Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masahiko Hashimoto
PDF, PPTX
8,710 views
ホットな日本語入力技術のお勉強。〜 OSC 2016 Hamanako 編 〜
「ホットな日本語入力技術のお勉強。」OSC浜名湖2016編です。 N-gramのことについて新規に説明を追加してます。
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 28
2
/ 28
Most read
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
Most read
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
Most read
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
京都発祥日本語入力「FreeWnn」は(今度こそ)どこまで賢くなれるか?
by
Masahiko Hashimoto
PDF
おーぷん万葉プロジェクトの進捗とIzumoのその後
by
Masahiko Hashimoto
PDF
おーぷん万葉プロジェクトとは
by
Masahiko Hashimoto
PDF
ホットな日本語技術の(ちょっとした)お勉強。
by
Masahiko Hashimoto
PDF
かな漢字変換ソフト「Genji」をつくってみた
by
Masahiko Hashimoto
PDF
Nginxで日本語入力を遊んでみよう!
by
Masahiko Hashimoto
PDF
DeepLearning入門以前
by
Masahiko Hashimoto
PDF
TrieとLOUDS??
by
Masahiko Hashimoto
京都発祥日本語入力「FreeWnn」は(今度こそ)どこまで賢くなれるか?
by
Masahiko Hashimoto
おーぷん万葉プロジェクトの進捗とIzumoのその後
by
Masahiko Hashimoto
おーぷん万葉プロジェクトとは
by
Masahiko Hashimoto
ホットな日本語技術の(ちょっとした)お勉強。
by
Masahiko Hashimoto
かな漢字変換ソフト「Genji」をつくってみた
by
Masahiko Hashimoto
Nginxで日本語入力を遊んでみよう!
by
Masahiko Hashimoto
DeepLearning入門以前
by
Masahiko Hashimoto
TrieとLOUDS??
by
Masahiko Hashimoto
What's hot
PDF
アヒルヤキを変換してみよう
by
Masahiko Hashimoto
PDF
自作かな漢字変換「Genji」をつくったよ
by
Masahiko Hashimoto
PDF
C言語なWebSocketの遊び方。
by
Masahiko Hashimoto
PDF
TeXで多言語文書作成! (2011年ごろの資料)
by
Bizan Nishimura
PDF
BrowserMob-Proxyのお話
by
Masahiko Hashimoto
PDF
底から見上げるデブ(Dev) 〜俺と執事と自動化と〜
by
Kazuhito Miura
PDF
PHP Matsuri2013でなにをしたか?
by
Shintaro Okamatsu
PDF
Applicationとは何か(哲学)(PHPBLT #6)
by
sitri kamishirasawa
PPTX
もっとドキュメントが日本語になりますように
by
Takako Miyagawa
PDF
Tensorflow
by
Daisuke Yamashita
PPTX
雑兵だけどGolangでコマンドラインツールを作ってみた
by
Shota Inoue
PDF
あひるに焼かれた話と今後のおーぷん万葉について
by
Masahiko Hashimoto
ODP
「かいろ」せいちょうものがたり
by
どと〜る
PPTX
子供と使う便利ツール
by
Takashi Toyoshima
PDF
Sphinxで翻訳してたら本が出てた話
by
Yoshifumi Yamaguchi
PDF
Mitakalab in Hongo
by
Ryo Suzuki
PPT
個人のタスク管理方法について考える
by
nekotank
PDF
「アウェイ」でTOCfEを広めるための「追体験アプローチ」の発表資料(導入部)LT
by
Takahiro Nohdomi
PPTX
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
PPTX
僕がLasta flute選んだ理由
by
Yuichiro Kawano
アヒルヤキを変換してみよう
by
Masahiko Hashimoto
自作かな漢字変換「Genji」をつくったよ
by
Masahiko Hashimoto
C言語なWebSocketの遊び方。
by
Masahiko Hashimoto
TeXで多言語文書作成! (2011年ごろの資料)
by
Bizan Nishimura
BrowserMob-Proxyのお話
by
Masahiko Hashimoto
底から見上げるデブ(Dev) 〜俺と執事と自動化と〜
by
Kazuhito Miura
PHP Matsuri2013でなにをしたか?
by
Shintaro Okamatsu
Applicationとは何か(哲学)(PHPBLT #6)
by
sitri kamishirasawa
もっとドキュメントが日本語になりますように
by
Takako Miyagawa
Tensorflow
by
Daisuke Yamashita
雑兵だけどGolangでコマンドラインツールを作ってみた
by
Shota Inoue
あひるに焼かれた話と今後のおーぷん万葉について
by
Masahiko Hashimoto
「かいろ」せいちょうものがたり
by
どと〜る
子供と使う便利ツール
by
Takashi Toyoshima
Sphinxで翻訳してたら本が出てた話
by
Yoshifumi Yamaguchi
Mitakalab in Hongo
by
Ryo Suzuki
個人のタスク管理方法について考える
by
nekotank
「アウェイ」でTOCfEを広めるための「追体験アプローチ」の発表資料(導入部)LT
by
Takahiro Nohdomi
We are OSS Communities: Introduction of Start Python Club
by
Takeshi Akutsu
僕がLasta flute選んだ理由
by
Yuichiro Kawano
More from Masahiko Hashimoto
PDF
OSSかな漢字変換『Egoistic Lily』の紹介&今後の展望
by
Masahiko Hashimoto
PDF
DNNを使用した新しいかな漢字変換『EgoisticLily』 その仕組みとは?
by
Masahiko Hashimoto
PDF
Dockerいろいろ使って思うこと
by
Masahiko Hashimoto
PDF
C++アプリをCmakeとEclipseで開発するお話
by
Masahiko Hashimoto
PDF
続・Cannaをフォークしてみた
by
Masahiko Hashimoto
PDF
Cannaをフォークしてみた
by
Masahiko Hashimoto
PDF
秘伝:クラウドに開発環境をえいっ!と構築する方法
by
Masahiko Hashimoto
PDF
AzureとSUSE Studioのあつ~い関係
by
Masahiko Hashimoto
PDF
X window managerで遊んでみた
by
Masahiko Hashimoto
PDF
オープンソースで始める「超」VPN 構築術
by
Masahiko Hashimoto
PDF
自分色のLinuxホームサーバーを作ってみよう
by
Masahiko Hashimoto
OSSかな漢字変換『Egoistic Lily』の紹介&今後の展望
by
Masahiko Hashimoto
DNNを使用した新しいかな漢字変換『EgoisticLily』 その仕組みとは?
by
Masahiko Hashimoto
Dockerいろいろ使って思うこと
by
Masahiko Hashimoto
C++アプリをCmakeとEclipseで開発するお話
by
Masahiko Hashimoto
続・Cannaをフォークしてみた
by
Masahiko Hashimoto
Cannaをフォークしてみた
by
Masahiko Hashimoto
秘伝:クラウドに開発環境をえいっ!と構築する方法
by
Masahiko Hashimoto
AzureとSUSE Studioのあつ~い関係
by
Masahiko Hashimoto
X window managerで遊んでみた
by
Masahiko Hashimoto
オープンソースで始める「超」VPN 構築術
by
Masahiko Hashimoto
自分色のLinuxホームサーバーを作ってみよう
by
Masahiko Hashimoto
ホットな日本語入力技術のお勉強。〜 OSC 2016 Hamanako 編 〜
1.
ホットな日本語入力技術のお勉強。 〜 OSC 2016
Hamanako 編 〜 2016/1/23 OSC 2016 Hamanako はしもとまさひこ
2.
簡単に自己紹介。 ● 東海道らぐ(Tokaido Linux
User Group)案内人 – 東京〜静岡〜名古屋〜京都〜大阪で活動するらぐ – 明日、鴨江アートセンターでオフ会やります!!! 詳しくは東海道らぐブースのビラを参照(余ってるはず) ● ちびぎーこ保護者会(別名日本openSUSEユーザ会)の人 ● 最近は日本語入力についていろいろ勉強している人
3.
まず、質問です(^^) これからいくつか質問をします。 ご協力をお願いします!
4.
Q1.日本語入力ソフトを意識して使っていますか? 1. 自分はこれしか使わない!というソフトがある (※MS-IME, ATOK,
Google日本語入力等) 2. ソフトは知らないけど優れたソフトを使いたい! 3. 特に意識したことはない 注: OSとか関係なく回答ください
5.
Q2. OSSなOSをデスクトップで使っていますか? 1. Linux,
BSD等をデスクトップで使ってます! 2. デスクトップはMacしか使わないよ! 3. デスクトップはWindowsに決まってるでしょ! 注: 正直に回答ください(^^)
6.
今日はオープンソースの日本語入力についてです 1. 最近の日本語入力技術とは? 1. 辞書データ構築技術について
〜Trie〜 2. かな漢字変換アルゴリズム① 〜Mozc〜 3. かな漢字変換アルゴリズム② 〜libkkc〜 2. まとめ 1. 最近のオープンソースな日本語入力事情 2. おーぷん万葉の紹介
7.
1-1. 最新の日本語入力技術とは 辞書データ構築編
8.
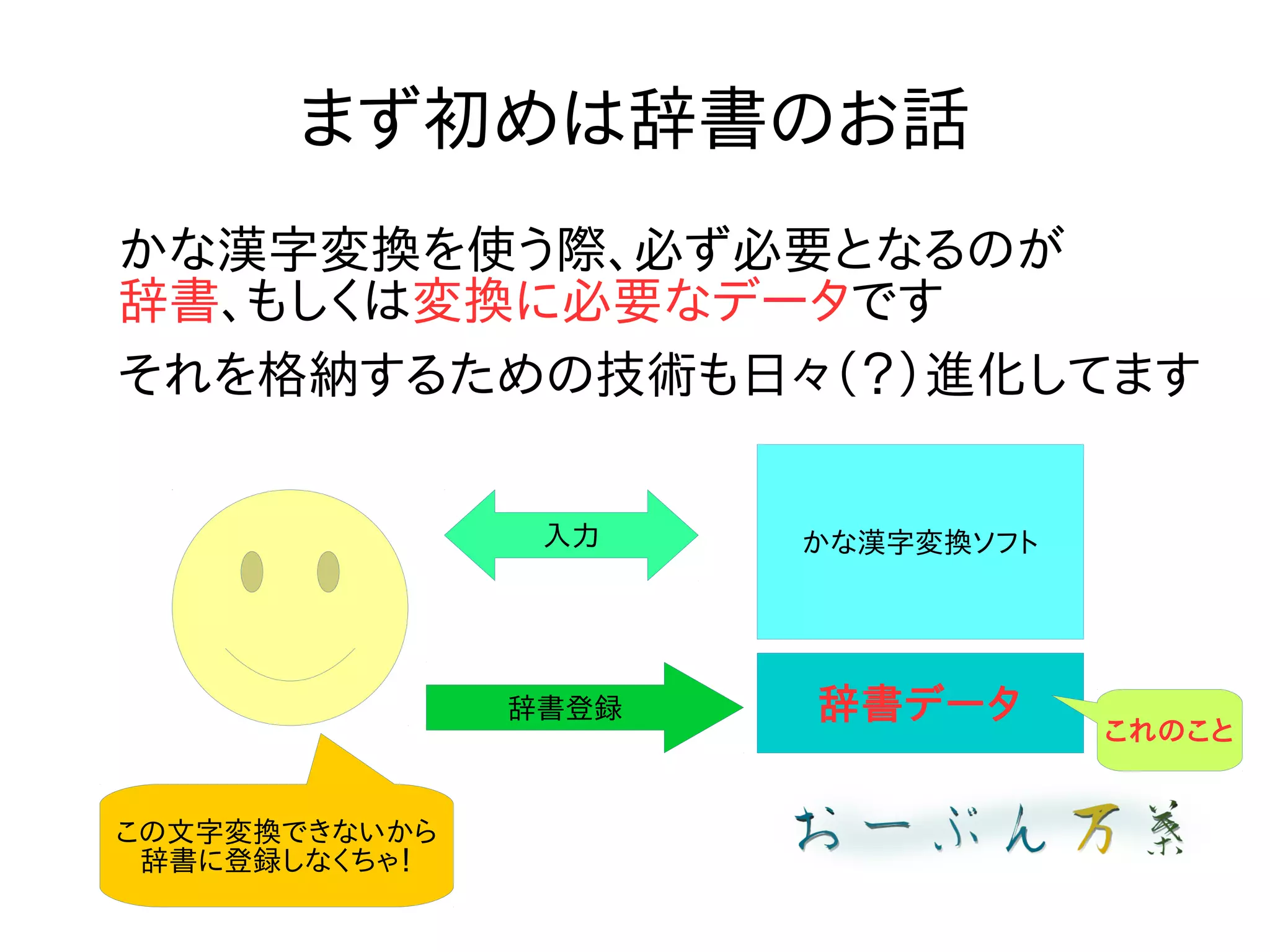
まず初めは辞書のお話 かな漢字変換を使う際、必ず必要となるのが 辞書、もしくは変換に必要なデータです それを格納するための技術も日々(?)進化してます かな漢字変換ソフト 辞書データ 入力 辞書登録 この文字変換できないから 辞書に登録しなくちゃ! これのこと
9.
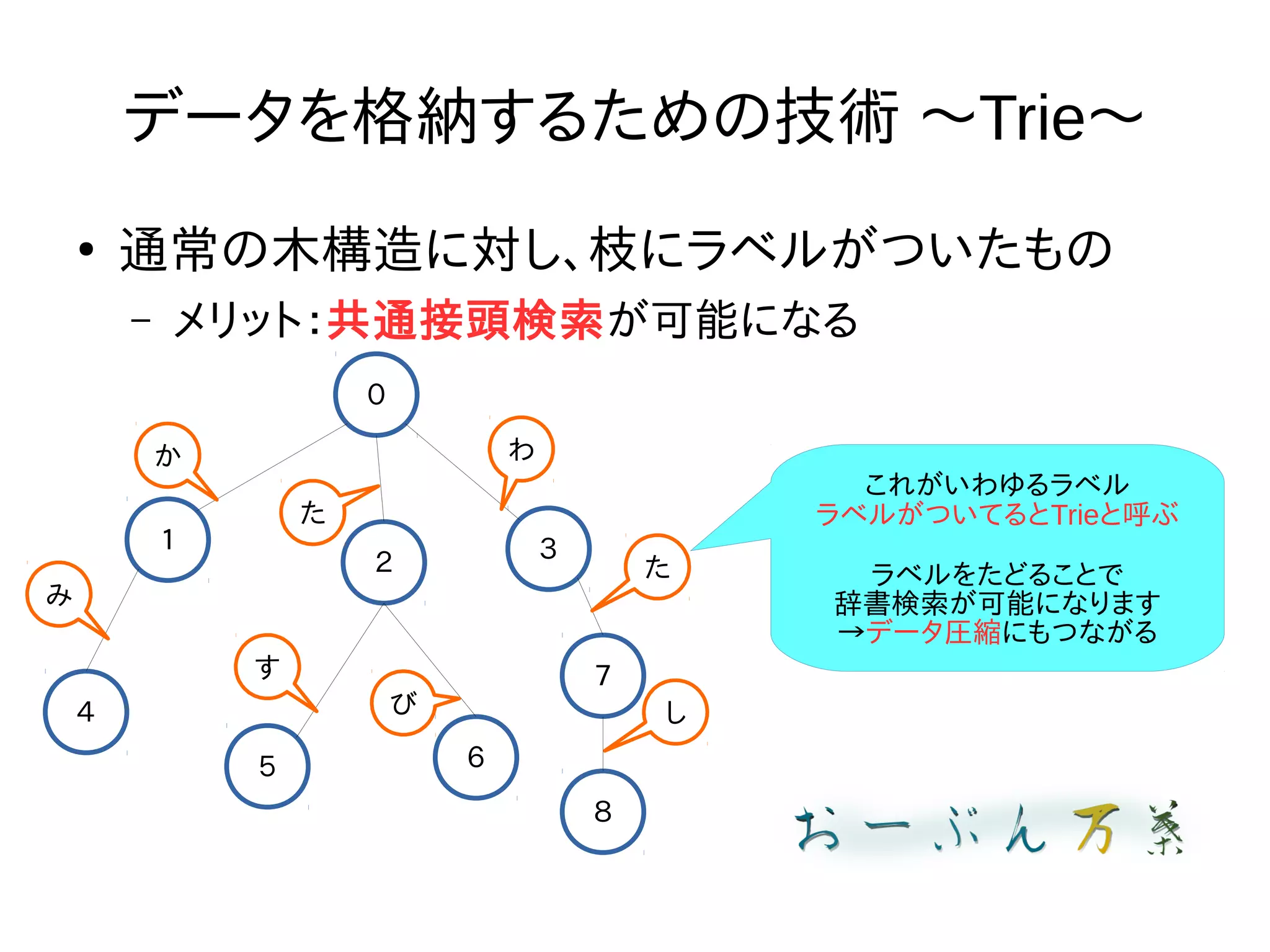
データを格納するための技術 〜Trie〜 ● 通常の木構造に対し、枝にラベルがついたもの – メリット:共通接頭検索が可能になる 0 1 2
3 4 5 6 7 8 か み た す び わ た し これがいわゆるラベル ラベルがついてるとTrieと呼ぶ ラベルをたどることで 辞書検索が可能になります →データ圧縮にもつながる
10.
Trieの実装 〜LOUDS〜 10 1110
10 110 10 0 0 0 10 0 0 1 2 3 4 5 6 7 8 か み た す び わ た し 仮想ノード 「0」から 3つに分岐 「1」は 分岐なし 「2」から 2つに分岐 「3」は 分岐なし 「4」「5」「6」は 末端ノード 「7」は 分岐なし 「8」は 末端ノード Trieをビットで表現したもの それが「LOUDS」(らうず) 課題として下記のようなものがあります ・ノードを動的に追加することが困難 ・Trie構築後にビットを作成しないと厳しい?
11.
現在の主流はTrie ● その他のTrieの実装としてダブル配列等があります – LOUDSより高速ですが、メモリ消費が大きいので かな漢字変換には不向きと言われてます –
形態素解析器mecabはダブル配列を採用してます ● オープンソースのライブラリが数多く存在します – 自分で実装すると大変! まずはオープンソースで試してみましょう ● Tx / Ux : 非常にコンパクトなLOUDSのライブラリ ● Rx: mozcで採用されているLOUDSのライブラリ ● marisa-trie: libkkcで採用されているLOUDSのライブラリ
12.
1-2. 最新の日本語入力技術とは かな漢字変換アルゴリズム編
13.
注: 繰り返しますが… 本日お話する内容は全て オープンソースの実装ついて です ※AT○KとかMicr○s○ftの技術については知りません!(笑)
14.
オープンソースなかな漢字変換の歴史 ● 1987年 :
Wnn (FreeWnnの前身) ● 1989年 : Canna ● 2002年 : Anthy ● 2010年 : mozc ● 2013年 : libkkc (Fedora19よりデフォルトIMEへ) 簡単な年表ですが…^^;
15.
従来の変換アルゴリズム例: N文節最長一致法 ● 例文: 「きょうはあひるやきです」 今日 歯
あ 昼 焼きで 酢 今日は あ 昼 焼きです 今日は 家鴨 焼きです 今日は あひる焼きです 6文節 4文節 3文節 2文節 一番少ないのでこれを選択! ポイント: 文節 = 自立語(名詞・動詞等) + 付属語(助詞等) Canna等で採用
16.
かな漢字変換アルゴリズム① 〜Mozc〜 ● Mozc –
Google日本語入力のオープンソース版 – 2010年 Googleによってリリース ● 形態素解析を用いた変換アルゴリズム – コスト最小法。現在の主流になりつつある
17.
コスト最小法 とは 文 頭 私 の 名前 は 中野 注:ちょっと(かなり?)端折って説明します^^; です 文 末ので
す 中 綿 市 花 課 例: 「わたしのなまえはなかのです」を変換する場合 (コストの値はテキトーです^^;) 10 30 15 30 15 10 15 40 20 50 ● 単語生起コスト: 単語の出現優先度を表したコスト ● 連接コスト: 単語と単語の結びつきやすさを表したコスト → 全て足して、合計値が最も低いルートが 候補になります 15 30 40 45 20 20 20 20 50 20 25 30 40 45 20 20 出現頻度の高い単語は 単語生起コストが低い 「名前」と「花」という単語は結びつきにくいので 連接コストは高い
18.
コスト最小法も完璧ではない? Mozcで変換できないものもある… 「にわにはにわにわとりがいる」 → 「庭には庭鶏がいる」になってしまう 庭 庭
鶏には が いる 庭 二 鶏には が いる羽 正解の変換のほうが単語数が多いため 単語生起コストがどうしても高くなる
19.
かな漢字変換アルゴリズム② 〜libkkc〜 ● libkkc –
2013年 Fedora19のデフォルトIMEになる – RedHat社のUeno氏によって開発 ● N-gramによるかな漢字変換 – 形態素解析を行わないアルゴリズム = 辞書データに品詞情報を持たない – ビッグデータ(巨大コーパス)を十分に活かせる可能性 ここが重要!!!
20.
N-gramとは? N文字の共起関係からテキストの特徴を分析する – 2文字: 2-gram (=
bi-gram) – 3文字: 3-gram (= tri-gram) 例文) 私の名前は中野です → 2-gram 「私の」 「の名」 「名前」 「前は」 「は中」 「中野」 「野で」 「です」 この単位で確率を求め 変換用データを作成します
21.
例えばlibkkcの変換用データは… -1.114728 ぬいぐるみ/ぬいぐるみ 」/」
ていど/程度 -0.667107 ぬいぐるみ/ぬいぐるみ 」/」 と/と -0.643911 ぬいぐるみ/ぬいぐるみ うらない/占い を/を -0.740726 ぬいぐるみ/ぬいぐるみ たすう/多数 を/を -0.454970 ぬいぐるみ/ぬいぐるみ だ/だ が/が -0.814252 ぬいぐるみ/ぬいぐるみ で/で わりお/ワリオ -1.110465 ぬいぐるみ/ぬいぐるみ は/は かのじょ/彼女 -0.802579 ぬいぐるみ/ぬいぐるみ やら/やら しゃしん/写真 -1.626115 ぬいぐるみ/ぬいぐるみ を/を 「/「 -1.708439 ぬいぐるみ/ぬいぐるみ を/を せいさく/製作 -1.631926 ぬいぐるみ/ぬいぐるみ を/を つく/作 -1.713616 ぬいぐるみ/ぬいぐるみ を/を なげつけ/投げつけ -1.681401 ぬいぐるみ/ぬいぐるみ を/を のこ/残 -1.713256 ぬいぐるみ/ぬいぐるみ を/を もちこ/持ち込 -1.714574 ぬいぐるみ/ぬいぐるみ を/を よご/汚 -1.716680 ぬいぐるみ/ぬいぐるみ を/を りんぐ/リング -0.813648 ぬいぐるみ/ぬいぐるみ (/( じょん/ジョン -0.803737 ぬいぐるみ/ヌイグルミ の/の こと/こと 単語単位ではなく 単語の組み合わせ単位で 変換用データとして 登録されていますね なんだかノイズデータっぽいのもいるのですが…
22.
結構さくさく変換できる…が!? ● 苦手な変換ももちろんある – 「ぬいぐるみをぬう」 →「ぬいぐるみを縫う」(正解) –
「ぬいぐるみ」 →「縫い包み」(そうなるの!?) – 「ぬいぐるみのことをおもう」→「ヌイグルミのことを思う」 ● 形態素解析を行わない → 文節区切りができない → 変換したい箇所にフォーカスを当てるのがやや大変! 「この漢字をどうしましょ」 ←こんな感じでフォーカスが当たってしまうorz 前ページのノイズデータを 思いっきり拾った感じですね…
23.
2.まとめ
24.
現在のLinuxのかな漢字変換 ● およそMozc一色 – Ubuntu,
Debian, openSUSE, VineLinux… – まぁそれでもいいのではないかと言われているが… – 途中いろいろ問題発生しつつ乗り越えてる感ある ● とはいえ、既に一部でサポートフェーズと言われているのも事実 ● Redhat系はlibkkcですね – Fedora, CentOS…
25.
皆さん、本当にそれでいいですか?
26.
おーぷん万葉プロジェクトとは ● 目的「自由な日本語辞書を手に入れよう!」 – 現在: かな漢字変換ソフト「Genji」を開発中。 ● 現状の問題点: –
ビックデータと叫ばれる時代に、開発がアクティブで コミュニティー主体の日本語入力システムがない??? → そんな現状を打破したい!てのが目的です。
27.
日本語をもっと自由に 楽しみましょう!
28.
ご清聴、ありがとうございました。
Download