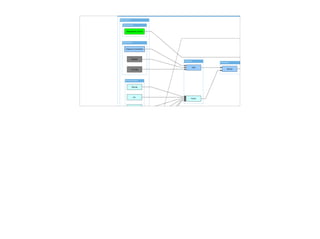
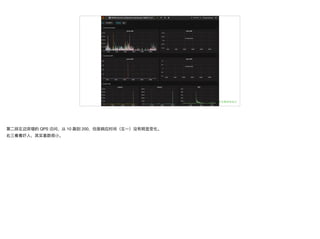
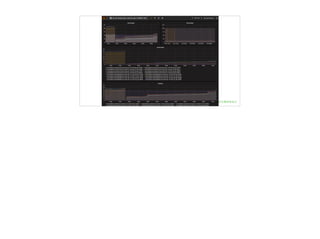
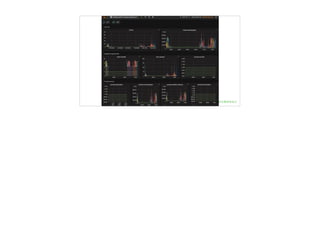
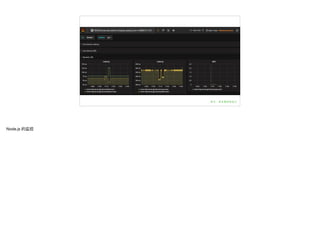
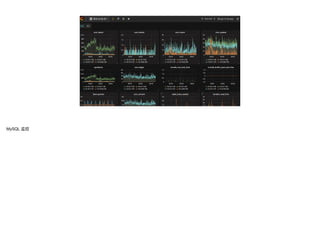
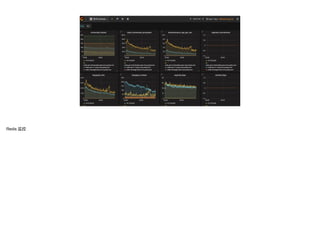
文档讨论了 metrics 监控系统的重要性与实现,重点介绍了 SLA、SLO 和 SLI 的概念以及其在监控中的应用。还提到了一系列监控原则和方法,包括监控的范围、类型和处理线上问题的策略。最后,文档提供了现有技术及工具列表,以支持 metrics 监控的实施。