Download to read offline


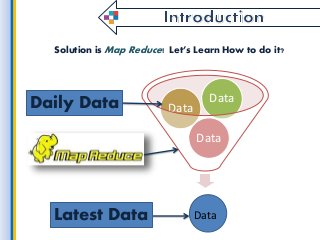
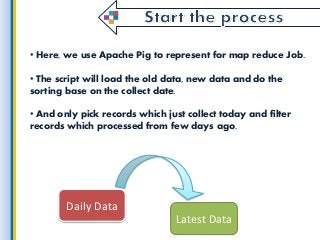

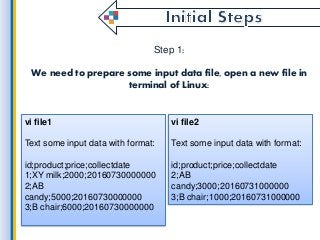
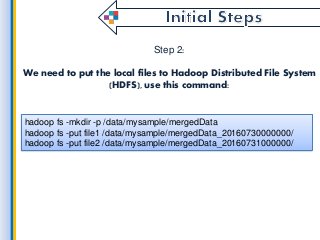
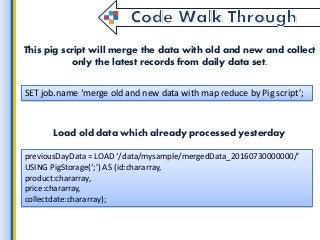


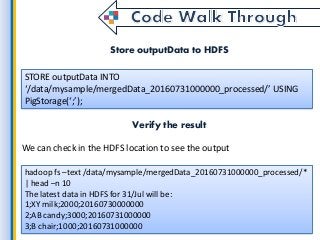



Latest Data is the most powerful thing for starting any kind of work because without it we cant reach the goal. in this fast period of technology, every time market will update with new data. so here we get such useful information on getting latest data from all the collection of information and finding the latest and convenient data for big data application development for use through Map Reduce. what is a process, which environments used by a map reduce and etc

![[IoT Testing]- 4 Challenges We may face in IoT Testing](https://cdn.slidesharecdn.com/ss_thumbnails/iot-testing-190624120848-thumbnail.jpg?width=640&height=640&fit=bounds)













































