Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
SN
Uploaded by
Sho Nakazono
PDF, PPTX
6,224 views
並行実行制御の最適化手法
2017年3月29日に開催された第七回ビッグデータ基盤技術研究会(BDI研究会)での発表資料です。
Software
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PPTX
A critique of ansi sql isolation levels 解説公開用
by
Takashi Kambayashi
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PDF
論文紹介: An empirical evaluation of in-memory multi-version concurrency control
by
Sho Nakazono
PPTX
Dbts 分散olt pv2
by
Takashi Kambayashi
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
クラウドを支える基盤技術の最新動向と今後の方向性
by
Masayoshi Hagiwara
PPTX
地理分散DBについて
by
Kumazaki Hiroki
PDF
ceph acceleration and storage architecture
by
Yuki Kitajima
A critique of ansi sql isolation levels 解説公開用
by
Takashi Kambayashi
トランザクションの設計と進化
by
Kumazaki Hiroki
論文紹介: An empirical evaluation of in-memory multi-version concurrency control
by
Sho Nakazono
Dbts 分散olt pv2
by
Takashi Kambayashi
分散システムについて語らせてくれ
by
Kumazaki Hiroki
クラウドを支える基盤技術の最新動向と今後の方向性
by
Masayoshi Hagiwara
地理分散DBについて
by
Kumazaki Hiroki
ceph acceleration and storage architecture
by
Yuki Kitajima
What's hot
PDF
Linux女子部 firewalld徹底入門!
by
Etsuji Nakai
PDF
Linux デスクトップ環境のセキュリティを考えてみる
by
Kenichiro MATOHARA
PPTX
輪読資料: Staring into the abyss an evaluation of concurrency control with one t...
by
Sho Nakazono
PDF
AWS re:Invent2017で見た AWSの強さとは
by
NTT Communications Technology Development
PDF
ネットワーク仮想化ソフトウェアMidoNet ユースケースとユーザメリット
by
Midokura
PDF
Try andstudy cloud_20120509_nagoya
by
Etsuji Nakai
PDF
2014.03.19 linux joshi_security_public
by
Ryo Fujita
PDF
OpenStack Kilo with 6Wind VA High-Performance Networking Using DPDK - OpenSta...
by
VirtualTech Japan Inc.
PDF
GlusterFS Updates (and more) in 第六回クラウドストレージ研究会
by
Keisuke Takahashi
PDF
Troveコミュニティ動向
by
NTT Communications Technology Development
PDF
Linux女子部 systemd徹底入門
by
Etsuji Nakai
PPT
Javaでトランザクショナルメモリを使う
by
Kenji Kazumura
PDF
OpenStackネットワーキング管理者入門 - OpenStack最新情報セミナー 2014年8月
by
VirtualTech Japan Inc.
PDF
Sheepdogを使ってみて分かったこと(第六回ストレージ研究会発表資料)
by
Masahiro Tsuji
PDF
openstack+cephインテグレーション
by
OSSラボ株式会社
PDF
OSSラボ様講演 OpenStack最新情報セミナー 2014年6月
by
VirtualTech Japan Inc.
PDF
OSC.Cloud 2012 分散システムを支えるメッセージングの仕組み
by
irix_jp
PDF
CloudStackユーザ会 OSC.cloud
by
samemoon
PDF
SSL/TLSの基礎と最新動向
by
shigeki_ohtsu
Linux女子部 firewalld徹底入門!
by
Etsuji Nakai
Linux デスクトップ環境のセキュリティを考えてみる
by
Kenichiro MATOHARA
輪読資料: Staring into the abyss an evaluation of concurrency control with one t...
by
Sho Nakazono
AWS re:Invent2017で見た AWSの強さとは
by
NTT Communications Technology Development
ネットワーク仮想化ソフトウェアMidoNet ユースケースとユーザメリット
by
Midokura
Try andstudy cloud_20120509_nagoya
by
Etsuji Nakai
2014.03.19 linux joshi_security_public
by
Ryo Fujita
OpenStack Kilo with 6Wind VA High-Performance Networking Using DPDK - OpenSta...
by
VirtualTech Japan Inc.
GlusterFS Updates (and more) in 第六回クラウドストレージ研究会
by
Keisuke Takahashi
Troveコミュニティ動向
by
NTT Communications Technology Development
Linux女子部 systemd徹底入門
by
Etsuji Nakai
Javaでトランザクショナルメモリを使う
by
Kenji Kazumura
OpenStackネットワーキング管理者入門 - OpenStack最新情報セミナー 2014年8月
by
VirtualTech Japan Inc.
Sheepdogを使ってみて分かったこと(第六回ストレージ研究会発表資料)
by
Masahiro Tsuji
openstack+cephインテグレーション
by
OSSラボ株式会社
OSSラボ様講演 OpenStack最新情報セミナー 2014年6月
by
VirtualTech Japan Inc.
OSC.Cloud 2012 分散システムを支えるメッセージングの仕組み
by
irix_jp
CloudStackユーザ会 OSC.cloud
by
samemoon
SSL/TLSの基礎と最新動向
by
shigeki_ohtsu
Viewers also liked
PDF
How to Become a Thought Leader in Your Niche
by
Leslie Samuel
PPTX
アルゴリズム取引のシステムを開発・運用してみて分かったこと
by
Satoshi KOBAYASHI
PDF
Functional go
by
Geison Goes
PPTX
安全なPHPアプリケーションの作り方2016
by
Hiroshi Tokumaru
PDF
Kameoka2017 ieice03
by
kame_hirokazu
PDF
ドメインロジックに集中せよ 〜ドメイン駆動設計 powered by Spring
by
増田 亨
PDF
こわくないよ❤️ Playframeworkソースコードリーディング入門
by
tanacasino
PPTX
情報統計力学のすすめ
by
Naoki Hayashi
PDF
エンジニアのブログ書きの 心技体
by
Kenji Tanaka
PDF
2017年グローバルリクルーティングトレンド / Global Recruiting Trend
by
LinkedIn Japan / リンクトイン・ジャパン
PDF
数値解析と物理学
by
すずしめ
PDF
マイクロサービスバックエンドAPIのためのRESTとgRPC
by
disc99_
PDF
Information sharing and Experience consistency at Cookpad mobile application
by
ichiko_revjune
PDF
Xamarin の概要と活用事例
by
Yoshito Tabuchi
PDF
Kameoka2016 miru08
by
kame_hirokazu
PPTX
PIXTAにおけるABテスト
by
PIXTA Inc.
PDF
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
PPTX
30分後から すぐに使える 会話技術
by
Seongsoon Lim
PDF
WALをバックアップとレプリケーションに使う方法
by
Takashi Hoshino
PDF
IPDPS & HPDC 報告
by
Junya Arai
How to Become a Thought Leader in Your Niche
by
Leslie Samuel
アルゴリズム取引のシステムを開発・運用してみて分かったこと
by
Satoshi KOBAYASHI
Functional go
by
Geison Goes
安全なPHPアプリケーションの作り方2016
by
Hiroshi Tokumaru
Kameoka2017 ieice03
by
kame_hirokazu
ドメインロジックに集中せよ 〜ドメイン駆動設計 powered by Spring
by
増田 亨
こわくないよ❤️ Playframeworkソースコードリーディング入門
by
tanacasino
情報統計力学のすすめ
by
Naoki Hayashi
エンジニアのブログ書きの 心技体
by
Kenji Tanaka
2017年グローバルリクルーティングトレンド / Global Recruiting Trend
by
LinkedIn Japan / リンクトイン・ジャパン
数値解析と物理学
by
すずしめ
マイクロサービスバックエンドAPIのためのRESTとgRPC
by
disc99_
Information sharing and Experience consistency at Cookpad mobile application
by
ichiko_revjune
Xamarin の概要と活用事例
by
Yoshito Tabuchi
Kameoka2016 miru08
by
kame_hirokazu
PIXTAにおけるABテスト
by
PIXTA Inc.
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
30分後から すぐに使える 会話技術
by
Seongsoon Lim
WALをバックアップとレプリケーションに使う方法
by
Takashi Hoshino
IPDPS & HPDC 報告
by
Junya Arai
Similar to 並行実行制御の最適化手法
PDF
トランザクションの並行実行制御 rev.2
by
Takashi Hoshino
PDF
トランザクションの並行処理制御
by
Takashi Hoshino
PDF
できる!並列・並行プログラミング
by
Preferred Networks
PPT
Transactional Information Systems入門
by
nobu_k
PPTX
トランザクションをSerializableにする4つの方法
by
Kumazaki Hiroki
PDF
Serializabilityとは何か
by
Takashi Hoshino
PDF
Principles of Transaction Processing Second Edition 9章 4~9節
by
Yuichiro Saito
PPTX
Fork/Join Framework
by
Appresso Engineering Team
PPTX
Checkpointing Algorithms on In-memory DBMS
by
Sho Nakazono
PDF
PostgreSQLレプリケーション徹底紹介
by
NTT DATA OSS Professional Services
PDF
[Basic 9] 並列処理 / 排他制御
by
Yuto Takei
PDF
PostgreSQL9.1でつくる高可用性にまつわるエトセトラ
by
NTT DATA OSS Professional Services
PDF
Intel TSX について x86opti
by
Takashi Hoshino
PDF
Richard high performance fuzzing ja
by
PacSecJP
PPTX
非同期処理の基礎
by
信之 岩永
PPTX
大規模分散システムの現在 -- Twitter
by
maruyama097
PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
PDF
Isolation Level について
by
Takashi Hoshino
PDF
データベース12 - トランザクションと同時実行制御
by
Kenta Oku
PDF
PostgreSQLのパラレル化に向けた取り組み@第30回(仮名)PostgreSQL勉強会
by
Shigeru Hanada
トランザクションの並行実行制御 rev.2
by
Takashi Hoshino
トランザクションの並行処理制御
by
Takashi Hoshino
できる!並列・並行プログラミング
by
Preferred Networks
Transactional Information Systems入門
by
nobu_k
トランザクションをSerializableにする4つの方法
by
Kumazaki Hiroki
Serializabilityとは何か
by
Takashi Hoshino
Principles of Transaction Processing Second Edition 9章 4~9節
by
Yuichiro Saito
Fork/Join Framework
by
Appresso Engineering Team
Checkpointing Algorithms on In-memory DBMS
by
Sho Nakazono
PostgreSQLレプリケーション徹底紹介
by
NTT DATA OSS Professional Services
[Basic 9] 並列処理 / 排他制御
by
Yuto Takei
PostgreSQL9.1でつくる高可用性にまつわるエトセトラ
by
NTT DATA OSS Professional Services
Intel TSX について x86opti
by
Takashi Hoshino
Richard high performance fuzzing ja
by
PacSecJP
非同期処理の基礎
by
信之 岩永
大規模分散システムの現在 -- Twitter
by
maruyama097
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
Isolation Level について
by
Takashi Hoshino
データベース12 - トランザクションと同時実行制御
by
Kenta Oku
PostgreSQLのパラレル化に向けた取り組み@第30回(仮名)PostgreSQL勉強会
by
Shigeru Hanada
More from Sho Nakazono
PDF
述語ロックの歴史 r2
by
Sho Nakazono
PDF
LineairDBの紹介 MySQL編
by
Sho Nakazono
PDF
LineairDBの紹介
by
Sho Nakazono
PDF
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
PPTX
ファントム異常を排除する高速なトランザクション処理向けインデックス
by
Sho Nakazono
PDF
LineairDB: Fast and Embedded Transactional Key-Value Storage
by
Sho Nakazono
PDF
論文紹介: Cuckoo filter: practically better than bloom
by
Sho Nakazono
PPTX
[xSIG 2018]InvisibleWriteRule: Extended write protocol for 1VCC
by
Sho Nakazono
述語ロックの歴史 r2
by
Sho Nakazono
LineairDBの紹介 MySQL編
by
Sho Nakazono
LineairDBの紹介
by
Sho Nakazono
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
ファントム異常を排除する高速なトランザクション処理向けインデックス
by
Sho Nakazono
LineairDB: Fast and Embedded Transactional Key-Value Storage
by
Sho Nakazono
論文紹介: Cuckoo filter: practically better than bloom
by
Sho Nakazono
[xSIG 2018]InvisibleWriteRule: Extended write protocol for 1VCC
by
Sho Nakazono
並行実行制御の最適化手法
1.
Copyright©2017 NTT corp.
All Rights Reserved. 並行実行制御の最適化手法 NTT ソフトウェアイノベーションセンタ 中園 翔 nakazono.sho@lab.ntt.co.jp
2.
2Copyright©2017 NTT corp.
All Rights Reserved. トランザクション: • 不可分な一連の操作 == n回のread/write操作(0<n) トランザクション処理の目標: • Atomicity: n回のread/write操作を1回のレジスタ操作と同様に扱えること • Consistency: 一貫性を守ること. A,I,Dに加えてDBの制約条件を常に満たすこと • Isolation: トランザクションが他の並行するTxの影響を受けないこと • Durability: コミット済みのトランザクションは必ず永続化されていること トランザクション処理の構成要素: • ログ管理機構(Log manager) • 並行実行制御(Concurrency Control) • データ構造, インデックス(Data Structure) トランザクションと並行実行制御
3.
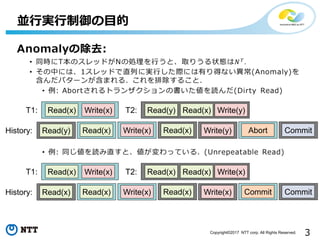
3Copyright©2017 NTT corp.
All Rights Reserved. 並行実行制御の目的 T1: Read(x) Write(x) T2: Read(y) Write(y)Read(x) Read(x) Write(x)History: Read(x)Read(y) AbortWrite(y) Commit T1: Read(x) Write(x) T2: Read(x) Write(x)Read(x) Read(x) Write(x)History: Read(x)Read(x) CommitWrite(x) Commit
4.
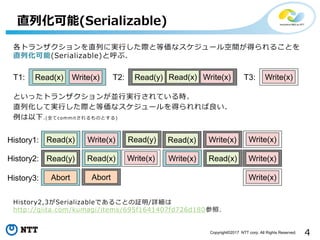
4Copyright©2017 NTT corp.
All Rights Reserved. 各トランザクションを直列に実行した際と等価なスケジュール空間が得られることを 直列化可能(Serializable)と呼ぶ. といったトランザクションが並行実行されている時、 直列化して実行した際と等価なスケジュールを得られれば良い. 例は以下.(全てcommitされるものとする) History2,3がSerializableであることの証明/詳細は http://qiita.com/kumagi/items/695f1641407fd726d180参照. 直列化可能(Serializable) T1: Read(x) Write(x) T2: Read(y) Write(x)Read(x) T3: Write(x) Read(x) Write(x)History1: Read(y) Read(x) Write(x) Write(x) Read(x) Write(x)History2: Read(x)Read(y) Write(x)Write(x) History3: Write(x)Abort Abort
5.
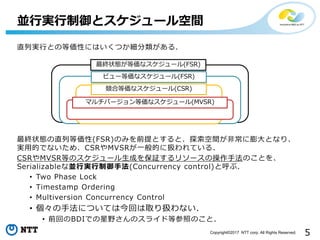
5Copyright©2017 NTT corp.
All Rights Reserved. 直列実行との等価性にはいくつか細分類がある. 最終状態の直列等価性(FSR)のみを前提とすると、探索空間が非常に膨大となり、 実用的でないため、CSRやMVSRが一般的に扱われている. CSRやMVSR等のスケジュール生成を保証するリソースの操作手法のことを、 Serializableな並行実行制御手法(Concurrency control)と呼ぶ. • Two Phase Lock • Timestamp Ordering • Multiversion Concurrency Control • 個々の手法については今回は取り扱わない. • 前回のBDIでの星野さんのスライド等参照のこと. 並行実行制御とスケジュール空間 最終状態が等価なスケジュール(FSR) ビュー等価なスケジュール(FSR) 競合等価なスケジュール(CSR) マルチバージョン等価なスケジュール(MVSR)
6.
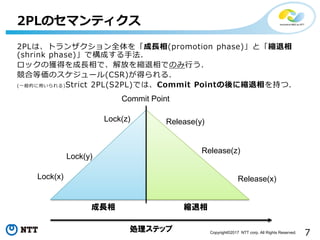
6Copyright©2017 NTT corp.
All Rights Reserved. 例えば、2PLのプロトコルに従う実装を考える. 2PLのプロトコルは、要旨としては以下. • 「ロックの獲得と解放を二相に分割する」 • 「コミットのタイミングで細分類があり、得られるスケジュールが異なる」 • ナイーブに実装すれば「ロック獲得->ロジック->コミット->ロック解放?」 何を「ロック」と見なすか、何を「コミット」と見なすか等、実装上の最適化 の幅がある. 今回は、エンジニアリング的な最適化手法と理論的な最適化手法を紹介する. 並行実行制御の最適化手法
7.
7Copyright©2017 NTT corp.
All Rights Reserved. 2PLは、トランザクション全体を「成長相(promotion phase)」と「縮退相 (shrink phase)」で構成する手法. ロックの獲得を成長相で、解放を縮退相でのみ行う. 競合等価のスケジュール(CSR)が得られる. (一般的に用いられる)Strict 2PL(S2PL)では、Commit Pointの後に縮退相を持つ. 2PLのセマンティクス 成長相 縮退相 Lock(x) Lock(y) 処理ステップ Lock(z) Release(y) Release(z) Release(x) Commit Point
8.
8Copyright©2017 NTT corp.
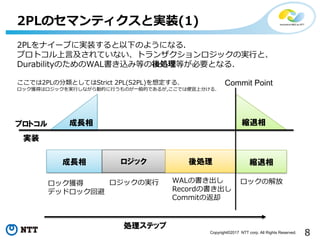
All Rights Reserved. 2PLをナイーブに実装すると以下のようになる. プロトコル上言及されていない、トランザクションロジックの実行と、 DurabilityのためのWAL書き込み等の後処理等が必要となる. ここでは2PLの分類としてはStrict 2PL(S2PL)を想定する. ロック獲得はロジックを実行しながら動的に行うものが一般的であるが,ここでは便宜上分ける. 2PLのセマンティクスと実装(1) 成長相 縮退相 成長相 ロジック 縮退相 ロック獲得 デッドロック回避 ロジックの実行 ロックの解放 Commit Point WALの書き出し Recordの書き出し Commitの返却 後処理 プロトコル 実装 処理ステップ
9.
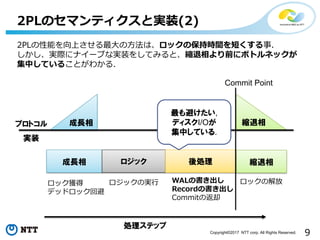
9Copyright©2017 NTT corp.
All Rights Reserved. 2PLのセマンティクスと実装(2) 成長相 縮退相 成長相 ロジック 縮退相 Commit Point 2PLの性能を向上させる最大の方法は、ロックの保持時間を短くする事. しかし、実際にナイーブな実装をしてみると、縮退相より前にボトルネックが 集中していることがわかる. 後処理 プロトコル 実装 処理ステップ ロック獲得 デッドロック回避 ロジックの実行 ロックの解放WALの書き出し Recordの書き出し Commitの返却 最も避けたい, ディスクI/Oが 集中している.
10.
10Copyright©2017 NTT corp.
All Rights Reserved. A: I/O Related Delays レコードを書き終わるまでのI/O wait. B: Log-induced lock contention Aに起因するロック保持時間の増加. それに伴うロックの競合. C: Excessive context switching Aを待つ間、スピンする訳にもいかないので、 waitする必要がある. このスケジューラ負荷. D: Log buffer contention 例えば、WALログとレコードの書き込みを単一 のmutexで管理している場合、WALもwaitする ことになる. このログバッファで競合が起きる. Aether [Johnson et al, VLDB 2010] Ryan Johnson, Ippokratis Pandis, Radu Stoica, Manos Athanassoulis, and Anastasia Ailamaki. 2010. Aether: a scalable approach to logging. Proc. VLDB Endow. 3, 1-2 (September 2010), 681-692. DOI=http://dx.doi.org/10.14778/1920841.1920928 Aetherでは、従来のトランザクションのセマンティクスを、2PLやOCCのセマンテ ィクスに違反しないままうまく変更し、実装上のボトルネックを解決している. 具体的には、以下のボトルネックを問題として挙げている.
11.
11Copyright©2017 NTT corp.
All Rights Reserved. ログが直列化されている限り、クライアントにCommitを返却さえしなければ、ログ が永続化される前にロックを解放しても2PL/OCCの性質は変わらないという提案. ログの書き出し順序が決定した瞬間(バッファにenqueueした瞬間)をpre-commit と呼び、この瞬間を2PL/OCCにおけるCommit Pointと見なす. 仮に、あるTxが未commitの永続化されていない値を読んだとしても、読めた(ロック が解放されている)以上、必ずpre-commit済みの値であることになる. ログバッファが順序付けされている以上、このTxの永続化が先行することはない. AetherのEarly Lock Release 成長相 ロジック 縮退相 precommit point 後処理 ロック獲得 デッドロック回避 ロジックの実行 ロックの解放ログバッファ へのenqueue Recordの 書き出し Commitの 返却 コミット返却
12.
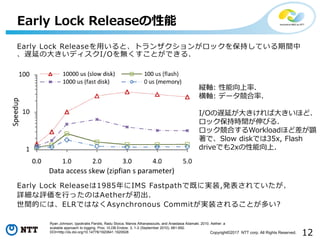
12Copyright©2017 NTT corp.
All Rights Reserved. Early Lock Releaseを用いると、トランザクションがロックを保持している期間中 、遅延の大きいディスクI/Oを無くすことができる. Early Lock Releaseは1985年にIMS Fastpathで既に実装,発表されていたが、 詳細な評価を行ったのはAetherが初出. 世間的には、ELRではなくAsynchronous Commitが実装されることが多い? Early Lock Releaseの性能 縦軸: 性能向上率. 横軸: データ競合率. I/Oの遅延が大きければ大きいほど、 ロック保持時間が伸びる. ロック競合するWorkloadほど差が顕 著で、Slow diskでは35x, Flash driveでも2xの性能向上. Ryan Johnson, Ippokratis Pandis, Radu Stoica, Manos Athanassoulis, and Anastasia Ailamaki. 2010. Aether: a scalable approach to logging. Proc. VLDB Endow. 3, 1-2 (September 2010), 681-692. DOI=http://dx.doi.org/10.14778/1920841.1920928
13.
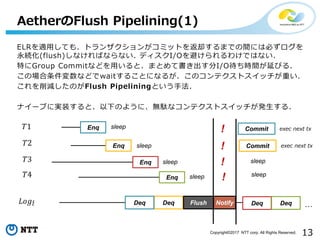
13Copyright©2017 NTT corp.
All Rights Reserved. ELRを適用しても、トランザクションがコミットを返却するまでの間には必ずログを 永続化(flush)しなければならない. ディスクI/Oを避けられるわけではない. 特にGroup Commitなどを用いると、まとめて書き出す分I/O待ち時間が延びる. この場合条件変数などでwaitすることになるが、このコンテクストスイッチが重い. これを削減したのがFlush Pipeliningという手法. ナイーブに実装すると、以下のように、無駄なコンテクストスイッチが発生する. AetherのFlush Pipelining(1) … sleep sleep Enq DeqDeq Flush Notify sleep ! ! ! sleep ! Enq Enq Commit Commit sleep sleepEnq Deq Deq exec next tx exec next tx
14.
14Copyright©2017 NTT corp.
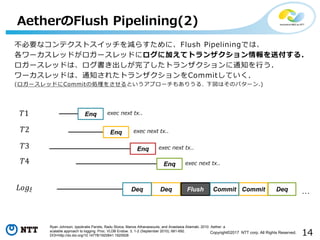
All Rights Reserved. 不必要なコンテクストスイッチを減らすために、Flush Pipeliningでは、 各ワーカスレッドがロガースレッドにログに加えてトランザクション情報を送付する. ロガースレッドは、ログ書き出しが完了したトランザクションに通知を行う. ワーカスレッドは、通知されたトランザクションをCommitしていく. (ロガースレッドにCommitの処理をさせるというアプローチもありうる. 下図はそのパターン.) AetherのFlush Pipelining(2) Ryan Johnson, Ippokratis Pandis, Radu Stoica, Manos Athanassoulis, and Anastasia Ailamaki. 2010. Aether: a scalable approach to logging. Proc. VLDB Endow. 3, 1-2 (September 2010), 681-692. DOI=http://dx.doi.org/10.14778/1920841.1920928 Enq DeqDeq Flush Enq Enq Enq DeqCommitCommit … exec next tx.. exec next tx.. exec next tx.. exec next tx..
15.
15Copyright©2017 NTT corp.
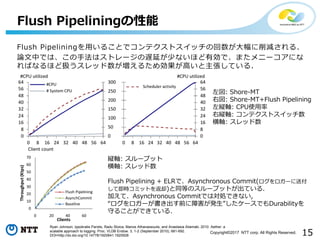
All Rights Reserved. Flush Pipeliningの性能 Flush Pipeliningを用いることでコンテクストスイッチの回数が大幅に削減される. 論文中では、この手法はストレージの遅延が少ないほど有効で、またメニーコアにな ればなるほど扱うスレッド数が増えるため効果が高いと主張している. Ryan Johnson, Ippokratis Pandis, Radu Stoica, Manos Athanassoulis, and Anastasia Ailamaki. 2010. Aether: a scalable approach to logging. Proc. VLDB Endow. 3, 1-2 (September 2010), 681-692. DOI=http://dx.doi.org/10.14778/1920841.1920928 左図: Shore-MT 右図: Shore-MT+Flush Pipelining 左縦軸: CPU使用率 右縦軸: コンテクストスイッチ数 横軸: スレッド数 縦軸: スループット 横軸: スレッド数 Flush Pipelining + ELRで、Asynchronous Commit(ログをロガーに送付 して即時コミットを返却)と同等のスループットが出ている. 加えて、Asynchronous Commitでは対処できない, “ログをロガーが書き出す前に障害が発生”したケースでもDurabilityを 守ることができている.
16.
16Copyright©2017 NTT corp.
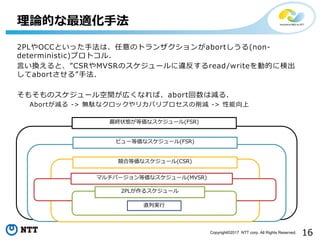
All Rights Reserved. 2PLやOCCといった手法は、任意のトランザクションがabortしうる(non- deterministic)プロトコル. 言い換えると、”CSRやMVSRのスケジュールに違反するread/writeを動的に検出 してabortさせる”手法. そもそものスケジュール空間が広くなれば、abort回数は減る. Abortが減る -> 無駄なクロックやリカバリプロセスの削減 -> 性能向上 理論的な最適化手法 最終状態が等価なスケジュール(FSR) ビュー等価なスケジュール(FSR) 競合等価なスケジュール(CSR) マルチバージョン等価なスケジュール(MVSR) 2PLが作るスケジュール 直列実行
17.
17Copyright©2017 NTT corp.
All Rights Reserved. スケジュール空間と性能差の例 T1: Read(x) Write(y) T2: Read(x) Read(z)Read(y) Read(x) Write(y)History: Read(y) Read(z)Read(x) Read(x1) Write(x2)History: Read(y1) Read(z1)Read(x1) [1] H. T. Kung and John T. Robinson. 1981. On optimistic methods for concurrency control. ACM Trans. Database Syst. 6, 2 (June 1981)
18.
18Copyright©2017 NTT corp.
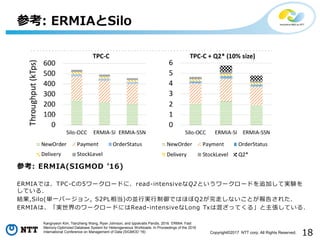
All Rights Reserved. 参考: ERMIAとSilo Kangnyeon Kim, Tianzheng Wang, Ryan Johnson, and Ippokratis Pandis. 2016. ERMIA: Fast Memory-Optimized Database System for Heterogeneous Workloads. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD '16) 参考: ERMIA(SIGMOD ’16) ERMIAでは、TPC-Cの5ワークロードに、read-intensiveなQ2というワークロードを追加して実験を している. 結果,Silo(単一バージョン, S2PL相当)の並行実行制御ではほぼQ2が完走しないことが報告された. ERMIAは、「実世界のワークロードにはRead-intensiveなLong Txは混ざってくる」と主張している.
19.
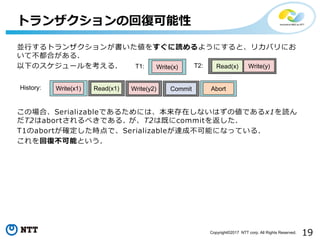
19Copyright©2017 NTT corp.
All Rights Reserved. 並行するトランザクションが書いた値をすぐに読めるようにすると、リカバリにお いて不都合がある. 以下のスケジュールを考える. この場合、Serializableであるためには、本来存在しないはずの値であるx1を読ん だT2はabortされるべきである. が、T2は既にcommitを返した. T1のabortが確定した時点で、Serializableが達成不可能になっている. これを回復不可能という. トランザクションの回復可能性 T1: Write(x) T2: Read(x) Write(y) AbortHistory: Read(x1) Write(y2)Write(x1) Commit
20.
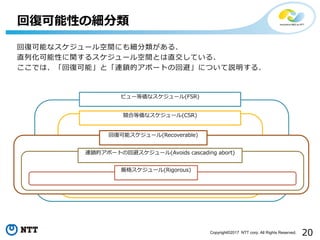
20Copyright©2017 NTT corp.
All Rights Reserved. 回復可能なスケジュール空間にも細分類がある. 直列化可能性に関するスケジュール空間とは直交している. ここでは、「回復可能」と「連鎖的アボートの回避」について説明する. 回復可能性の細分類 ビュー等価なスケジュール(FSR) 競合等価なスケジュール(CSR) 回復可能スケジュール(Recoverable) 連鎖的アボートの回避スケジュール(Avoids cascading abort) 厳格スケジュール(Rigorous)
21.
21Copyright©2017 NTT corp.
All Rights Reserved. 回復可能 T1: Write(x) T2: Read(x) Write(y) AbortHistory: Read(x1) Write(y2)Write(x1) [2] G. Weikum and G. Vossen. Transactional information systems: theory, algorithms, and the practice of concurrency control and recovery. Morgan Kaufmann Publishers Inc.,San Francisco, CA, USA, 2001. ISBN 1-55860-508-8. [3] 北川博之, データベースシステム, オーム社, 2014, ISBN 4274216055
22.
22Copyright©2017 NTT corp.
All Rights Reserved. 連鎖的アボートの回避 T1: Write(x) T2: Read(x) Write(y) AbortHistory: Read(x1) Write(y2)Write(x1) [2] G. Weikum and G. Vossen. Transactional information systems: theory, algorithms, and the practice of concurrency control and recovery. Morgan Kaufmann Publishers Inc.,San Francisco, CA, USA, 2001. ISBN 1-55860-508-8. [3] 北川博之, データベースシステム, オーム社, 2014, ISBN 4274216055 AbortHistory: Read(x1) Write(y2)Write(x1) Read(x1) Read(x1) ......Read(x1)
23.
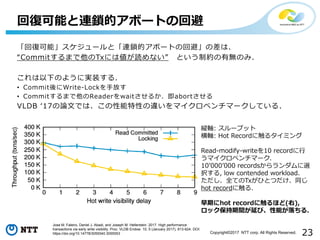
23Copyright©2017 NTT corp.
All Rights Reserved. 「回復可能」スケジュールと「連鎖的アボートの回避」の差は、 “Commitするまで他のTxには値が読めない” という制約の有無のみ. これは以下のように実装する. • Commit後にWrite-Lockを手放す • Commitするまで他のReaderをwaitさせるか、即abortさせる VLDB ‘17の論文では、この性能特性の違いをマイクロベンチマークしている. 回復可能と連鎖的アボートの回避 Jose M. Faleiro, Daniel J. Abadi, and Joseph M. Hellerstein. 2017. High performance transactions via early write visibility. Proc. VLDB Endow. 10, 5 (January 2017), 613-624. DOI: https://doi.org/10.14778/3055540.3055553 縦軸: スループット 横軸: Hot Recordに触るタイミング Read-modify-writeを10 recordに行 うマイクロベンチマーク. 10’000’000 recordsからランダムに選 択する, low contended workload. ただし、全てのTxがひとつだけ、同じ hot recordに触る. 早期にhot recordに触るほど(右), ロック保持期間が延び、性能が落ちる.
24.
24Copyright©2017 NTT corp.
All Rights Reserved. 回復可能スケジュールの適用 「連鎖的アボートの回避」を実装すると、全てのロックを同じタイミング(コミット 時)まで手放すことができない. これを改善し、かつ「連鎖的アボート」の性能ペナルティは最小限にしたい. そこで”部分的に” 回復可能スケジュールを適用することで性能を向上させる、以下 の手法が提案されている. • Group Commit [Gawlick et al. DE Bull 1985] • Early Lock Release [Johnson et al. VLDB 2010] • Speculative Read/Speculative Ignore [Larson et al. VLDB 2011] • Piece-Wise Visibility(PWV)[Faleiro et al. VLDB 2017] 前述したGroup Commit/ELRも「回復可能と連鎖的アボートの回避」の観点で説 明できる. というのが面白い.
25.
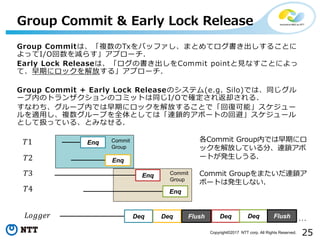
25Copyright©2017 NTT corp.
All Rights Reserved. Group Commitは、「複数のTxをバッファし、まとめてログ書き出しすることに よってI/O回数を減らす」アプローチ. Early Lock Releaseは、「ログの書き出しをCommit pointと見なすことによっ て、早期にロックを解放する」アプローチ. Group Commit + Early Lock Releaseのシステム(e.g. Silo)では、同じグル ープ内のトランザクションのコミットは同じI/Oで確定され返却される. すなわち、グループ内では早期にロックを解放することで「回復可能」スケジュー ルを適用し、複数グループを全体としては「連鎖的アボートの回避」スケジュール として扱っている、とみなせる. Group Commit & Early Lock Release Enq Enq DeqDeq Flush Enq Enq …Deq Deq Flush Commit Group Commit Group 各Commit Group内では早期にロ ックを解放している分、連鎖アボ ートが発生しうる. Commit Groupをまたいだ連鎖ア ボートは発生しない. 𝐿𝑜𝑔𝑔𝑒𝑟
26.
26Copyright©2017 NTT corp.
All Rights Reserved. Hekatonの前身となるMVCC論文では以下の構造体でMVCCを実装している. HekatonのSpeculative Read(1) Begin: このレコードを書いたTxのId End: 次のレコードのTxのId or INFINITY Name: Key Amount: Value Hash ptr: 次のレコードへのポインタ Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. High-performance concurrency control mechanisms for main-memory databases. Proc. VLDB Endow. 5, 4 (December 2011), 298-309. DOI=http://dx.doi.org/10.14778/2095686.2095689
27.
27Copyright©2017 NTT corp.
All Rights Reserved. HekatonのSpeculative Read(2) [1] Xiangyao Yu, George Bezerra, Andrew Pavlo, Srinivas Devadas, and Michael Stonebraker. 2014. Staring into the abyss: an evaluation of concurrency control with one thousand cores. Proc. VLDB Endow. 8, 3 (November 2014), 209-220. DOI=http://dx.doi.org/10.14778/2735508.2735511 Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike Zwilling. 2011. High-performance concurrency control mechanisms for main-memory databases. Proc. VLDB Endow. 5, 4 (December 2011), 298-309. DOI=http://dx.doi.org/10.14778/2095686.2095689
28.
28Copyright©2017 NTT corp.
All Rights Reserved. Transaction Choppingと静的解析により、”Early Write Visibility”を実現する手 法. 連鎖的アボートのリスクなしに回復可能スケジュールを部分的に適用できている. Piece-Wise Visibility [Faleiro et al, VLDB 2017] PWV: 提案手法 RC: (Silo-OCC - Read validation). Read commited相当 Locking: 2PL(MCS-Lock) OCC: Siloベースの実装 Low-Contention(上図)では、CPUコア数に対して最も 性能が出ているのはSiloだが、同様にスケールしている. High-Contention(中図)では、Silo-OCCが殆ど通らない ため性能が落ち込む. 提案手法は変わらずスケールする. Varying Contention(下図)ではContention Rateを変化 させたときの性能の落ち込み方を計測している. Contentionが高くなっても、提案手法は高速.
29.
29Copyright©2017 NTT corp.
All Rights Reserved. 回復可能スケジュールを部分的に適用するに あたり、各トランザクションのstatements は全て宣言済み(静的解析可能)であり、決定 的動作をするものと限定される. (全てのabortが明示的に宣言されている) これを静的解析することにより、各 statementの依存関係グラフを描く. このとき,他のstatementに依存されていな いstatementのwriteは、早期にvisibleに出 来るはず, というアプローチ. (abortするstatementの後なら、例えば’S’のインクリメン トは早期にvisibleにしても連鎖アボートせずリカバリ可能.) このとき、トランザクションのPieceが以下 の条件に反しない限り、早期にVisibleにして も並列実行してもSerializableである: 1. Abortしうるpieceは全てVisible pointに先行する. 2. AbortしうるPieceとW-R,W-Wの依存があるpieceは、 その実行を待つ. 3. AbortしないPieceは、Visible point以後に実行できる. 4. R-Wの依存は、常に待つ. Jose M. Faleiro, Daniel J. Abadi, and Joseph M. Hellerstein. 2017. High performance transactions via early write visibility. Proc. VLDB Endow. 10, 5 (January 2017), 613-624. DOI: https://doi.org/10.14778/3055540.3055553 Piece-Wise Visibility [Faleiro et al, VLDB 2017]
30.
30Copyright©2017 NTT corp.
All Rights Reserved. • 並行実行制御に関して、性能向上手法について紹介した. • エンジニアリング的手法 • Group Commit • Early Lock Release • Flush Pipelining • 理論的手法 • Early Write Visibilityの概説 • Speculative Read • Piece-wise Visibility • 発表の便宜上、区分をしたが、両者に差分がないこともある. • Group Commit & Early Lock Releaseはどちらとも言える. • 釈迦に説法だったかもしれませんが、以後お見知りおきを. まとめ
31.
31Copyright©2017 NTT corp.
All Rights Reserved. • Early Lock Release, Flush Pipelining: • Aether: A Scalable Approarch to Logging [Johnson, et al. VLDB 2010] • Hekaton MVCC: • High Performance Concurrency Control Mechanisms for Main-Memory Databases [Larson et al. VLDB 2011] • Piece-wise Visibility(Early Write Visibility): • High Performance transactions via early write visibility [Faleiro et al. VLDB 2017] References
32.
32Copyright©2017 NTT corp.
All Rights Reserved. Aetherのアプローチはロガースレッドが単一のキューとして動くことが前提. これに対して、ロガースレッドを複数持つDistributed Loggingという手法があ る. ログバッファの競合がボトルネックになることを想定している. が,Aetherでは, Distributed Loggingは性能が出ないと主張している. 補足: Aether vs Distributed Logging(1) Distributed Loggingの依存関係のサンプリ ング. 8のロガースレッド(横線)を用意し並列 書き込みを行っている. 縦の線は物理論理ログの依存関係. 暗い線はR-Wの依存関係. あるログが他のロガースレッドのログに依存 する場合、適切な順番で永続化しなければな らない. この待ちが頻繁に発生する. Workloadから分割して、H-Storeのように Partitioned Transactionを行うほうが、ロガ ーのみを分散させるよりも現実的.
33.
33Copyright©2017 NTT corp.
All Rights Reserved. Aetherは”Slow I/O & Heavy Dependency Tracking”をもってDistributed Loggingを諦めていた. これに対して、VLDB ’14では、NVRAMをLog Bufferに用い、Epoch based Group Commitを用いることでDistributed Loggingを実現するアプローチが提案 されている[1]. ベンチマークではAetherを大幅に上回っている. 補足: Aether vs Distributed Logging(2) Write-intensive Workloadでの比較. 横軸: スレッド数(物理24コア) 縦軸: スループット メインメモリ上にキューを用意するAetherと異 なり、ログバッファとしてNVRAMを用いる. また、SiloのようなGroup Commitを行うこと によって、”同一epochの全Txが永続化されたら Commitを返却”とする. 依存関係解決に使うCPUリソースを削減できる. Tianzheng Wang and Ryan Johnson. 2014. Scalable logging through emerging non-volatile memory. Proc. VLDB Endow. 7, 10 (June 2014), 865-876. DOI=http://dx.doi.org/10.14778/2732951.2732960
Download




![10Copyright©2017 NTT corp. All Rights Reserved.
A: I/O Related Delays
レコードを書き終わるまでのI/O wait.
B: Log-induced lock contention
Aに起因するロック保持時間の増加.
それに伴うロックの競合.
C: Excessive context switching
Aを待つ間、スピンする訳にもいかないので、
waitする必要がある. このスケジューラ負荷.
D: Log buffer contention
例えば、WALログとレコードの書き込みを単一
のmutexで管理している場合、WALもwaitする
ことになる. このログバッファで競合が起きる.
Aether [Johnson et al, VLDB 2010]
Ryan Johnson, Ippokratis Pandis, Radu Stoica, Manos Athanassoulis, and Anastasia Ailamaki. 2010. Aether: a
scalable approach to logging. Proc. VLDB Endow. 3, 1-2 (September 2010), 681-692.
DOI=http://dx.doi.org/10.14778/1920841.1920928
Aetherでは、従来のトランザクションのセマンティクスを、2PLやOCCのセマンテ
ィクスに違反しないままうまく変更し、実装上のボトルネックを解決している.
具体的には、以下のボトルネックを問題として挙げている.](https://image.slidesharecdn.com/random-170329045927/85/slide-10-320.jpg)

![17Copyright©2017 NTT corp. All Rights Reserved.
スケジュール空間と性能差の例
T1: Read(x) Write(y) T2: Read(x) Read(z)Read(y)
Read(x) Write(y)History: Read(y) Read(z)Read(x)
Read(x1) Write(x2)History: Read(y1) Read(z1)Read(x1)
[1] H. T. Kung and John T. Robinson. 1981. On optimistic methods for concurrency control. ACM
Trans. Database Syst. 6, 2 (June 1981)](https://image.slidesharecdn.com/random-170329045927/85/slide-17-320.jpg)
![21Copyright©2017 NTT corp. All Rights Reserved.
回復可能
T1: Write(x) T2: Read(x) Write(y)
AbortHistory: Read(x1) Write(y2)Write(x1)
[2] G. Weikum and G. Vossen. Transactional information systems: theory, algorithms, and the practice of concurrency control and recovery. Morgan Kaufmann
Publishers Inc.,San Francisco, CA, USA, 2001. ISBN 1-55860-508-8.
[3] 北川博之, データベースシステム, オーム社, 2014, ISBN 4274216055](https://image.slidesharecdn.com/random-170329045927/85/slide-21-320.jpg)
![22Copyright©2017 NTT corp. All Rights Reserved.
連鎖的アボートの回避
T1: Write(x) T2: Read(x) Write(y)
AbortHistory: Read(x1) Write(y2)Write(x1)
[2] G. Weikum and G. Vossen. Transactional information systems: theory, algorithms, and the practice of concurrency control and recovery. Morgan Kaufmann
Publishers Inc.,San Francisco, CA, USA, 2001. ISBN 1-55860-508-8.
[3] 北川博之, データベースシステム, オーム社, 2014, ISBN 4274216055
AbortHistory: Read(x1) Write(y2)Write(x1) Read(x1) Read(x1) ......Read(x1)](https://image.slidesharecdn.com/random-170329045927/85/slide-22-320.jpg)
![24Copyright©2017 NTT corp. All Rights Reserved.
回復可能スケジュールの適用
「連鎖的アボートの回避」を実装すると、全てのロックを同じタイミング(コミット
時)まで手放すことができない.
これを改善し、かつ「連鎖的アボート」の性能ペナルティは最小限にしたい.
そこで”部分的に” 回復可能スケジュールを適用することで性能を向上させる、以下
の手法が提案されている.
• Group Commit [Gawlick et al. DE Bull 1985]
• Early Lock Release [Johnson et al. VLDB 2010]
• Speculative Read/Speculative Ignore [Larson et al. VLDB 2011]
• Piece-Wise Visibility(PWV)[Faleiro et al. VLDB 2017]
前述したGroup Commit/ELRも「回復可能と連鎖的アボートの回避」の観点で説
明できる. というのが面白い.](https://image.slidesharecdn.com/random-170329045927/85/slide-24-320.jpg)

![27Copyright©2017 NTT corp. All Rights Reserved.
HekatonのSpeculative Read(2)
[1] Xiangyao Yu, George Bezerra, Andrew Pavlo, Srinivas Devadas, and Michael Stonebraker. 2014. Staring into the abyss:
an evaluation of concurrency control with one thousand cores. Proc. VLDB Endow. 8, 3 (November 2014), 209-220.
DOI=http://dx.doi.org/10.14778/2735508.2735511
Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel, and Mike
Zwilling. 2011. High-performance concurrency control mechanisms for main-memory databases.
Proc. VLDB Endow. 5, 4 (December 2011), 298-309.
DOI=http://dx.doi.org/10.14778/2095686.2095689](https://image.slidesharecdn.com/random-170329045927/85/slide-27-320.jpg)
![28Copyright©2017 NTT corp. All Rights Reserved.
Transaction Choppingと静的解析により、”Early Write Visibility”を実現する手
法. 連鎖的アボートのリスクなしに回復可能スケジュールを部分的に適用できている.
Piece-Wise Visibility [Faleiro et al, VLDB 2017]
PWV: 提案手法
RC: (Silo-OCC - Read validation). Read commited相当
Locking: 2PL(MCS-Lock)
OCC: Siloベースの実装
Low-Contention(上図)では、CPUコア数に対して最も
性能が出ているのはSiloだが、同様にスケールしている.
High-Contention(中図)では、Silo-OCCが殆ど通らない
ため性能が落ち込む. 提案手法は変わらずスケールする.
Varying Contention(下図)ではContention Rateを変化
させたときの性能の落ち込み方を計測している.
Contentionが高くなっても、提案手法は高速.](https://image.slidesharecdn.com/random-170329045927/85/slide-28-320.jpg)
![29Copyright©2017 NTT corp. All Rights Reserved.
回復可能スケジュールを部分的に適用するに
あたり、各トランザクションのstatements
は全て宣言済み(静的解析可能)であり、決定
的動作をするものと限定される.
(全てのabortが明示的に宣言されている)
これを静的解析することにより、各
statementの依存関係グラフを描く.
このとき,他のstatementに依存されていな
いstatementのwriteは、早期にvisibleに出
来るはず, というアプローチ.
(abortするstatementの後なら、例えば’S’のインクリメン
トは早期にvisibleにしても連鎖アボートせずリカバリ可能.)
このとき、トランザクションのPieceが以下
の条件に反しない限り、早期にVisibleにして
も並列実行してもSerializableである:
1. Abortしうるpieceは全てVisible pointに先行する.
2. AbortしうるPieceとW-R,W-Wの依存があるpieceは、
その実行を待つ.
3. AbortしないPieceは、Visible point以後に実行できる.
4. R-Wの依存は、常に待つ.
Jose M. Faleiro, Daniel J. Abadi, and Joseph M. Hellerstein. 2017. High performance
transactions via early write visibility. Proc. VLDB Endow. 10, 5 (January 2017), 613-624. DOI:
https://doi.org/10.14778/3055540.3055553
Piece-Wise Visibility [Faleiro et al, VLDB 2017]](https://image.slidesharecdn.com/random-170329045927/85/slide-29-320.jpg)

![31Copyright©2017 NTT corp. All Rights Reserved.
• Early Lock Release, Flush Pipelining:
• Aether: A Scalable Approarch to Logging [Johnson, et
al. VLDB 2010]
• Hekaton MVCC:
• High Performance Concurrency Control Mechanisms for
Main-Memory Databases [Larson et al. VLDB 2011]
• Piece-wise Visibility(Early Write Visibility):
• High Performance transactions via early write visibility
[Faleiro et al. VLDB 2017]
References](https://image.slidesharecdn.com/random-170329045927/85/slide-31-320.jpg)

![33Copyright©2017 NTT corp. All Rights Reserved.
Aetherは”Slow I/O & Heavy Dependency Tracking”をもってDistributed
Loggingを諦めていた.
これに対して、VLDB ’14では、NVRAMをLog Bufferに用い、Epoch based
Group Commitを用いることでDistributed Loggingを実現するアプローチが提案
されている[1].
ベンチマークではAetherを大幅に上回っている.
補足: Aether vs Distributed Logging(2)
Write-intensive Workloadでの比較.
横軸: スレッド数(物理24コア)
縦軸: スループット
メインメモリ上にキューを用意するAetherと異
なり、ログバッファとしてNVRAMを用いる.
また、SiloのようなGroup Commitを行うこと
によって、”同一epochの全Txが永続化されたら
Commitを返却”とする.
依存関係解決に使うCPUリソースを削減できる.
Tianzheng Wang and Ryan Johnson. 2014. Scalable logging through emerging non-volatile
memory. Proc. VLDB Endow. 7, 10 (June 2014), 865-876.
DOI=http://dx.doi.org/10.14778/2732951.2732960](https://image.slidesharecdn.com/random-170329045927/85/slide-33-320.jpg)

























































![[Basic 9] 並列処理 / 排他制御](https://cdn.slidesharecdn.com/ss_thumbnails/basic-091-180306131603-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[xSIG 2018]InvisibleWriteRule: Extended write protocol for 1VCC](https://cdn.slidesharecdn.com/ss_thumbnails/xsig2018-180528073507-thumbnail.jpg?width=640&height=640&fit=bounds)