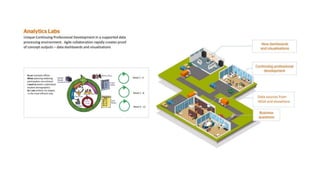
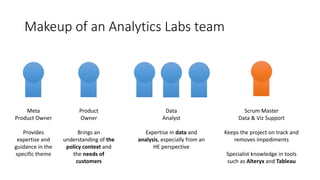
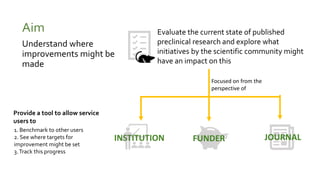
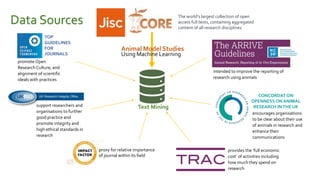
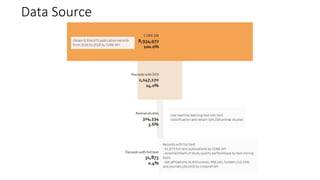
Analytics Labs is a collaborative business intelligence initiative for UK education, which focuses on developing proof-of-concept dashboards using data from various sources, including HESA. The program emphasizes agile development and data visualization training, involving 289 participants from 109 universities to enhance research reproducibility and transparency. It utilizes machine learning and text mining techniques to evaluate preclinical research quality in animal studies, aimed at improving scientific integrity and practices.