More Related Content

PDF

PDF
Research cafe018 20150529_handouts_share 
PDF
Cluster Analysis at REQUIRE 26, 2016/10/01 
PDF
GLMM in interventional study at Require 23, 20151219 
PDF
Require19_04-accesibility_20150320_update 
PDF
データ解析のための統計モデリング入門3章後半 
PDF

PDF
Featured

PDF
2024 Trend Updates: What Really Works In SEO & Content Marketing 
PDF
Storytelling For The Web: Integrate Storytelling in your Design Process 
PDF
Artificial Intelligence, Data and Competition – SCHREPEL – June 2024 OECD dis... 
PDF
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR... 
PDF
2024 State of Marketing Report – by Hubspot 
PDF
Everything You Need To Know About ChatGPT 
PDF
Product Design Trends in 2024 | Teenage Engineerings 
PDF
How Race, Age and Gender Shape Attitudes Towards Mental Health 
PDF
AI Trends in Creative Operations 2024 by Artwork Flow.pdf 
PDF

PDF
PEPSICO Presentation to CAGNY Conference Feb 2024 
PDF
Content Methodology: A Best Practices Report (Webinar) 
PPTX
How to Prepare For a Successful Job Search for 2024 
PDF
Social Media Marketing Trends 2024 // The Global Indie Insights 
PDF
Trends In Paid Search: Navigating The Digital Landscape In 2024 
PDF
5 Public speaking tips from TED - Visualized summary 
PDF
ChatGPT and the Future of Work - Clark Boyd 
PDF
Getting into the tech field. what next 
PDF
Google's Just Not That Into You: Understanding Core Updates & Search Intent 
PDF
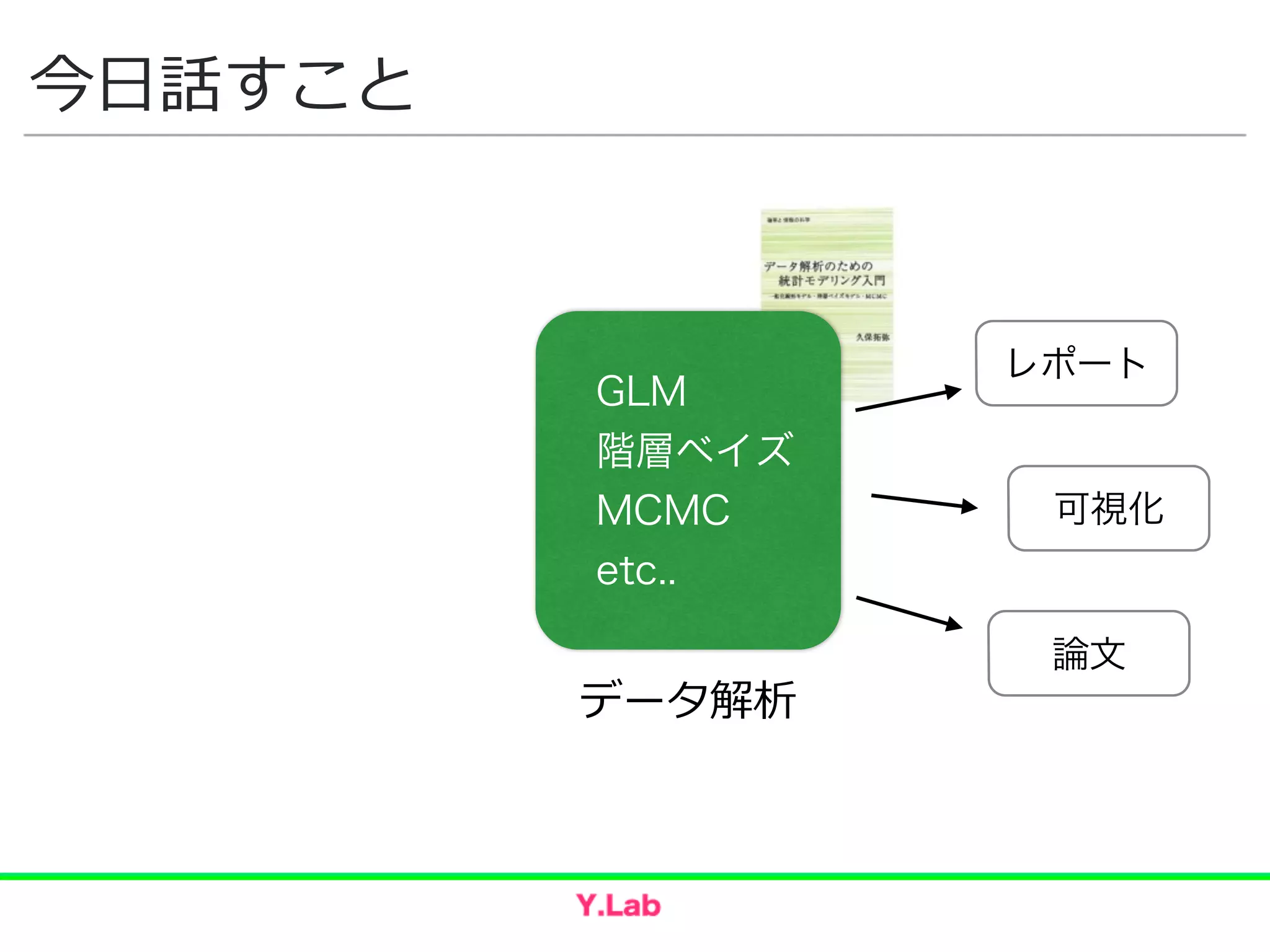
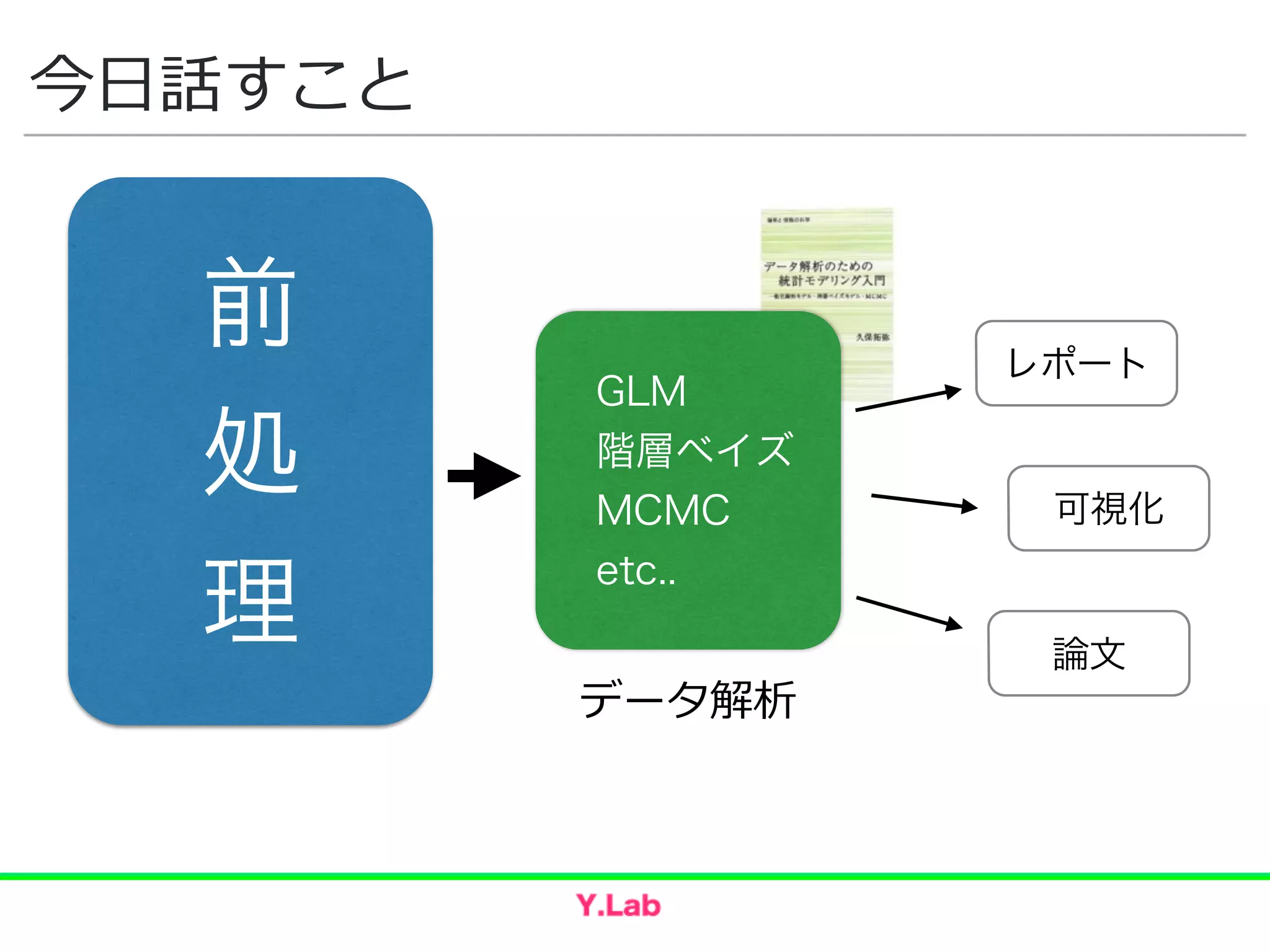
How to have difficult conversations Awkでeffective前処理
- 1.
- 2.
⾃自⼰己紹介
○研究テーマ
スペースデブリの軌道設計
Deeplearningを⽤用いた画像認識識 <-‐‑‒ いまここ
○バイト
ALBERT -‐‑‒ 集計、分析のお仕事
○趣味とか
ラグビー、Python、お酒、⿇麻雀
@aki_̲n1wa
秋庭 伸也
早稲⽥田⼤大学 -‐‑‒ 機械科学専攻 M2
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
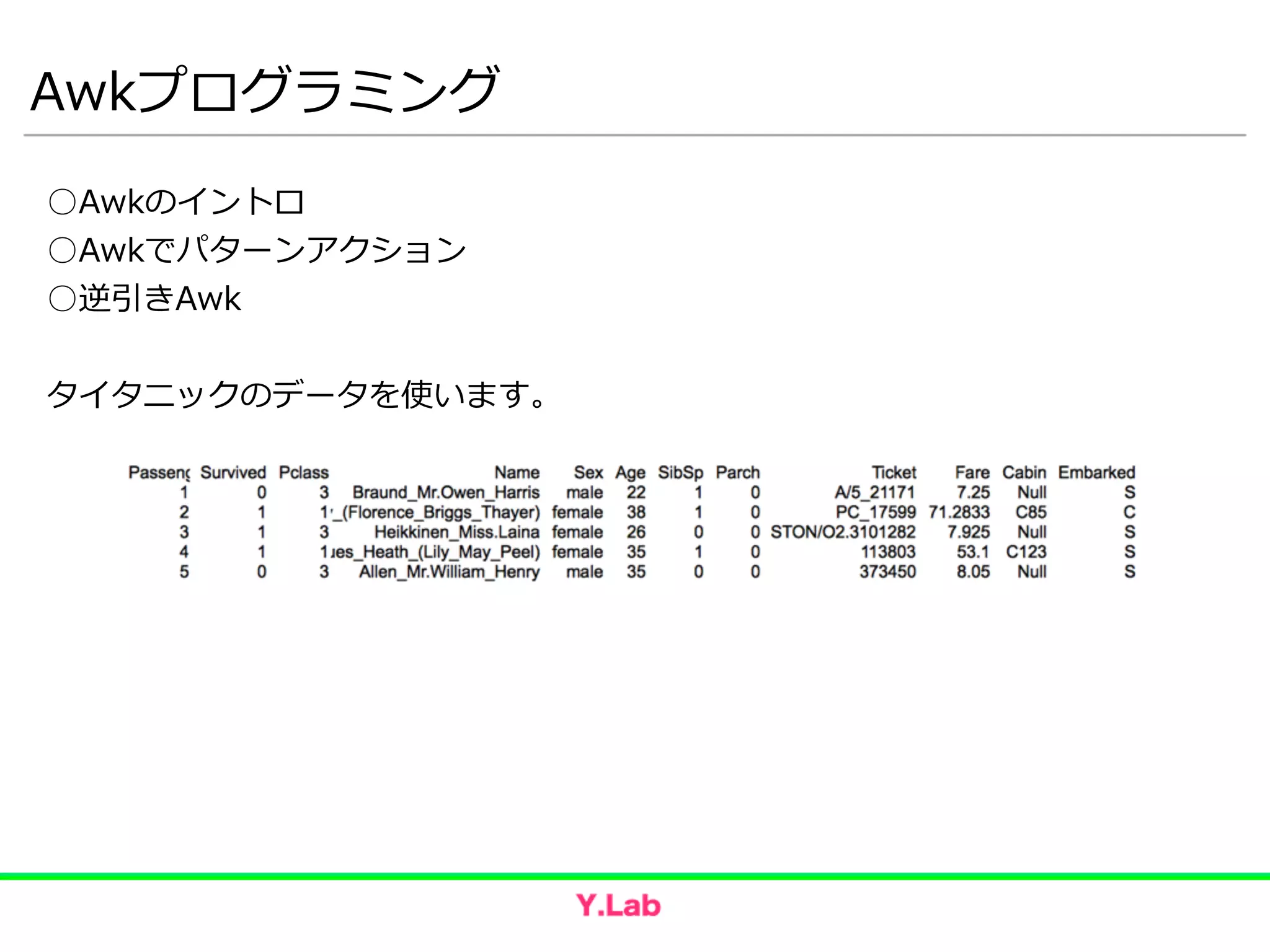
Awkって何?
○開発者: Aho, Weinberger, and Kernighan
!
○ファイル処理理⾔言語(コマンド)
!
○Cっぽい構⽂文
!
○Awkの良良いところ
学習曲線ゆるやか
ワンライナー ~∼ 数ライナー
!
○Awkが苦⼿手なこと
ちょっと複雑なデータ(リレーショナルとか)
*.xlsx
- 10.
- 11.
○全⾏行行表⽰示
awk {print $0}titanic.txt
awkスクリプト 入力ファイル
awk {スクリプト} ファイル名
Awkのイントロ
○基本の形
1⾏行行⽬目
2⾏行行⽬目
3⾏行行⽬目
4⾏行行⽬目
…
awkスクリプトを⼊入⼒力力ファイルの1⾏行行⽬目から最終⾏行行まで
1⾏行行ずつ実⾏行行していく。
print $0 →
print $0 →
print $0 →
print $0 →
print $0 →
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
おまけ
○.txtのビジュアライゼーション awk -fgraph.awk hist.txt
[shinya@ShineAir:~/Programs/awk_preprocess]$ awk -f graph.awk hist.txt
|------------------------------------------------------------------------|
| |
| |
| |
12 - * |
| |
| * |
| * |
| |
| |
8 - |
| |
| |
| |
| * |
4 - * * |
| |
| * |
| |
| |
| * |
|-----------|-----------|------------|-----------|-----------|-----------|
0 2 4 6 8
Poisson hist
- 19.











![Awkのパターンアクション
○⾏行行頭が10, 11, 12, 14で始まる⾏行行を表⽰示
awk '/^1[0-3]/{print $0}' titanic.txt
awk $6>=40{print $0} titanic.txt
○40歳以上を表⽰示](https://image.slidesharecdn.com/awkeffective-140527062907-phpapp02/75/Awk-effective-14-2048.jpg)
![逆引きAwk
○最⼩小値を求める
awk 'NR==2{min=$10}{if($10<min) {min=$10};} END {print min}' titanic.txt
awk '{age+=$6};END{print age/(NR-1)}' titanic.txt
○平均年年齢
終了時に呼ばれる
○乗船場所の重複削除
awk '!colname[$12]++{print $12}'
○乗客IDと年年齢を表⽰示
awk '{print $1, $6}' titanic.txt](https://image.slidesharecdn.com/awkeffective-140527062907-phpapp02/75/Awk-effective-15-2048.jpg)


![おまけ
○.txtのビジュアライゼーション awk -f graph.awk hist.txt
[shinya@ShineAir:~/Programs/awk_preprocess]$ awk -f graph.awk hist.txt
|------------------------------------------------------------------------|
| |
| |
| |
12 - * |
| |
| * |
| * |
| |
| |
8 - |
| |
| |
| |
| * |
4 - * * |
| |
| * |
| |
| |
| * |
|-----------|-----------|------------|-----------|-----------|-----------|
0 2 4 6 8
Poisson hist](https://image.slidesharecdn.com/awkeffective-140527062907-phpapp02/75/Awk-effective-18-2048.jpg)
