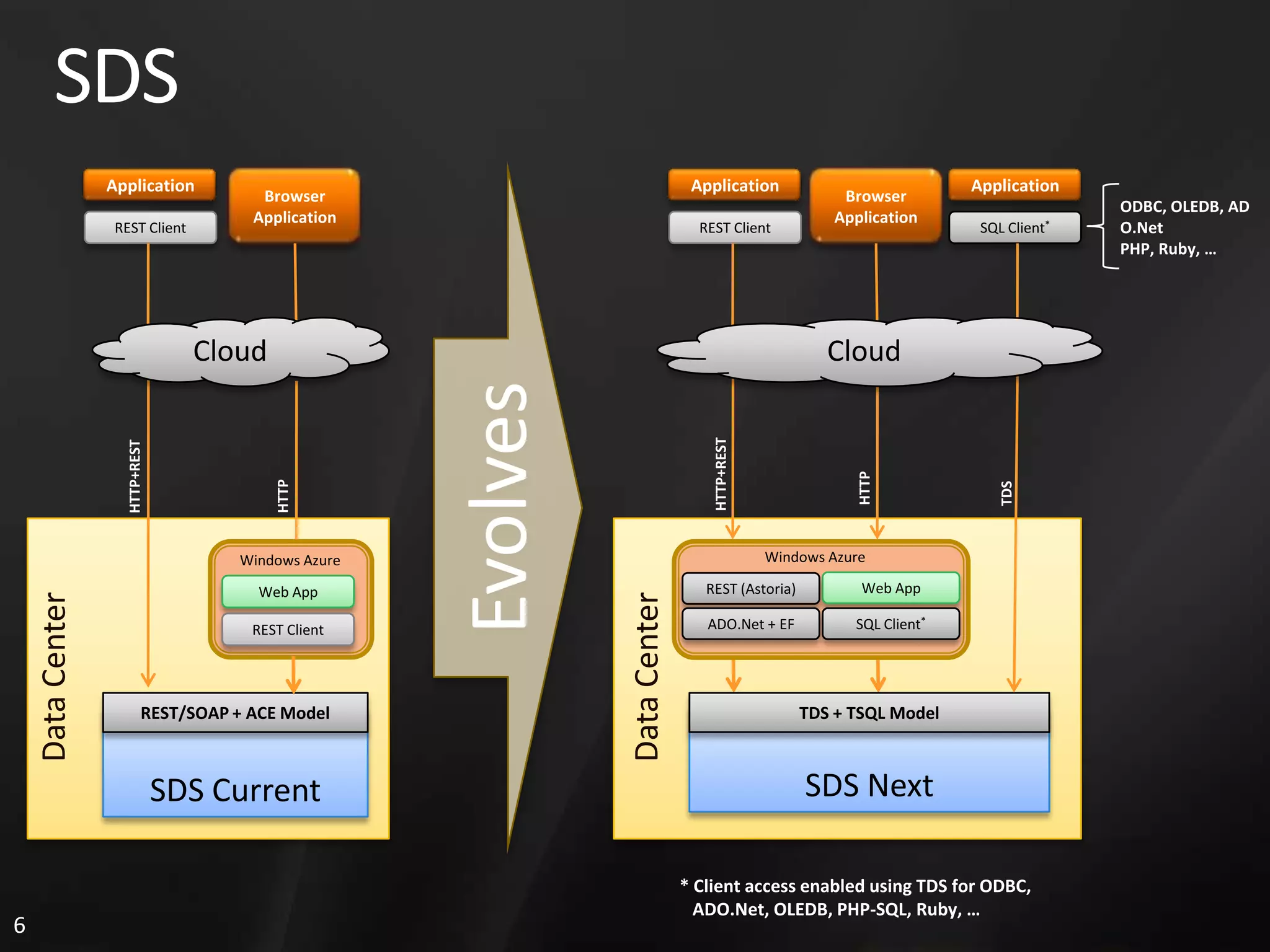
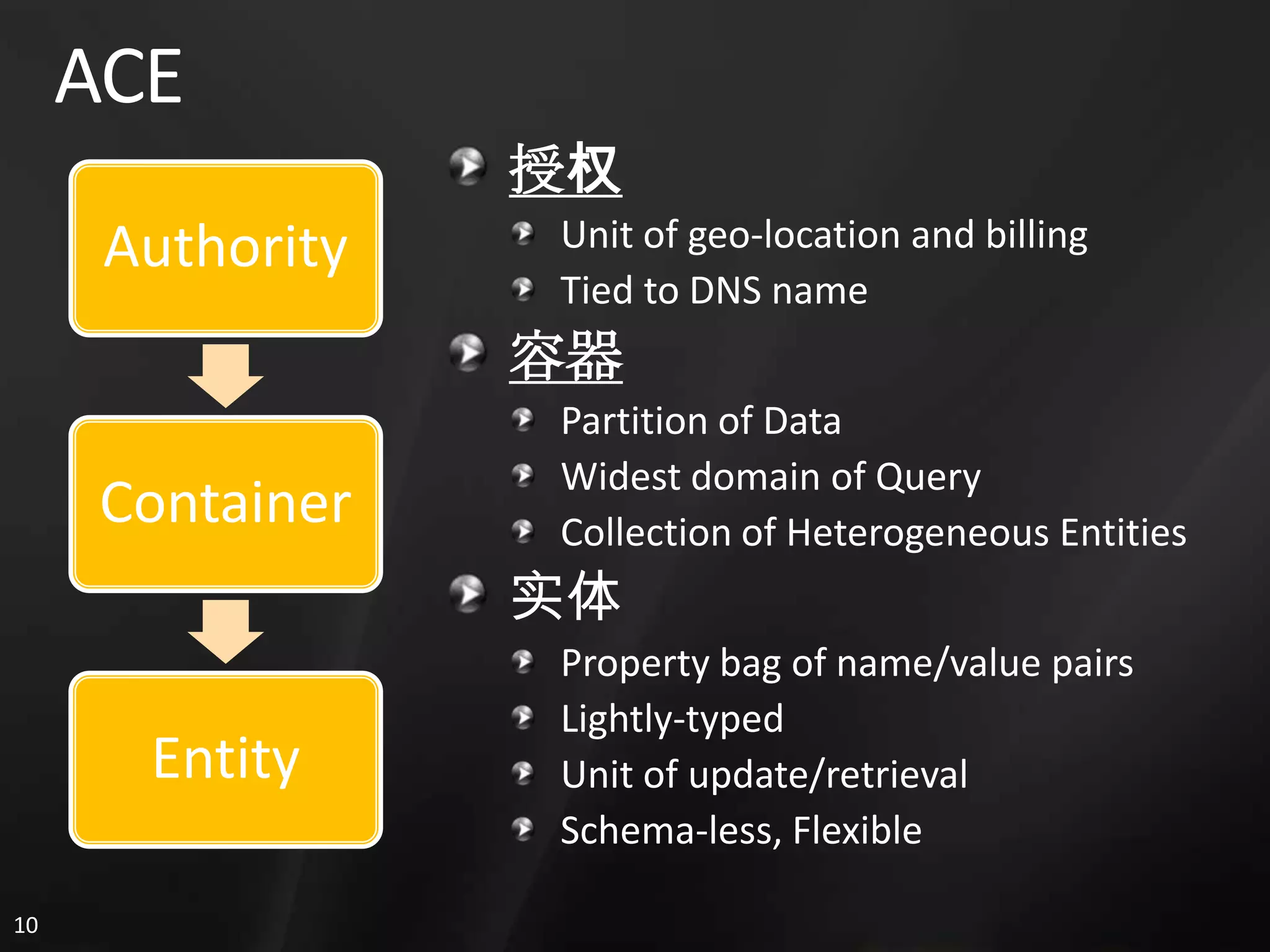
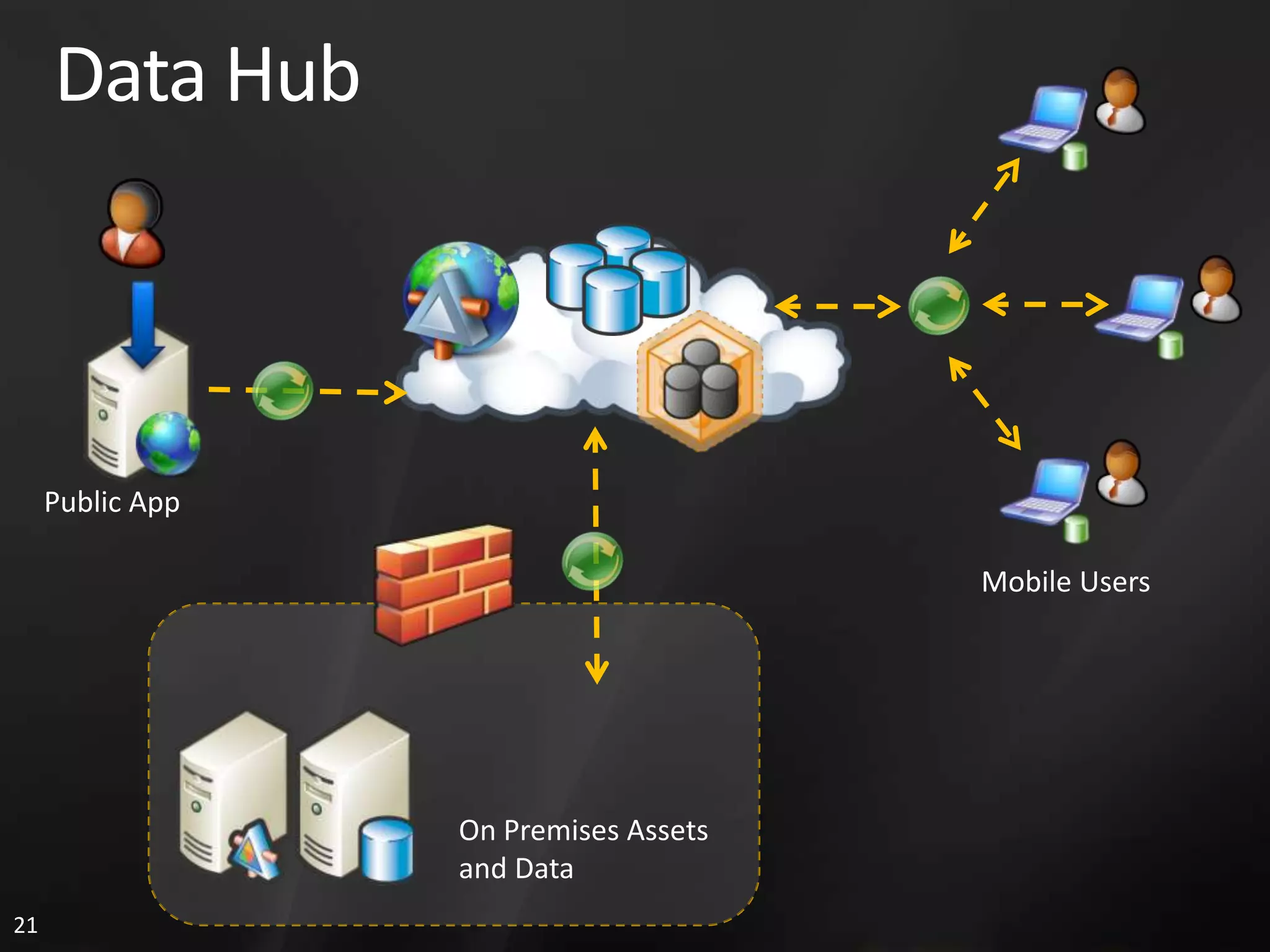
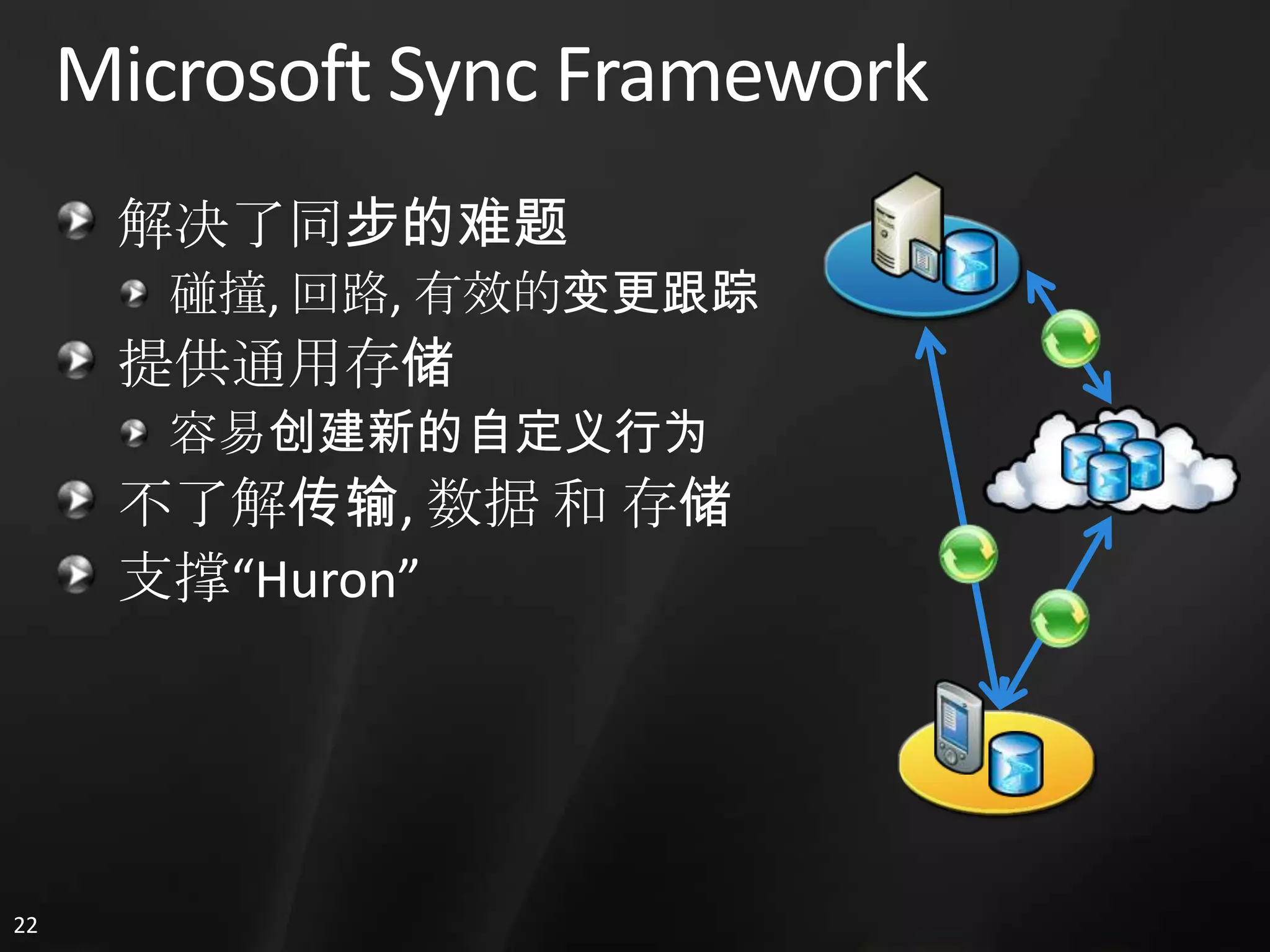
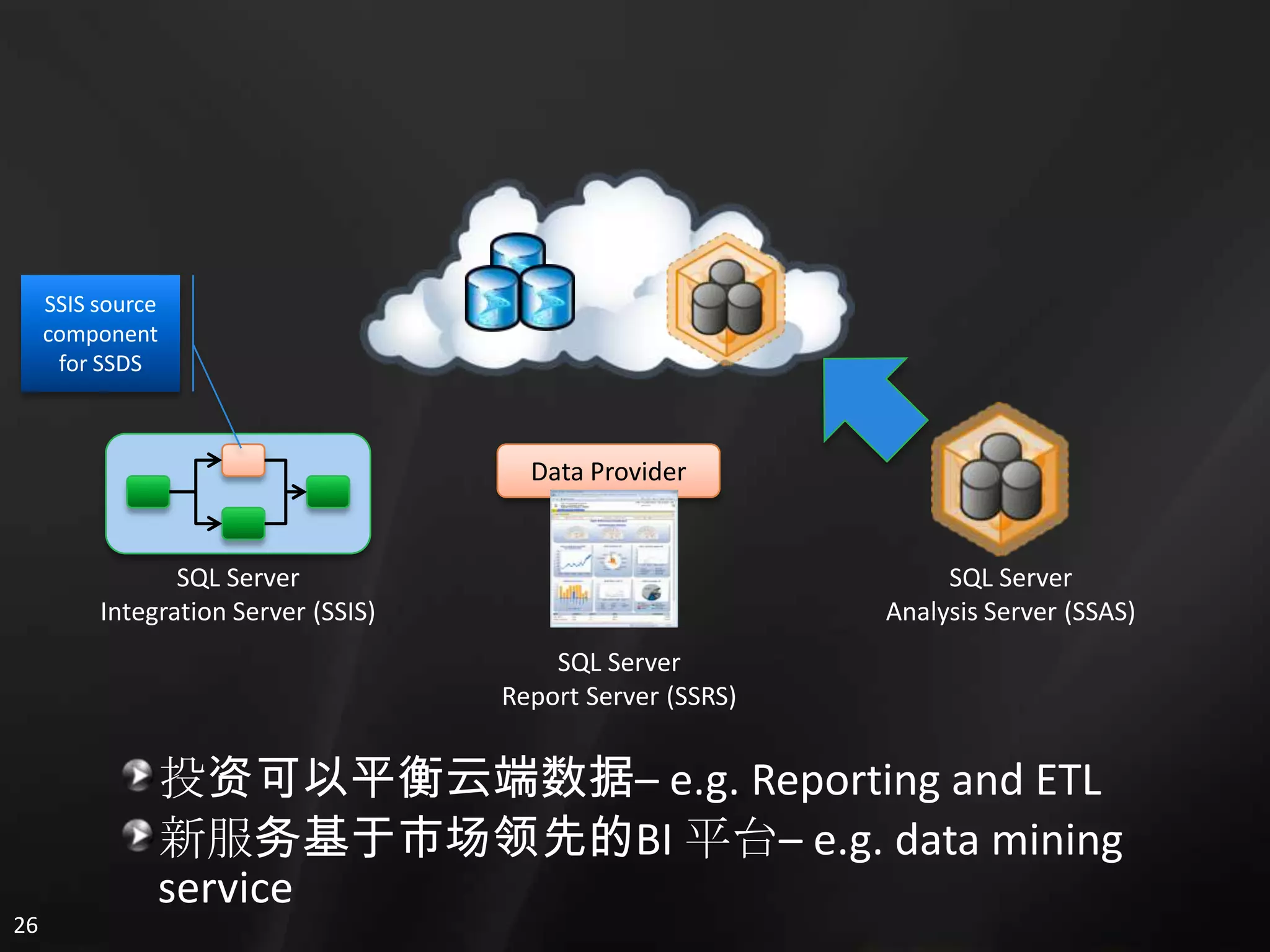
1. The document discusses SQL Data Services and provides descriptions of data modeling capabilities, data synchronization using Project Huron, and BI capabilities including reporting, data mining, and ETL.
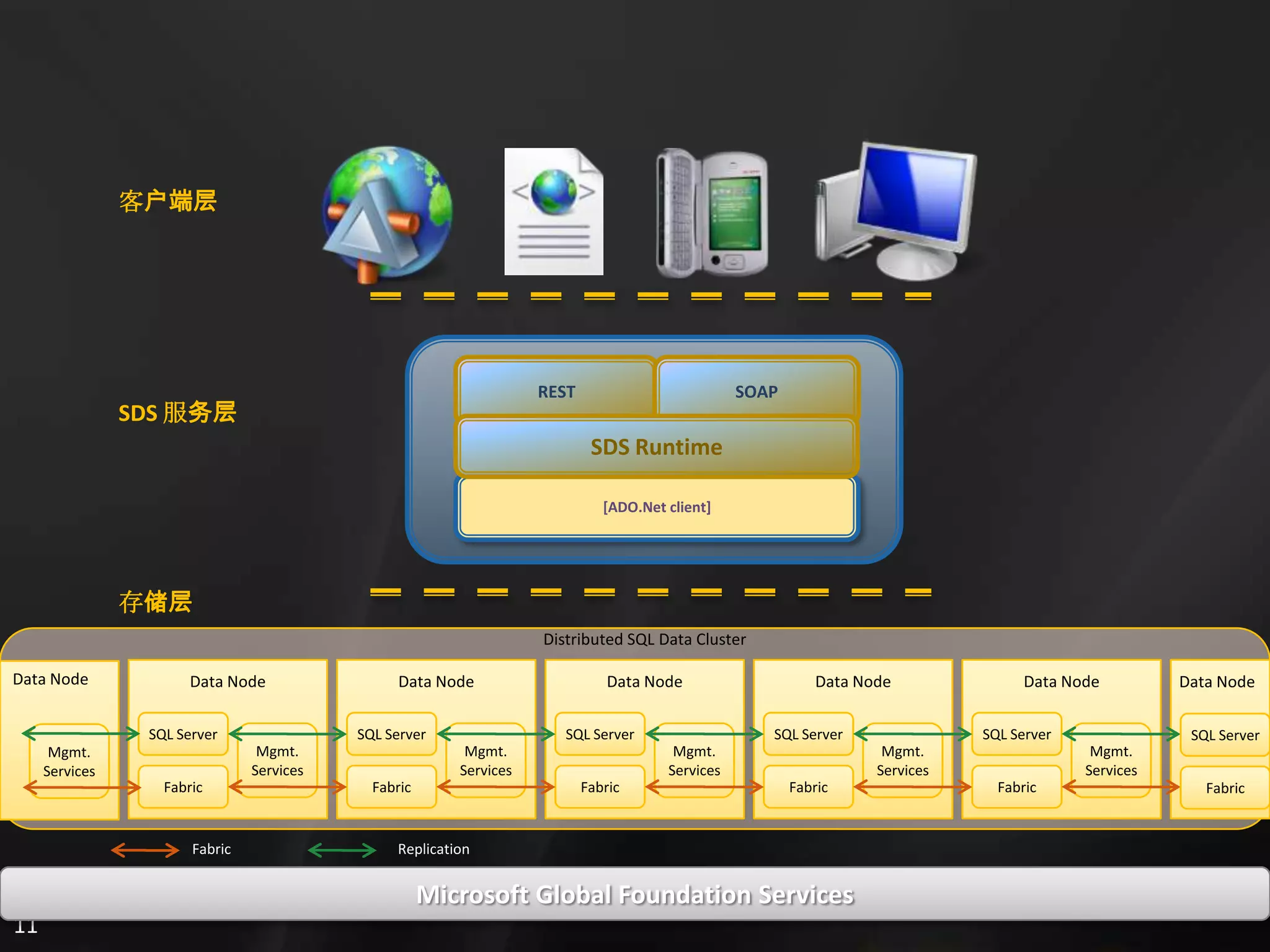
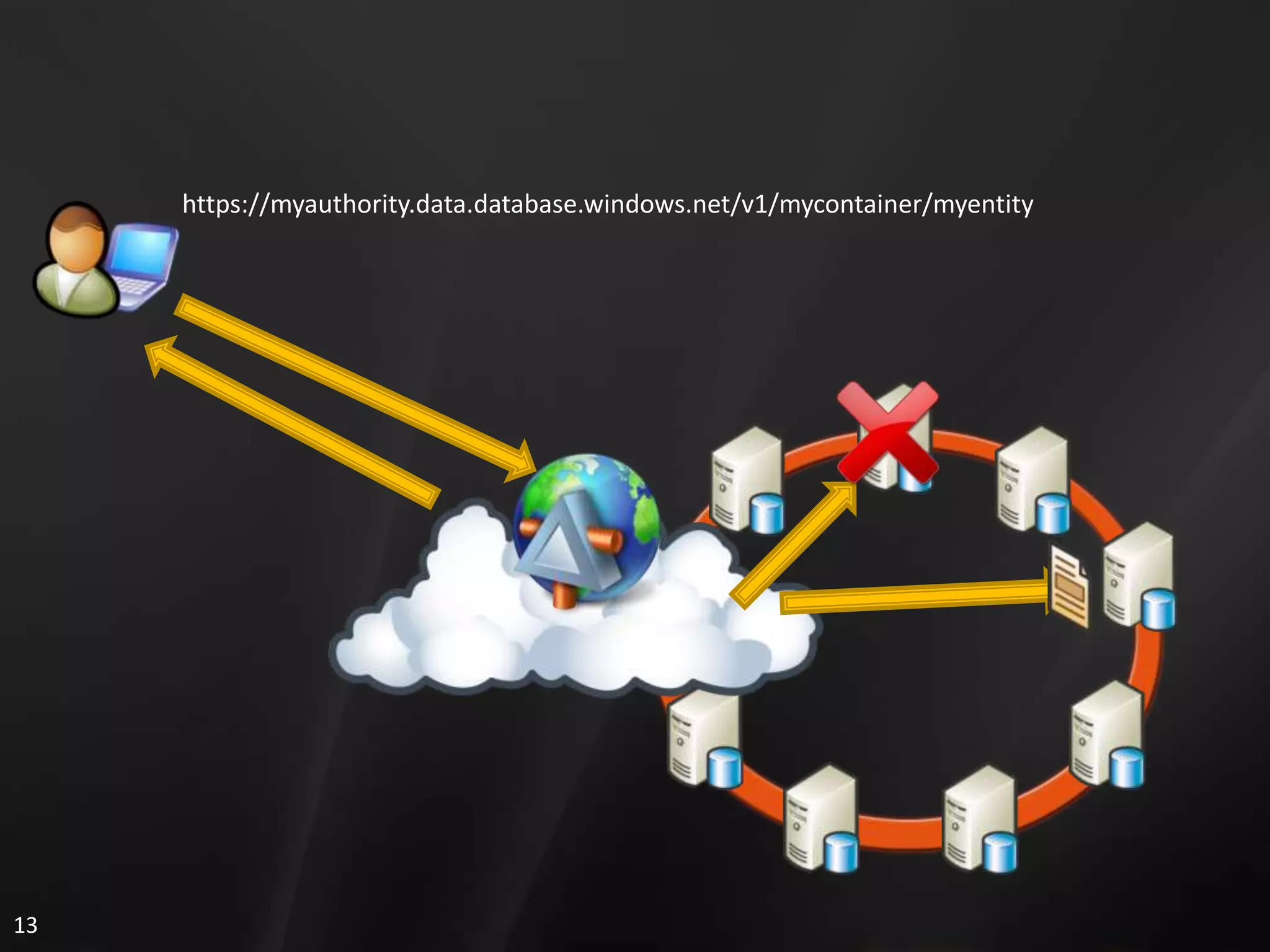
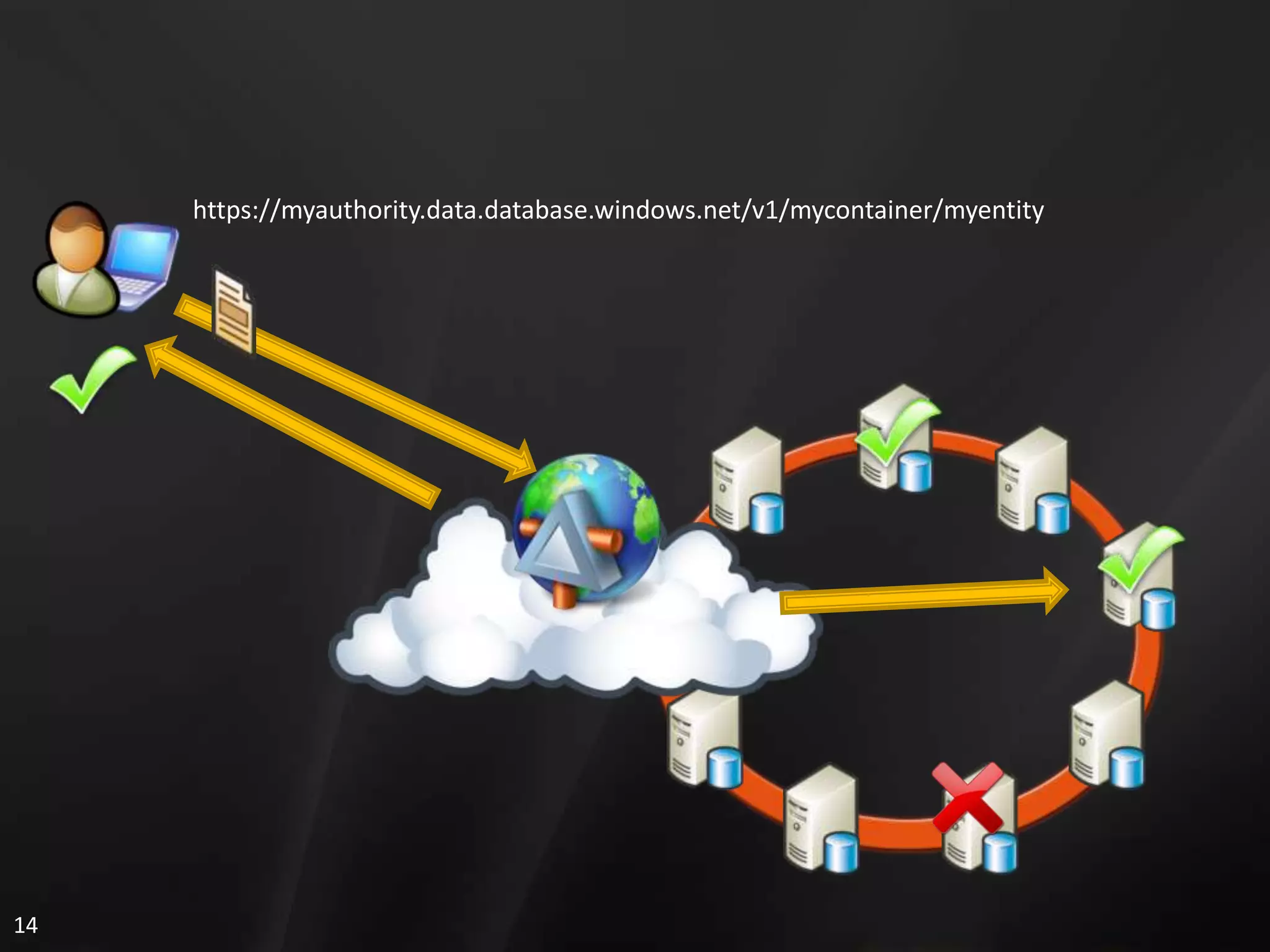
2. It also references Microsoft Cloud Services and shows how SQL Data Services uses SQL Server technologies like distributed databases on nodes to handle data storage, retrieval, and processing in a scalable and reliable manner.
3. The document discusses several advantages of SQL Data Services including availability, scalability, reliability, security, and cost efficiency.