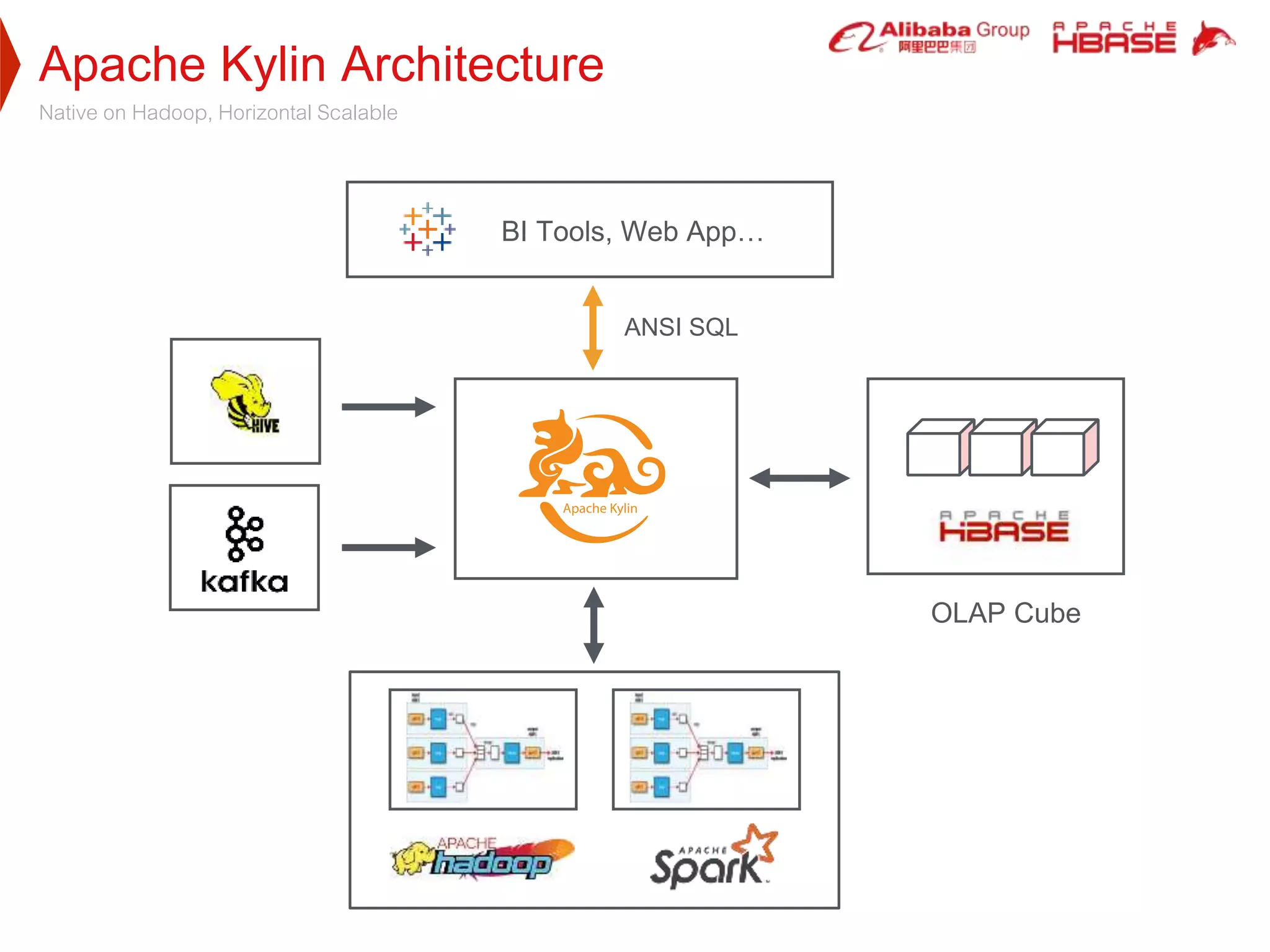
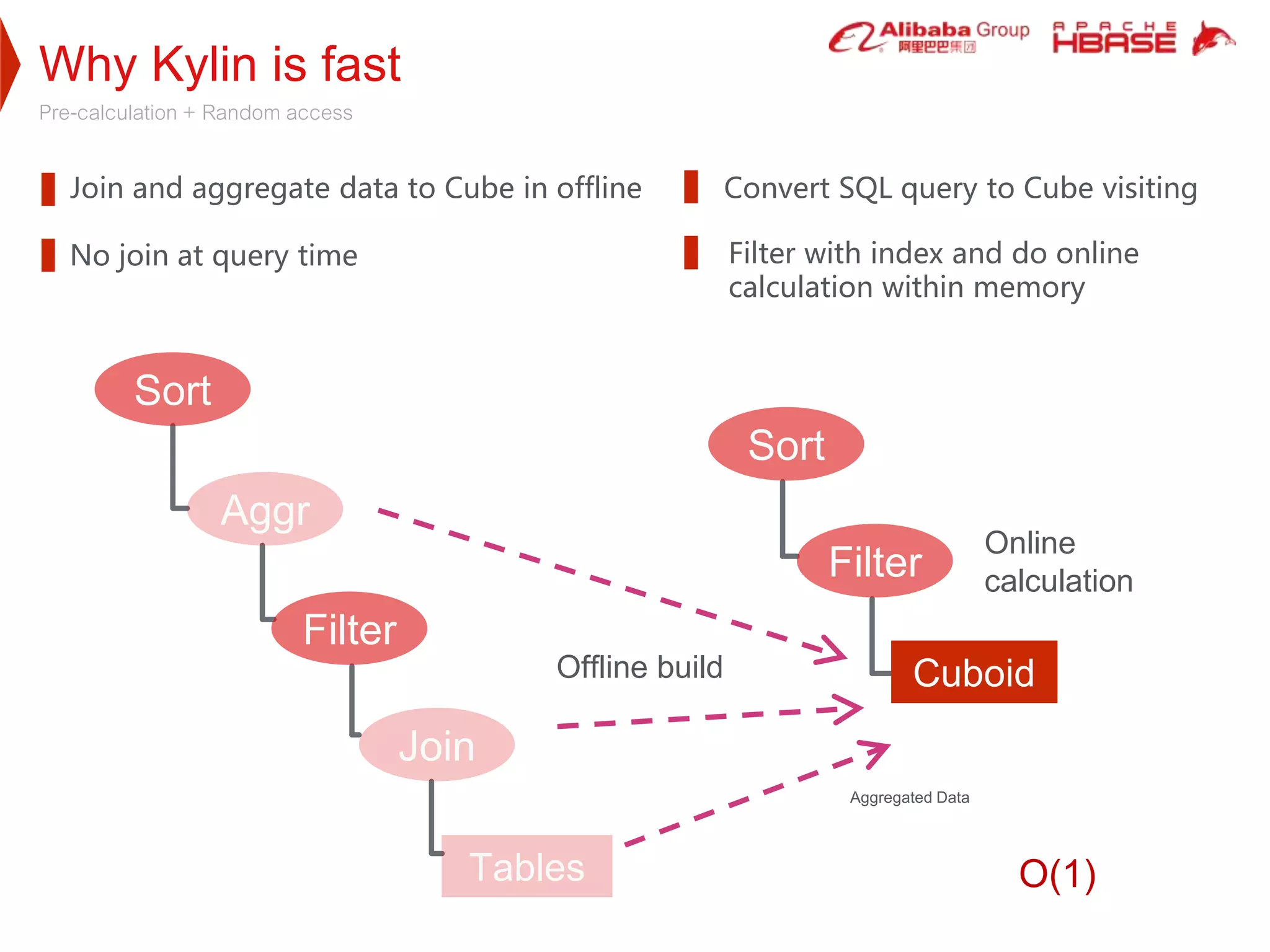
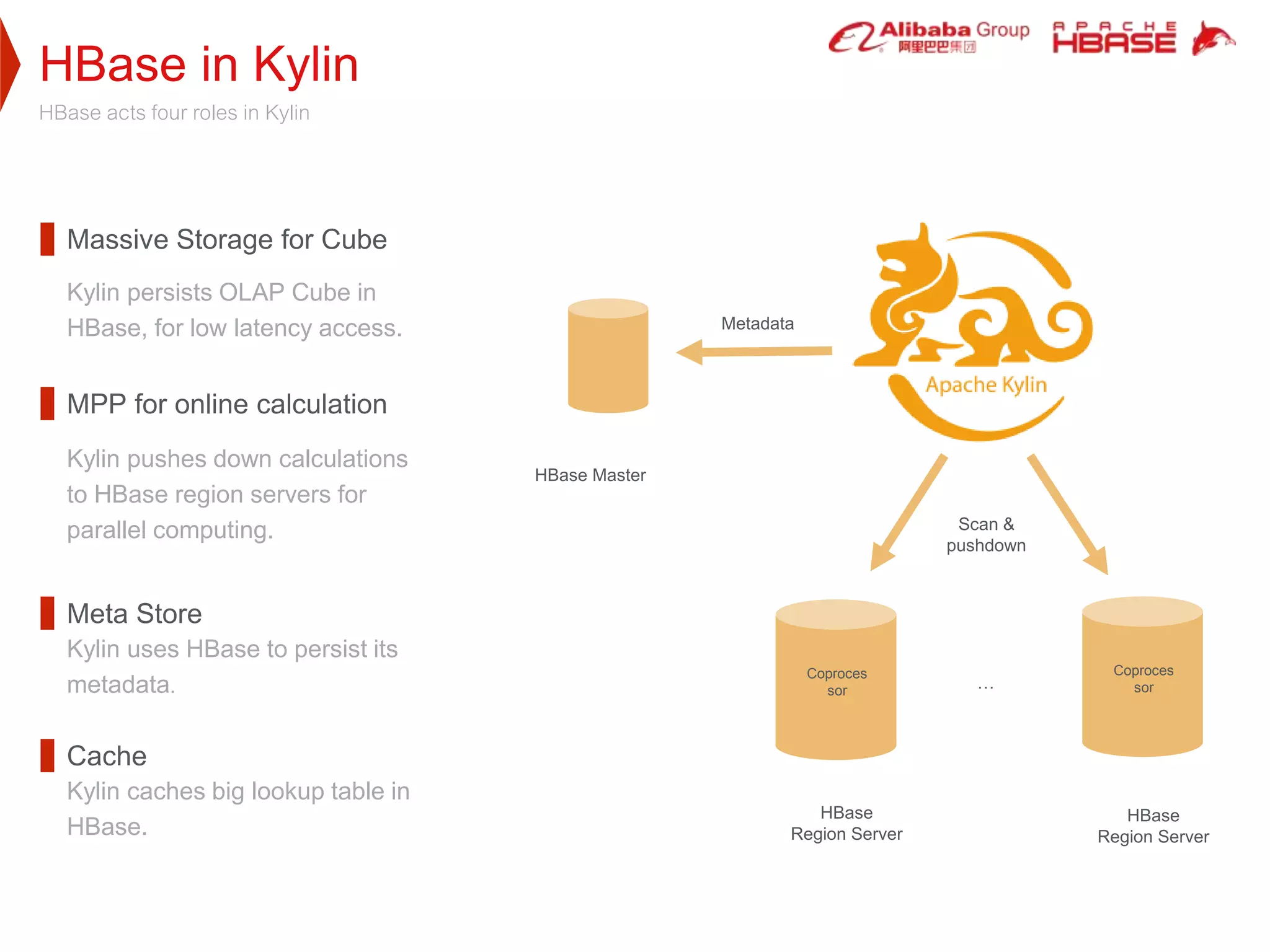
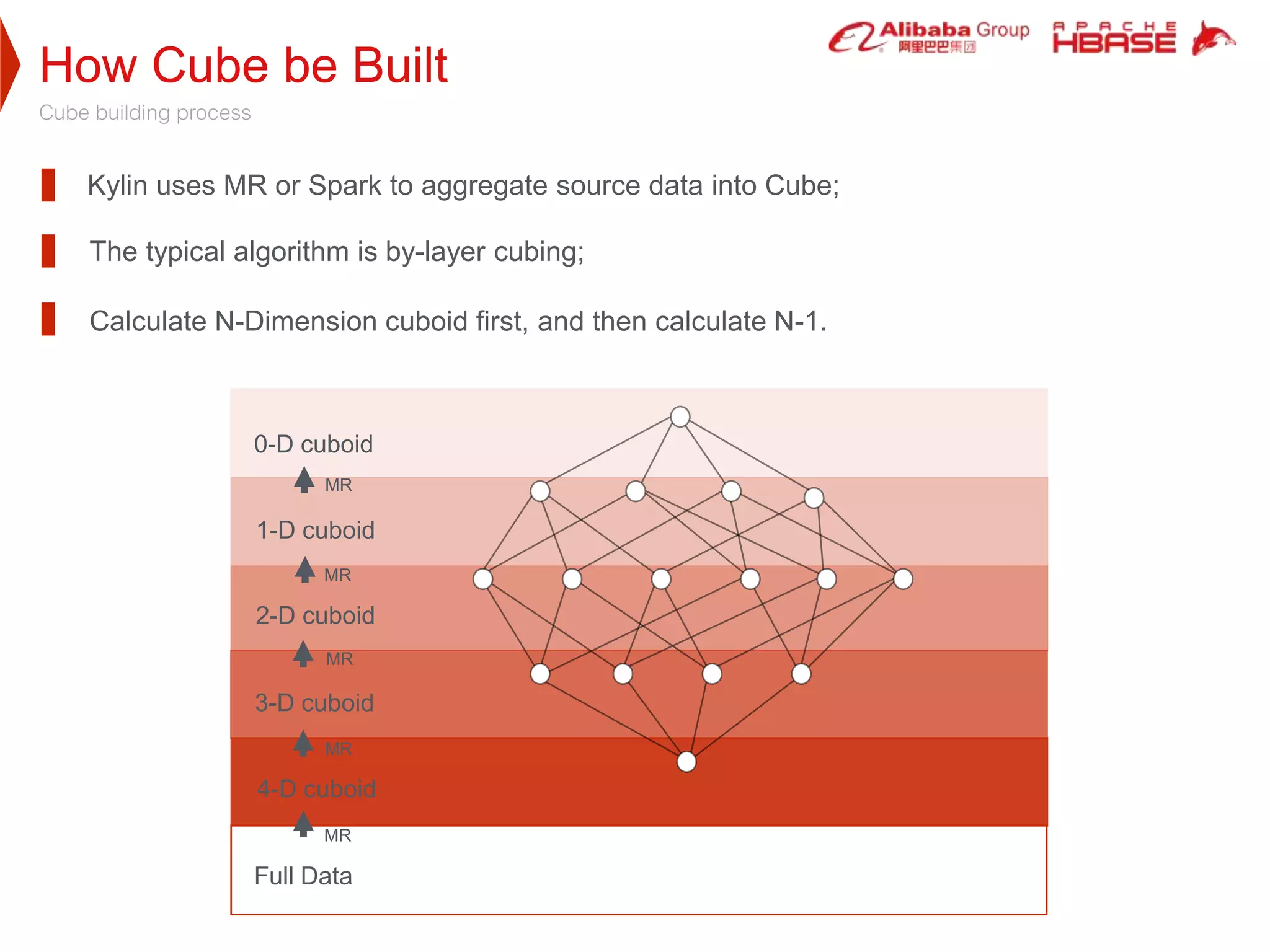
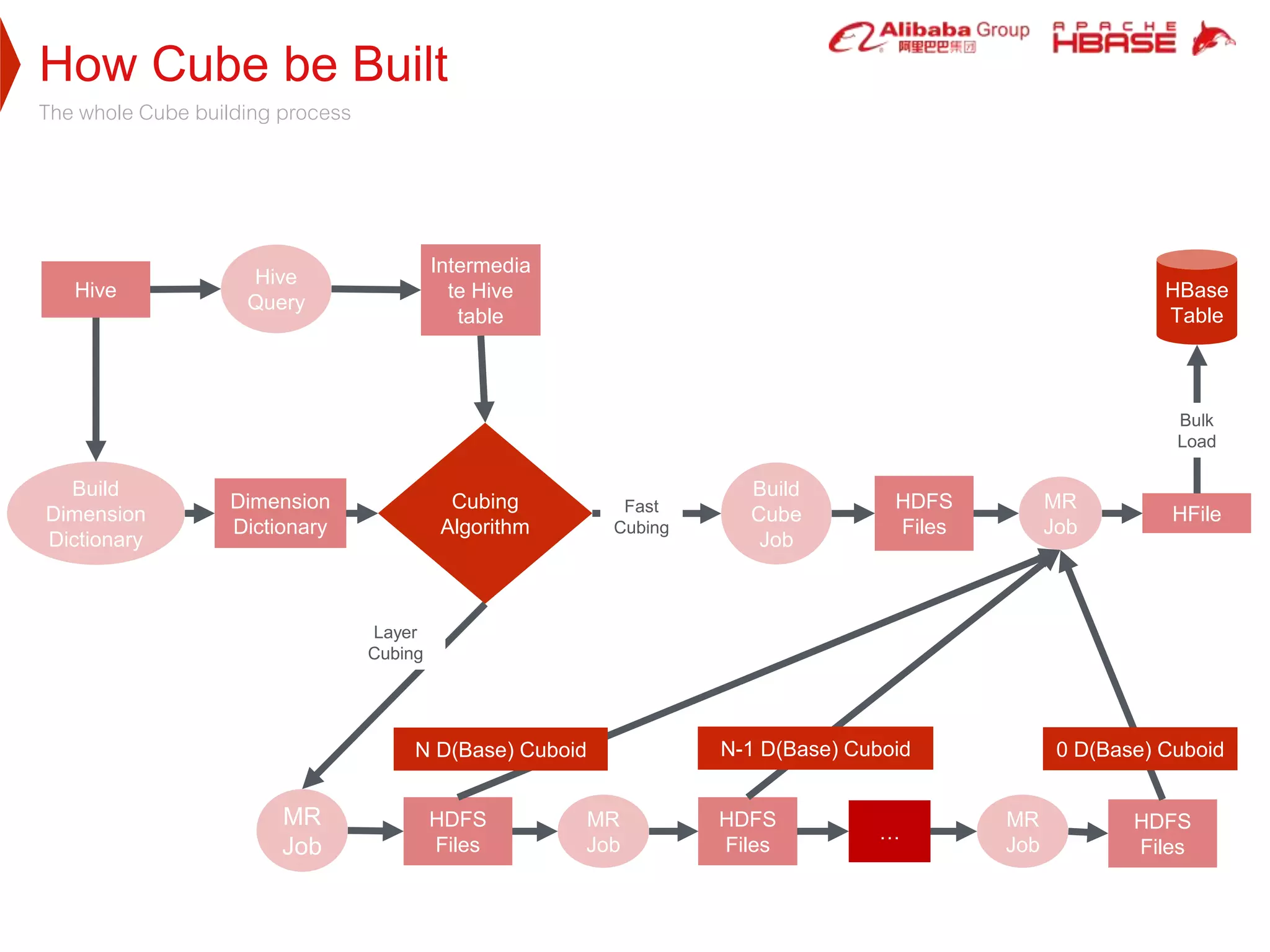
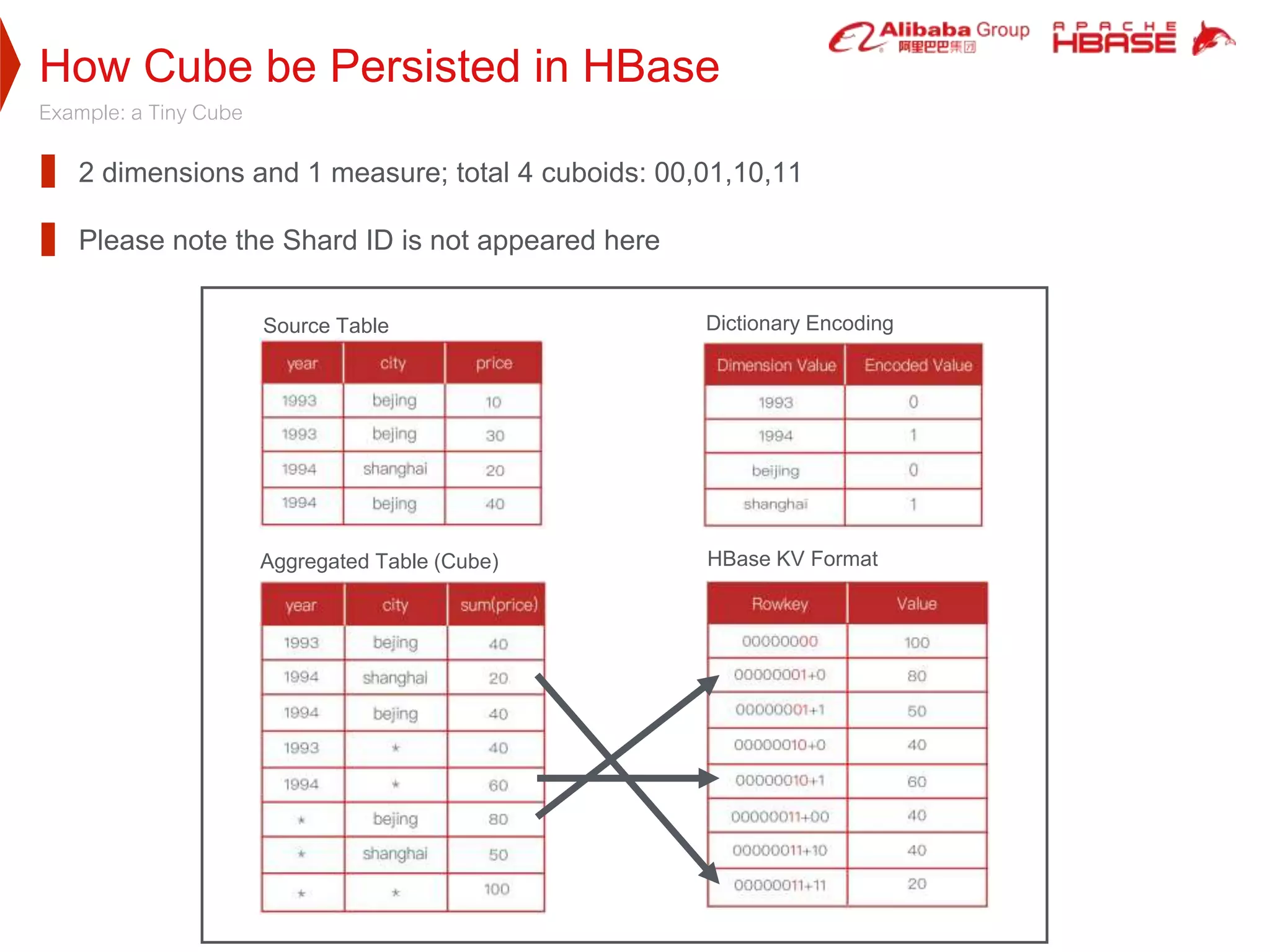
Apache Kylin is a high-performance OLAP engine designed for big data, providing fast query responses and easy integration with BI tools. It utilizes HBase for storage, benefiting from its low latency and high capacity, while supporting massive data volumes and real-time queries. The document outlines Kylin's architecture, cube building process, and application use cases across various industries, including telecom and e-commerce.