Download to read offline







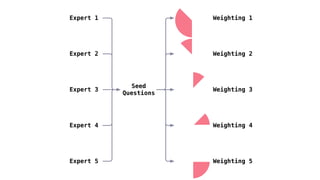



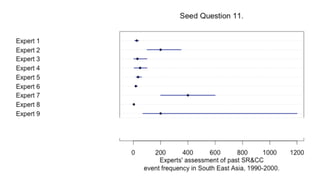
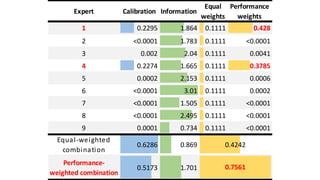
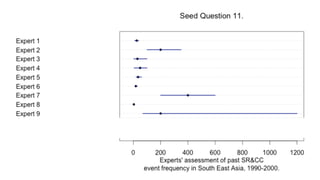
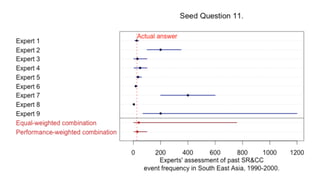
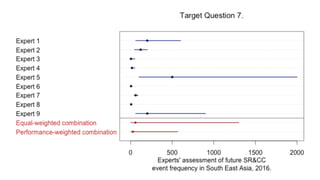





1) The document describes a study using structured expert judgement (SEJ) to elicit predictions of future political violence frequency from multiple experts in the (re)insurance industry. 2) In the SEJ method, experts were given seed questions to rate their forecasting ability, and then asked a target question about political violence forecasts. Their answers to the seed questions determined performance-based weightings that were used to combine their answers to the target question. 3) The results showed that weighting the experts by their performance on seed questions and combining their judgements produced a forecast that was better calibrated and more tightly estimated than either an equal-weighted combination or the forecasts of individual experts.


























