More Related Content

PPTX

PDF
Treasure Data Intro for Data Enthusiast!! 
PDF
トレジャーデータ新サービス発表 2013/12/9 
PDF

PDF
トレジャーデータ株式会社について(for all Data_Enthusiast!!) 
PDF
トレジャーデータのバッチクエリとアドホッククエリを理解する 
PDF
20140708 オンラインゲームソリューション 
PDF
What's hot

PDF
Treasure Data × Wave Analytics EC Demo 
PDF

PDF
この Visualization がすごい2014 〜データ世界を彩るツール6選〜 
PDF
トレジャーデータとtableau実現する自動レポーティング 
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo 
PDF
20160220 MSのビッグデータ分析基盤 - データマイニング+WEB@東京 
PDF
Google Cloud ベストプラクティス:Google BigQuery 編 - 02 : データ処理 / クエリ / データ抽出 
PPTX
分散グラフデータベース DataStax Enterprise Graph 
PDF

PDF
Treasure Dataを支える技術 - MessagePack編 ![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編] 
PDF
Azure Antenna はじめての Azure Data Lake 
PDF
Microsoft Azureのビッグデータ基盤とAIテクノロジーを活用しよう ![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編] 
PDF
Developers.IO 2019 Effective Datalake 
PDF
DeltaCubeにおけるユニークユーザー集計高速化(理論編) ![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake 
PPTX
dots. ビッグデータオールスターズ: Azure 畠山 
PDF
Pydata Amazon Kinesisのご紹介 
PDF
1000人規模で使う分析基盤構築 〜redshiftを活用したeuc Similar to For blog hive_ql_on_treasuredata

PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter) 
PPTX
SIGMOD 2022�Amazon Redshift Re-invented を読んで 
PPTX
02 kueri zui_shi_hua_notamenopuroziekushiyonshe_ji_ 
PDF
Osc2012 spring HBase Report 
PDF
Hadoop, NoSQL, GlusterFSの概要 
PPT

PDF

PPT

PDF

PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014) 
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version - 
PDF
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise 
PPTX
ビッグデータとioDriveの夕べ:ドリコムのデータ分析環境のお話 
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料) 
PPTX

PPTX

PDF
Cassandraとh baseの比較して入門するno sql 
PPTX

PDF

PDF
For blog hive_ql_on_treasuredata
- 1.
© SIOS Technology,Inc. All rights Reserved.
1. BigData解析基盤としての
Treasure Data
2. HiveQLの周辺技術とTips
サイオステクノロジー株式会社
クラウドソリューション部
2013年6月11日
髙橋 達
サイオステクノロジー株式会社
- 2.
© SIOS Technology,Inc. All rights Reserved.
目的と目次
目 次
1. BigData解析基盤としてのTreasure Data
1. BigData解析基盤とは?
2. HiveQLの周辺技術とTips
1.~4. HiveQLの周辺技術
5.~11. HiveQLのTips
3. 発表のまとめ
2
Treasure DataとHiveQLに関する知識共有により,
レポーティング作業の効率アップ
目 的
- 3.
© SIOS Technology,Inc. All rights Reserved.
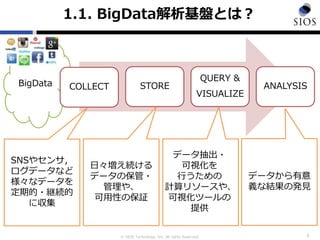
1.1. BigData解析基盤とは?
3
BigData COLLECT STORE
QUERY &
VISUALIZE
ANALYSIS
SNSやセンサ,
ログデータなど
様々なデータを
定期的・継続的
に収集
日々増え続ける
データの保管・
管理や、
可用性の保証
データ抽出・
可視化を
行うための
計算リソースや、
可視化ツールの
提供
データから有意
義な結果の発見
- 4.
© SIOS Technology,Inc. All rights Reserved.
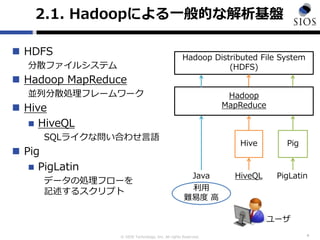
2.1. Hadoopによる一般的な解析基盤
HDFS
分散ファイルシステム
Hadoop MapReduce
並列分散処理フレームワーク
Hive
HiveQL
SQLライクな問い合わせ言語
Pig
PigLatin
データの処理フローを
記述するスクリプト
4
Hadoop Distributed File System
(HDFS)
Hadoop
MapReduce
Hive Pig
HiveQL PigLatinJava
利用
難易度 高
ユーザ
- 5.
© SIOS Technology,Inc. All rights Reserved.
2.2. MapReduce・Pig・Hiveの記述比較
例:単語の集計
Java For
MapReduce
(コードの1/6程度抜粋)
Job job = new Job(conf,
'wordcount');
job.setJarByClass(WordCou
nt.class);
job.setOutputKeyClass(Text
.class);
job.setOutputValueClass(In
tWritable.class);
job.setMapperClass(Map.cla
ss);
job.setCombinerClass(Redu
ce.class);
job.setReducerClass(Reduc
e.class);
HiveQL
select s.word, count(*) from
(select explode(split(text, '[ ¥t]+')) word from
hello) s group by s.word;
5
b = foreach a generate flatten(TOKENIZE(text))
as word;
c = group b by word;
d = foreach c generate group as word, COUNT(b)
as count;
store d into ‘/output';
PigLatin
スクリプト引用:http://www.ne.jp/asahi/hishidama/home/tech/index.html
- 6.
© SIOS Technology,Inc. All rights Reserved.
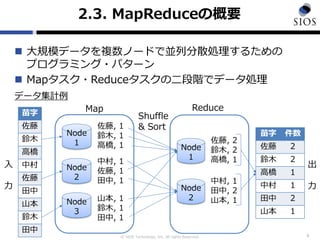
2.3. MapReduceの概要
大規模データを複数ノードで並列分散処理するための
プログラミング・パターン
Mapタスク・Reduceタスクの二段階でデータ処理
6
Map Reduce
Node
1
Node
2
Node
3
佐藤, 1
鈴木, 1
高橋, 1
中村, 1
佐藤, 1
田中, 1
山本, 1
鈴木, 1
田中, 1
Node
1
Node
2
佐藤, 2
鈴木, 2
高橋, 1
中村, 1
田中, 2
山本, 1
Shuffle
& Sort
データ集計例
入
力
出
力
苗字
佐藤
鈴木
高橋
中村
佐藤
田中
山本
鈴木
田中
苗字 件数
佐藤 2
鈴木 2
高橋 1
中村 1
田中 2
山本 1
- 7.
© SIOS Technology,Inc. All rights Reserved.
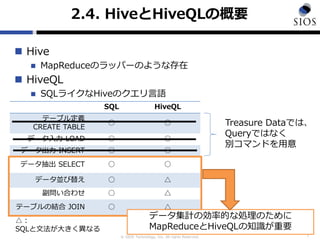
2.4. HiveとHiveQLの概要
Hive
MapReduceのラッパーのような存在
HiveQL
SQLライクなHiveのクエリ言語
7
SQL HiveQL
テーブル定義
CREATE TABLE
○ ○
データ入力 LOAD ○ ○
データ出力 INSERT ○ ○
データ抽出 SELECT ○ ○
データ並び替え ○ △
副問い合わせ ○ △
テーブルの結合 JOIN ○ △
△:
SQLと文法が大きく異なる
Treasure Dataでは、
Queryではなく
別コマンドを用意
データ集計の効率的な処理のために
MapReduceとHiveQLの知識が重要
- 8.
© SIOS Technology,Inc. All rights Reserved.
2.5. Treasure Dataにおけるデータ形式
二つのカラムに格納(’v’と’time’)
‘v’カラムには、MAP形式で格納
Key:v[‘host’], v[‘user’]
Value:’1.1.0.1’, ‘ichi’
カラムの参照
v[‘host’], v[‘user’], time
別名をカラム名として利用
v[‘host’] AS host
8
v time
{'host':'1.1.0.1','user':'ichi'} 1370420001
{'host':'1.1.0.2','user':'jiro'} 1370420010
{'host':'1.1.0.3','user':'sabu'} 1370420100
_c0
1.1.0.1
1.1.0.2
1.1.0.3
host
1.1.0.1
1.1.0.2
1.1.0.3
AS利用
AS未使用
- 9.
© SIOS Technology,Inc. All rights Reserved.
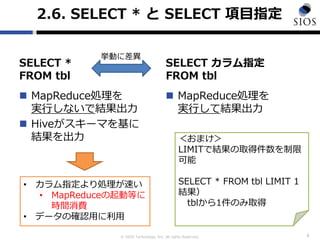
2.6. SELECT * と SELECT 項目指定
SELECT *
FROM tbl
MapReduce処理を
実行しないで結果出力
Hiveがスキーマを基に
結果を出力
SELECT カラム指定
FROM tbl
MapReduce処理を
実行して結果出力
9
挙動に差異
• カラム指定より処理が速い
• MapReduceの起動等に
時間消費
• データの確認用に利用
<おまけ>
LIMITで結果の取得件数を制限
可能
SELECT * FROM tbl LIMIT 1
結果)
tblから1件のみ取得
- 10.
© SIOS Technology,Inc. All rights Reserved.
2.7. MapReduceの回数削減による効率化
重複カラムの除去でのLEFT SEMI JOIN
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) JOIN
(SELECT v[‘host’] AS host
FROM tbl2 GROUP BY host
) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2)
ON tbl1.host = tbl2.host
10
GROUP BYの利用 LEFT SEMI JOINの利用
v
{'host':'1.1.0.3‘, ‘user’:’taro’}
{'host':'1.1.0.1‘, ‘user’:’ichi’}
v time
{'host':'1.1.0.1‘} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : GROUP BY計算
stage-2 : JOIN計算
stage-1 : JOIN計算
処理数の削減
* 右テーブルのデータが左テーブル
に存在する場合のみ利用可能
- 11.
© SIOS Technology,Inc. All rights Reserved.
2.8.テーブルをメモリへ展開する
MAPJOINの利用
11
SELECT /*+MAPJOIN(tbl2)*/
host AS host FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2) ON tbl1.host =
tbl2.host
MAPJOINの非利用 MAPJOINの利用
v
{'host':'1.1.0.3‘, ‘user’:’taro’}
{'host':'1.1.0.1‘, ‘user’:’ichi’}
v time
{'host':'1.1.0.1‘} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : JOIN計算
計算時間 小
→右テーブルをメモリ上に展開
stage-1 : JOIN計算
計算時間 大
* 右テーブルのデータがメモリに
収まりきるサイズであること
- 12.
© SIOS Technology,Inc. All rights Reserved.
2.9. 全体集計と個別集計
12
V
{‘user':‘taro‘, ‘cnt’:20’}
{‘user':‘ichi‘, ‘cnt’:’5’}
{‘user':‘ichi‘, ‘cnt’:’15’}
tbl
user count
NULL 40
taro 20
ichi 20
SELECT v[‘user’] AS user,
SUM(v[‘cnt’]) AS count
FROM tbl
GROUP BY v[‘host’]
WITH ROLLUP
SELECT u AS user, SUM(z) AS count
FROM tbl LATERAL VIEW
EXPLODE(ARRAY(v[‘user’], null)) e
AS u
group by u
ROLLUPの利用(Hive0.10未満) ROLLUPの利用 (Hive0.10以上)
*現在のTDでは利用不可*v[‘user’]は NOT NULL
- 13.
© SIOS Technology,Inc. All rights Reserved.
2.10. Treasure Dataが提供するUDF
(User Defined Functoins)
TD_X_RANK(keys)
ユーザ毎に番号付
時系列に並び替えることでパスの作成が可能
TD_TIME_RANGE(time, start_time, end_time)
WHERE句での時間による範囲指定
TD_TIME_ADD(time, ‘期間’)
時間の様々な指定が可能
N日後:’1d’, ‘2d’, ‘3d’,...
13
V
{‘user':‘taro‘, ‘ref’:’1.1.1.1’}
{‘user':‘ichi‘, ‘ref’:’1.1.1.2’}
{‘user':‘ichi‘, ‘ref’:’1.1.1.3’}
Rank User Ref
1 Taro 1.1.1.1
1 Ichi 1.1.1.2
2 Ichi 1.1.1.3
SELECT ... WHERE TD_TIME_RANGE(
Time, ‘2013-04-01’, TD_TIME_ADD(‘2013-04-01’, ‘1d’)
- 14.
© SIOS Technology,Inc. All rights Reserved.
2.11. その他のポイント(1/2)
テーブル結合について
UNION ALLのみ利用可能
重複を含む全レコードの結合
結合するテーブル全体を副問い合わせにすること
JOIN ONのONを記述漏れは、CROSS JOINになる
ON句では以下の二つは利用不可
不等号での結合
ORによる二つの条件を用いた結合
正規表現について
LIKE = SQLのLIKE
ワイルドカード:*,%,?,_,#,[文字リスト],...
RLIKEを用いると、Javaの正規表現を利用可能
ワイルドカード:LIKE + α
14
- 15.
© SIOS Technology,Inc. All rights Reserved.
2.11. その他のポイント(2/2)
関数情報
SHOW FUNCTIONS
関数の一覧を表示(UDFも含む)
DESC FUNCTION 関数名
DESC FUNCTION EXTENDED 関数名
関数の情報を表示、EXTENDEDで使用例も表示
15
- 16.
© SIOS Technology,Inc. All rights Reserved.
3. 発表のまとめ
ビッグデータ解析基盤に求められる機能:
各製品における各機能の詳細な比較が必要
HiveQLのTips
SQLと違いはあまりない
MapReduceを意識することでクエリの効率化
LEFT SEMI JOINの利用
/*+ MAPJOIN(tbl) */の利用
全体集計と個別集計
UDFについて
16
COLLECT STORE QUERY & VISUALIZE ANALYSIS




![© SIOS Technology, Inc. All rights Reserved.
2.2. MapReduce・Pig・Hiveの記述比較
例:単語の集計
Java For
MapReduce
(コードの1/6程度抜粋)
Job job = new Job(conf,
'wordcount');
job.setJarByClass(WordCou
nt.class);
job.setOutputKeyClass(Text
.class);
job.setOutputValueClass(In
tWritable.class);
job.setMapperClass(Map.cla
ss);
job.setCombinerClass(Redu
ce.class);
job.setReducerClass(Reduc
e.class);
HiveQL
select s.word, count(*) from
(select explode(split(text, '[ ¥t]+')) word from
hello) s group by s.word;
5
b = foreach a generate flatten(TOKENIZE(text))
as word;
c = group b by word;
d = foreach c generate group as word, COUNT(b)
as count;
store d into ‘/output';
PigLatin
スクリプト引用:http://www.ne.jp/asahi/hishidama/home/tech/index.html](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-5-320.jpg)
![© SIOS Technology, Inc. All rights Reserved.
2.5. Treasure Dataにおけるデータ形式
二つのカラムに格納(’v’と’time’)
‘v’カラムには、MAP形式で格納
Key:v[‘host’], v[‘user’]
Value:’1.1.0.1’, ‘ichi’
カラムの参照
v[‘host’], v[‘user’], time
別名をカラム名として利用
v[‘host’] AS host
8
v time
{'host':'1.1.0.1','user':'ichi'} 1370420001
{'host':'1.1.0.2','user':'jiro'} 1370420010
{'host':'1.1.0.3','user':'sabu'} 1370420100
_c0
1.1.0.1
1.1.0.2
1.1.0.3
host
1.1.0.1
1.1.0.2
1.1.0.3
AS利用
AS未使用](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-8-320.jpg)
![© SIOS Technology, Inc. All rights Reserved.
2.7. MapReduceの回数削減による効率化
重複カラムの除去でのLEFT SEMI JOIN
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) JOIN
(SELECT v[‘host’] AS host
FROM tbl2 GROUP BY host
) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2)
ON tbl1.host = tbl2.host
10
GROUP BYの利用 LEFT SEMI JOINの利用
v
{'host':'1.1.0.3‘, ‘user’:’taro’}
{'host':'1.1.0.1‘, ‘user’:’ichi’}
v time
{'host':'1.1.0.1‘} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : GROUP BY計算
stage-2 : JOIN計算
stage-1 : JOIN計算
処理数の削減
* 右テーブルのデータが左テーブル
に存在する場合のみ利用可能](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-10-320.jpg)
![© SIOS Technology, Inc. All rights Reserved.
2.8.テーブルをメモリへ展開する
MAPJOINの利用
11
SELECT /*+MAPJOIN(tbl2)*/
host AS host FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2) ON tbl1.host = tbl2.host
SELECT host AS host
FROM
(SELECT v[‘host’] AS host
FROM tbl1) LEFT SEMI JOIN
(SELECT v[‘host’] AS host
FROM tbl2) ON tbl1.host =
tbl2.host
MAPJOINの非利用 MAPJOINの利用
v
{'host':'1.1.0.3‘, ‘user’:’taro’}
{'host':'1.1.0.1‘, ‘user’:’ichi’}
v time
{'host':'1.1.0.1‘} 1370420001
{'host':'1.1.0.1'} 1370420010
tbl1 tbl2
host
1.1.0.1
stage-1 : JOIN計算
計算時間 小
→右テーブルをメモリ上に展開
stage-1 : JOIN計算
計算時間 大
* 右テーブルのデータがメモリに
収まりきるサイズであること](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-11-320.jpg)
![© SIOS Technology, Inc. All rights Reserved.
2.9. 全体集計と個別集計
12
V
{‘user':‘taro‘, ‘cnt’:20’}
{‘user':‘ichi‘, ‘cnt’:’5’}
{‘user':‘ichi‘, ‘cnt’:’15’}
tbl
user count
NULL 40
taro 20
ichi 20
SELECT v[‘user’] AS user,
SUM(v[‘cnt’]) AS count
FROM tbl
GROUP BY v[‘host’]
WITH ROLLUP
SELECT u AS user, SUM(z) AS count
FROM tbl LATERAL VIEW
EXPLODE(ARRAY(v[‘user’], null)) e
AS u
group by u
ROLLUPの利用(Hive0.10未満) ROLLUPの利用 (Hive0.10以上)
*現在のTDでは利用不可*v[‘user’]は NOT NULL](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-12-320.jpg)

![© SIOS Technology, Inc. All rights Reserved.
2.11. その他のポイント(1/2)
テーブル結合について
UNION ALLのみ利用可能
重複を含む全レコードの結合
結合するテーブル全体を副問い合わせにすること
JOIN ONのONを記述漏れは、CROSS JOINになる
ON句では以下の二つは利用不可
不等号での結合
ORによる二つの条件を用いた結合
正規表現について
LIKE = SQLのLIKE
ワイルドカード:*,%,?,_,#,[文字リスト],...
RLIKEを用いると、Javaの正規表現を利用可能
ワイルドカード:LIKE + α
14](https://image.slidesharecdn.com/forbloghiveqlontreasuredata-130620224632-phpapp01/85/For-blog-hive_ql_on_treasuredata-14-320.jpg)

