Downloaded 12 times







![Backstory: why
#applyconf #MLOps #machinelearning 12
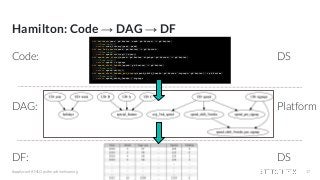
Featurization: some example code
df = load_dates() # load date ranges
df = load_actuals(df) # load actuals, e.g. spend, signups
df['holidays'] = is_holiday(df['year'], df['week']) # holidays
df['avg_3wk_spend'] = df['spend'].rolling(3).mean() # moving average of spend
df['spend_per_signup'] = df['spend'] / df['signups'] # spend per person signed up
df['spend_shift_3weeks'] = df.spend['spend'].shift(3) # shift spend because ...
df['spend_shift_3weeks_per_signup'] = df['spend_shift_3weeks'] / df['signups']
def my_special_feature(df: pd.DataFrame) -> pd.Series:
return (df['A'] - df['B'] + df['C']) * weights
df['special_feature'] = my_special_feature(df)
# ...](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-12-320.jpg?cb=1619037681)
![Backstory: why
#applyconf #MLOps #machinelearning 13
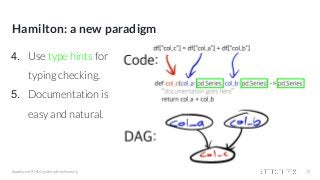
Featurization: some example code
df = load_dates() # load date ranges
df = load_actuals(df) # load actuals, e.g. spend, signups
df['holidays'] = is_holiday(df['year'], df['week']) # holidays
df['avg_3wk_spend'] = df['spend'].rolling(3).mean() # moving average of spend
df['spend_per_signup'] = df['spend'] / df['signups'] # spend per person signed up
df['spend_shift_3weeks'] = df.spend['spend'].shift(3) # shift spend because ...
df['spend_shift_3weeks_per_signup'] = df['spend_shift_3weeks'] / df['signups']
def my_special_feature(df: pd.DataFrame) -> pd.Series:
return (df['A'] - df['B'] + df['C']) * weights
df['special_feature'] = my_special_feature(df)
# ...
Now scale this code to 1000+ columns & a growing team 😬](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-13-320.jpg?cb=1619037681)
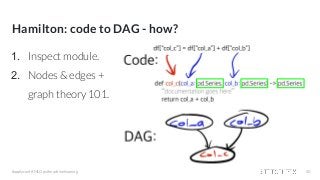
![Backstory: why
○ Unit testing 👎
○ Documentation 👎
○ Onboarding 📈 👎
○ Debugging 📈 👎
#applyconf #MLOps #machinelearning 14
df = load_dates() # load date ranges
df = load_actuals(df) # load actuals, e.g. spend, signups
df['holidays'] = is_holiday(df['year'], df['week']) # holidays
df['avg_3wk_spend'] = df['spend'].rolling(3).mean() # moving average of spend
df['spend_per_signup'] = df['spend'] / df['signups'] # spend per person signed up
df['spend_shift_3weeks'] = df.spend['spend'].shift(3) # shift spend because ...
df['spend_shift_3weeks_per_signup'] = df['spend_shift_3weeks'] / df['signups']
def my_special_feature(df: pd.DataFrame) -> pd.Series:
return (df['A'] - df['B'] + df['C']) * weights
df['special_feature'] = my_special_feature(df)
# ...
Scaling this type of code results in the following:
- lots of heterogeneity in function definitions & behaviors
- inline dataframe manipulations
- code ordering is super important](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-14-320.jpg?cb=1619037681)






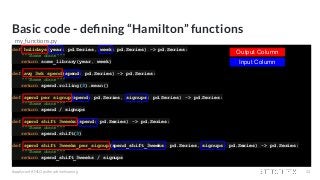
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 25](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-25-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 26](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-26-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 27](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-27-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 28](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-28-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 29](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-29-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 30](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-30-320.jpg?cb=1619037681)
![Driver code - how do you get the Dataframe?
from hamilton import driver
initial_columns = { # load from actuals / initial data
'A': ...,
'B': ...,
'C': 3,
'signups': ...,
'spend': ...,
'week': ...,
'year': ...
}
module_name = 'my_functions' # e.g. my_functions.py
module = importlib.import_module(module_name) # The python file to crawl
dr = driver.Driver(initial_columns, module) # can pass in multiple modules
output_columns = ['year','week',...,'spend_shift_3weeks_per_signup','special_feature']
df = dr.execute(output_columns, display_graph=True) # only walk DAG for what is needed
#applyconf #MLOps #machinelearning 31
Can visualize what we’re executing too!](https://image.slidesharecdn.com/hamiltonamicroframeworkforcreatingdataframes-210421204001/85/Hamilton-a-micro-framework-for-creating-dataframes-31-320.jpg?cb=1619037681)









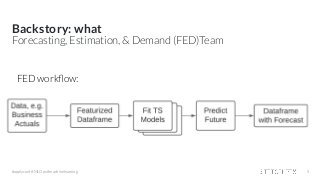
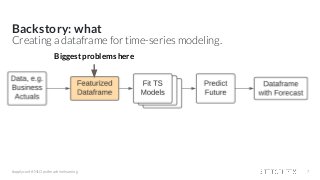
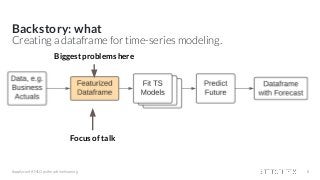
Hamilton: a micro framework for creating dataframes At Stitch Fix we have 145+ “Full Stack Data Scientists” who in addition to doing data science work, are also expected to engineer and own data pipelines for their production models. One data science team, the Forecasting, Estimation, and Demand team was in a bind. Their data generation process was causing them iteration & operational frustrations in delivering time-series forecasts for the business. In this talk I’ll present Hamilton, a novel python micro framework, that solved their pain points by changing their working paradigm. Specifically, Hamilton enables a simpler paradigm for a Data Science team to create, maintain, and execute code for generating wide dataframes, especially when there are lots of intercolumn dependencies. Hamilton does this by building a DAG of dependencies directly from python functions defined in a special manner, which also makes unit testing and documentation easy; tune into the talk to find out how. I’ll also cover our experience migrating to it and using it in production for over a year, along with possible future directions.




![[open source] hamilton, a micro framework for creating dataframes, and its ap...](https://cdn.slidesharecdn.com/ss_thumbnails/publicapplyconf2022-opensourcehamiltonamicroframeworkforcreatingdataframesanditsapplicationatstitchf-220210223224-thumbnail.jpg?width=640&height=640&fit=bounds)










































