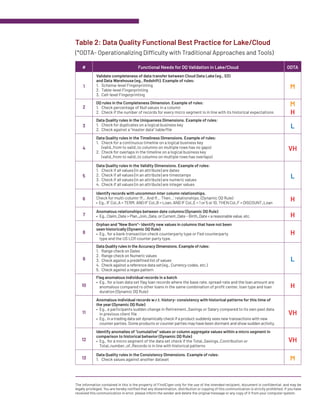
The document discusses best practices for data validation in the cloud and data lakes, emphasizing the need for rigorous checks at both lake and application levels to ensure data quality and trustworthiness. It highlights FirstEigen's Databuck software, which simplifies the data validation process, reducing implementation time from months to weeks and enabling automatic generation of checks without coding. The document also outlines various data quality checks related to completeness, accuracy, and validity that can be applied to enhance data reliability.