Contacts
Haesun Park
Email :haesunrpark@gmail.com
Meetup: https://www.meetup.com/Hongdae-Machine-Learning-Study/
Facebook : https://facebook.com/haesunrpark
Blog : https://tensorflow.blog
2
3.
Book
파이썬 라이브러리를 활용한머신러닝, 박해선.
(Introduction to Machine Learning with Python, Andreas
Muller & Sarah Guido의 번역서입니다.)
번역서의 1장과 2장은 블로그에서 무료로 읽을 수 있습니다.
원서에 대한 프리뷰를 온라인에서 볼 수 있습니다.
Github:
https://github.com/rickiepark/introduction_to_ml_with_python/
3
모델 평가
비지도 학습의평가는 정성적이므로 지도 학습의 문제에 집중
train_test_split à fit à score
교차 검증, R2 이외의 지표 등을 배웁니다. 5
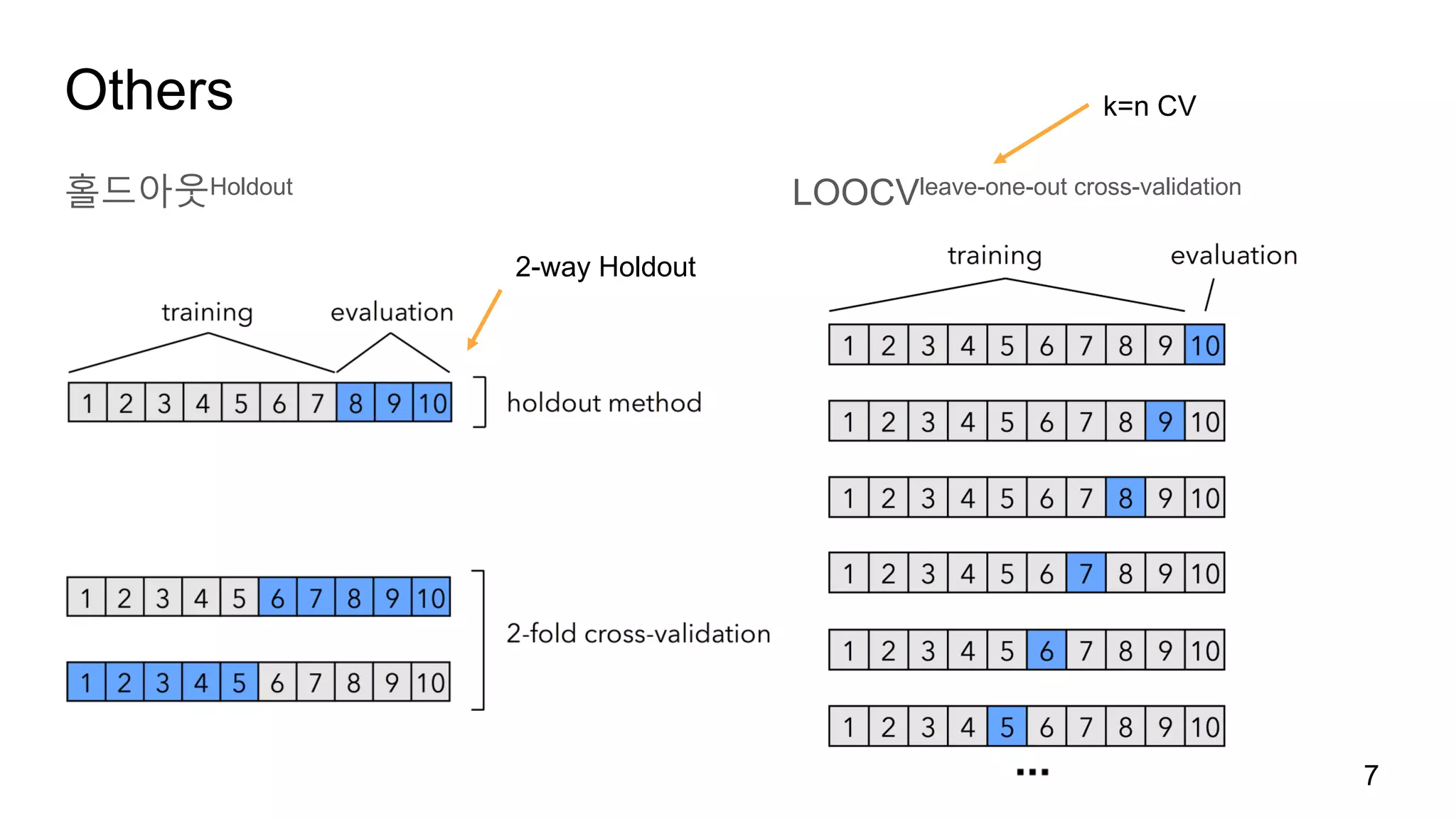
6.
교차 검증cross-validation
k-겹 교차검증k-fold cross-validation (k=5 or k=10)
1. 훈련 데이터를 k개의 부분 집합(폴드)으로 나눕니다.
2. 첫 번째 폴드를 테스트 세트로하고 나머지 폴드로 모델을 훈련 시킵니다.
3. 테스트 폴드를 바꾸어 가며 모든 폴드가 사용될때까지 반복합니다.
6
교차 검증의 장점
train_test_split는무작위로 데이터를 나누기 때문에 우연히 평가가 좋게 혹은
나쁘게 나올 수 있음
à모든 폴드가 테스트 대상이 되기 때문에 공평함
train_test_split는 보통 70%~80%를 훈련에 사용함
à 10겹 교차 검증은 90%를 훈련에 사용하기 때문에 정확한 평가를 얻음
모델이 훈련 데이터에 얼마나 민감한지 가늠할 수 있음
[1, 0.967, 0.933, 0.9, 1] à 90~100% Accuracy
[단점]: 데이터를 한 번 나누었을 때보다 k개의 모델을 만드므로 k배 느림
[주의]: cross_val_score는 교차 검증 동안 만든 모델을 반환하지 않습니다!
9
10.
교차 검증의 함정
3-겹교차 검증일 경우 테스트 세트에는 한 종류의 붓꽃만 포함됩니다.
10
KFold(n_splits=3)
11.
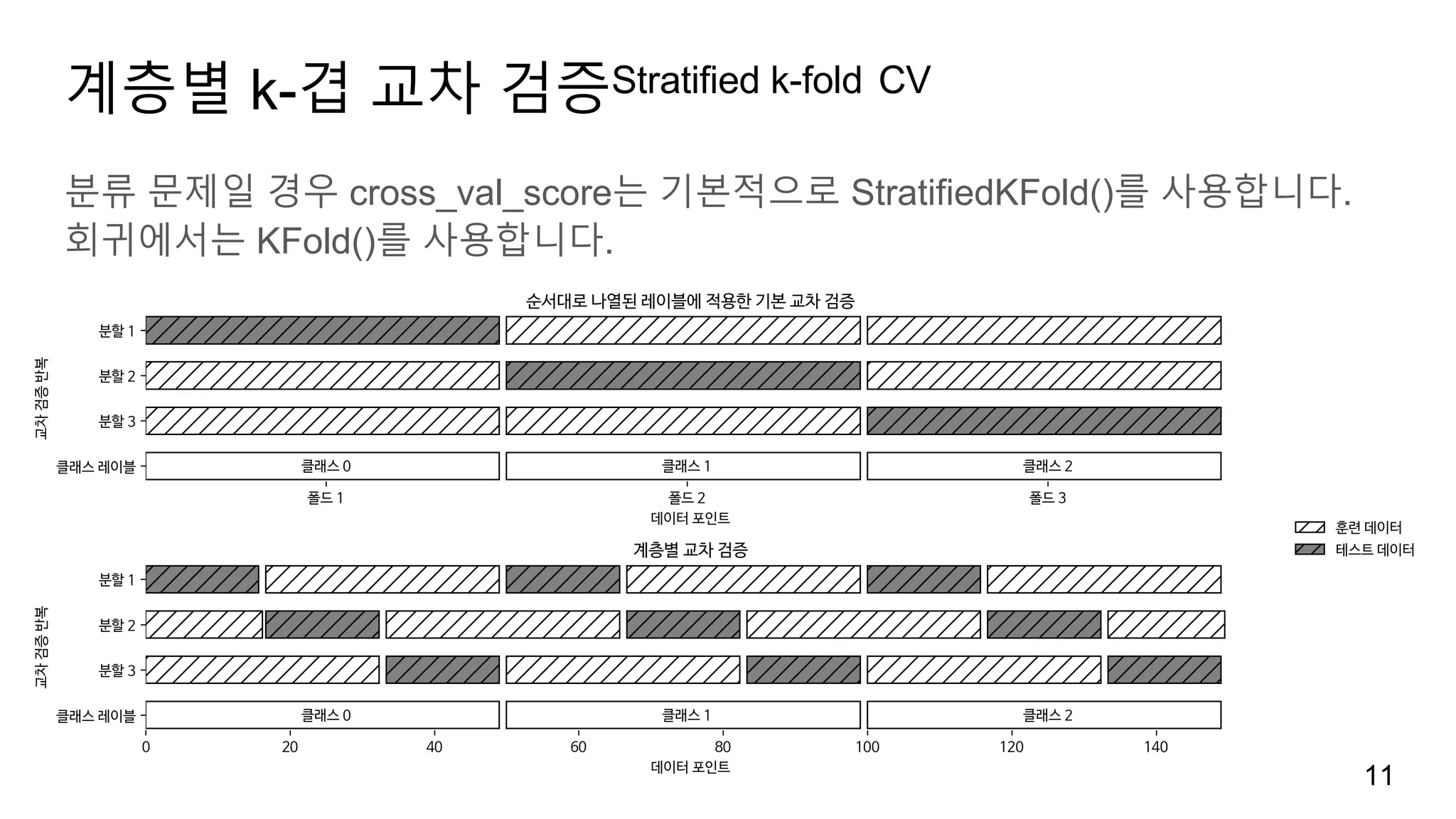
계층별 k-겹 교차검증Stratified k-fold CV
11
분류 문제일 경우 cross_val_score는 기본적으로 StratifiedKFold()를 사용합니다.
회귀에서는 KFold()를 사용합니다.
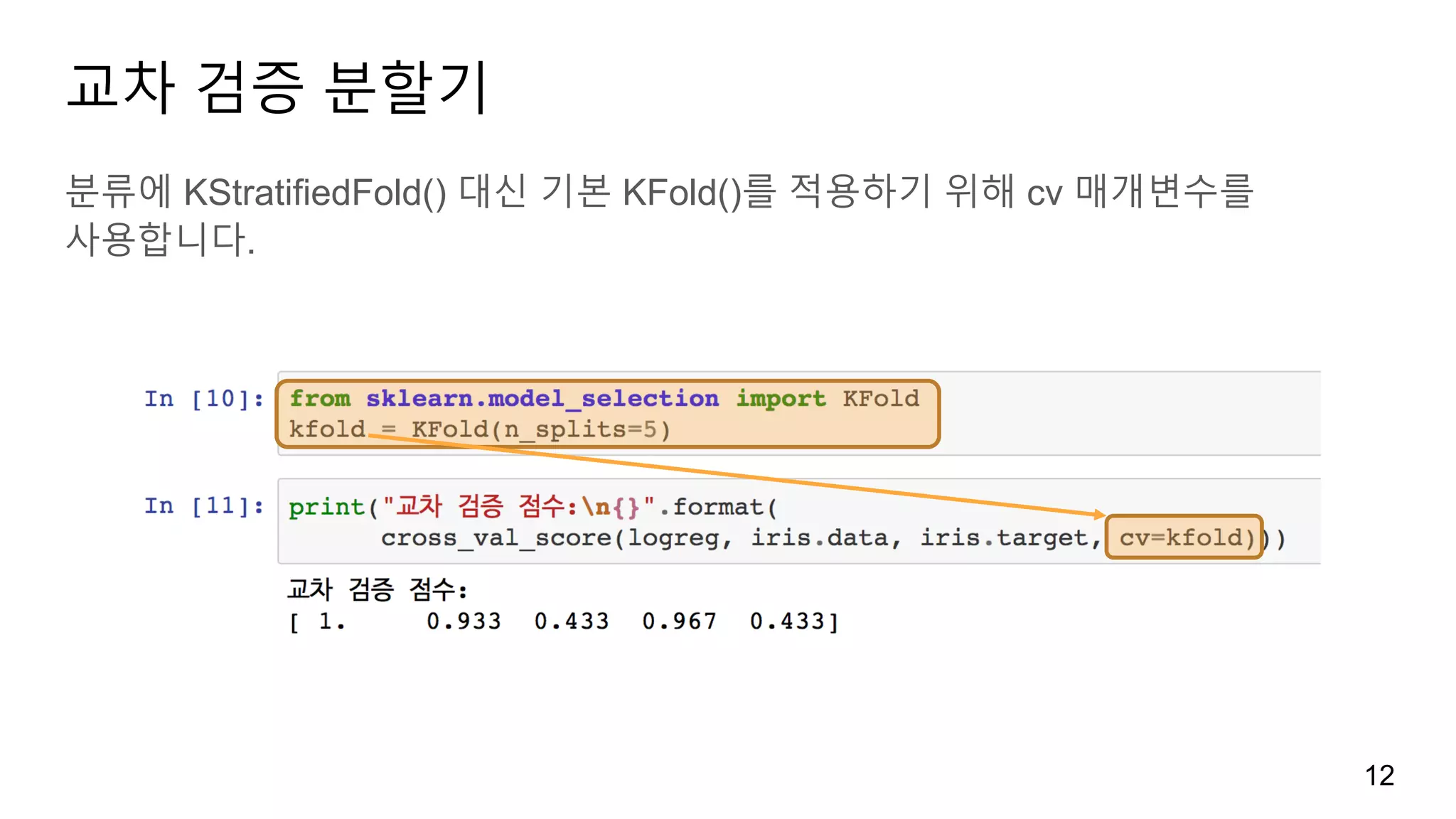
12.
교차 검증 분할기
분류에KStratifiedFold() 대신 기본 KFold()를 적용하기 위해 cv 매개변수를
사용합니다.
12
그룹별 교차 검증
타깃에따라 폴드를 나누지 않고 입력 특성에 따라 폴드를 나누어야 할 경우
예를 들어 100장의 사진 데이터로 사람의 표정을 분류하는 문제에서 한 사람이
훈련 세트와 테스트 세트에 모두 나타날 경우 분류기의 성능을 정확히 측정할 수
없습니다.(의료 정보나 음성 인식 등에서도)
입력 데이터의 그룹 정보를 받을 수 있는 GroupKFold()를 사용합니다.
cross_val_score(model, X, y, groups, cv=GroupKFold(n_splits=3))
...
cv.split(X, y, groups)
...
17
검증 세트validation set
테스트세트로 여러가지 매개변수 조합에 대해 평가했다면 이 모델이 새로운
데이터도 동일한 성능을 낸다고 생각하는 것은 매우 낙관적인 추정입니다.
최종 평가를 위해서는 독립된 데이터 세트가 필요합니다.
검증 세트validation set 혹은 개발 세트dev set
22
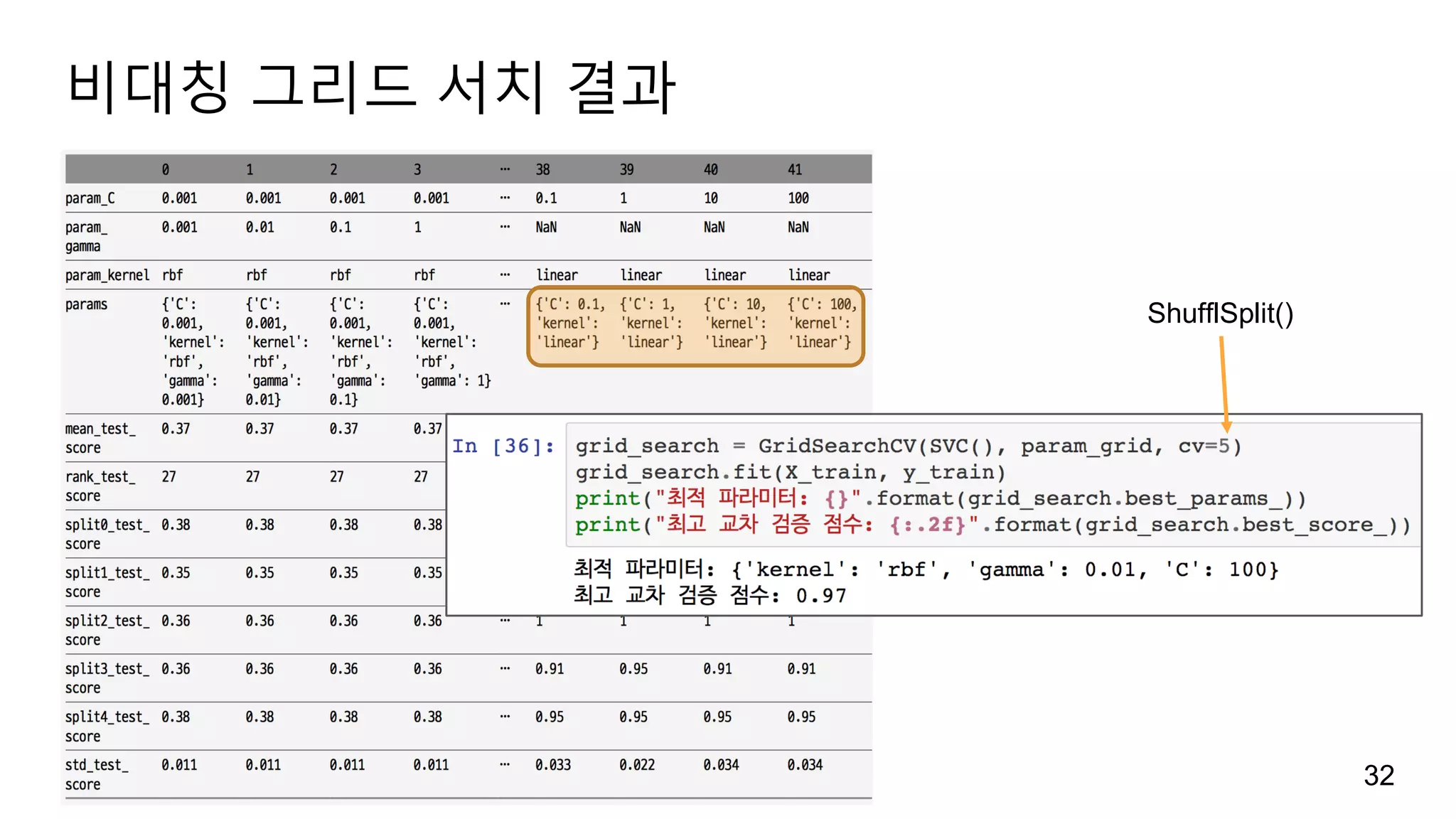
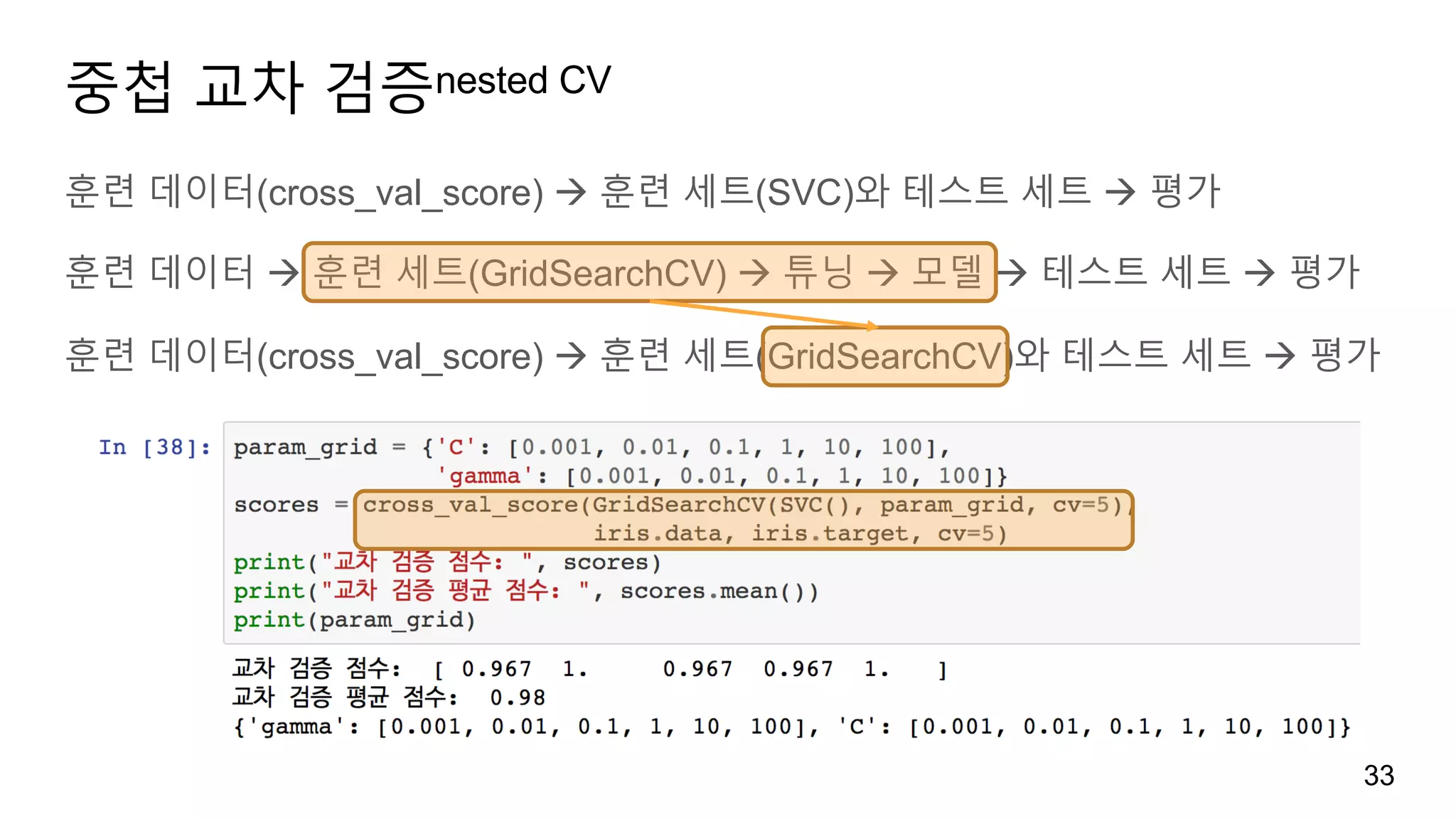
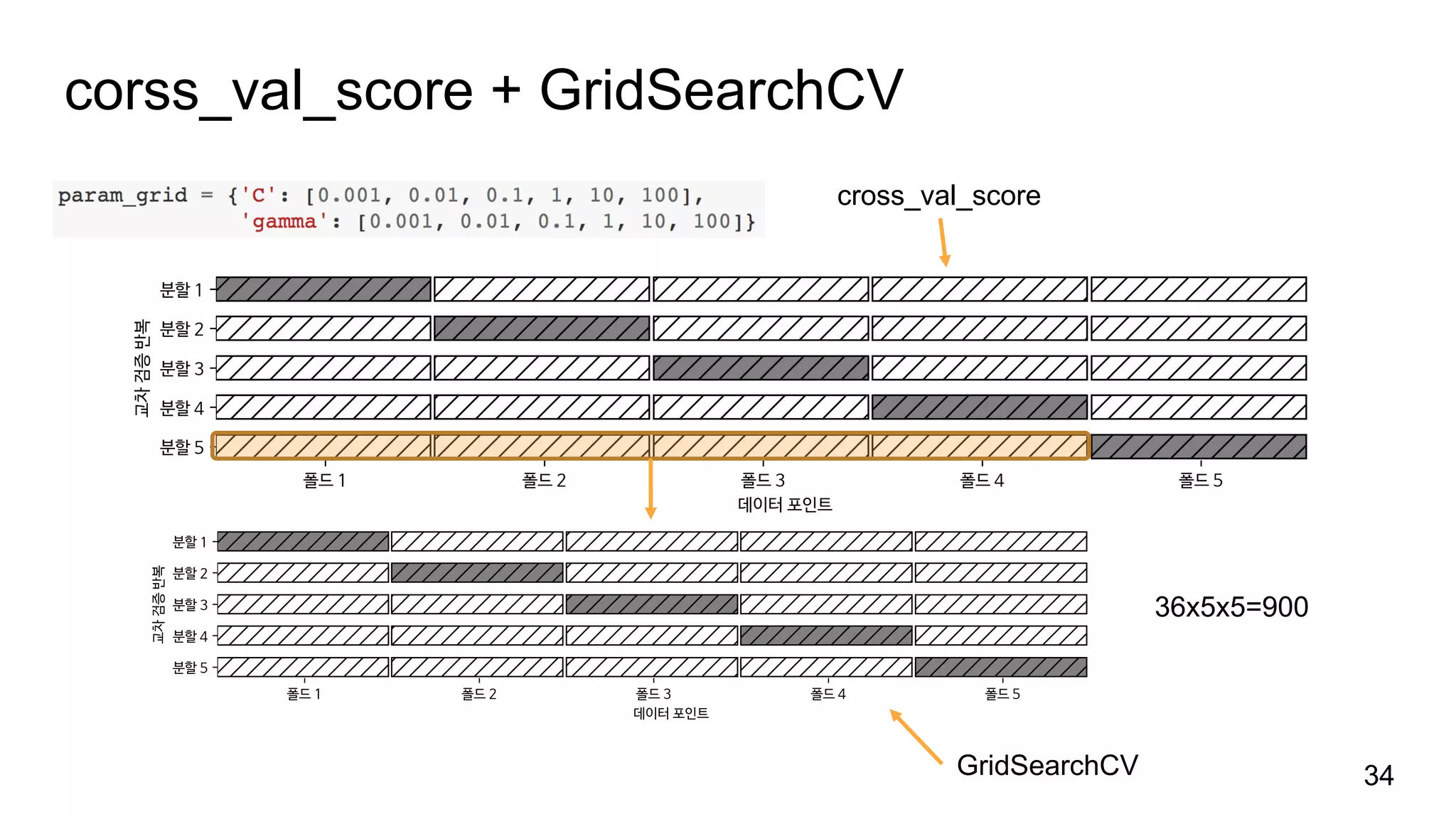
중첩 교차 검증nestedCV
훈련 데이터(cross_val_score) à 훈련 세트(SVC)와 테스트 세트 à 평가
훈련 데이터 à 훈련 세트(GridSearchCV) à 튜닝 à 모델 à 테스트 세트 à 평가
훈련 데이터(cross_val_score) à 훈련 세트(GridSearchCV)와 테스트 세트 à 평가
33
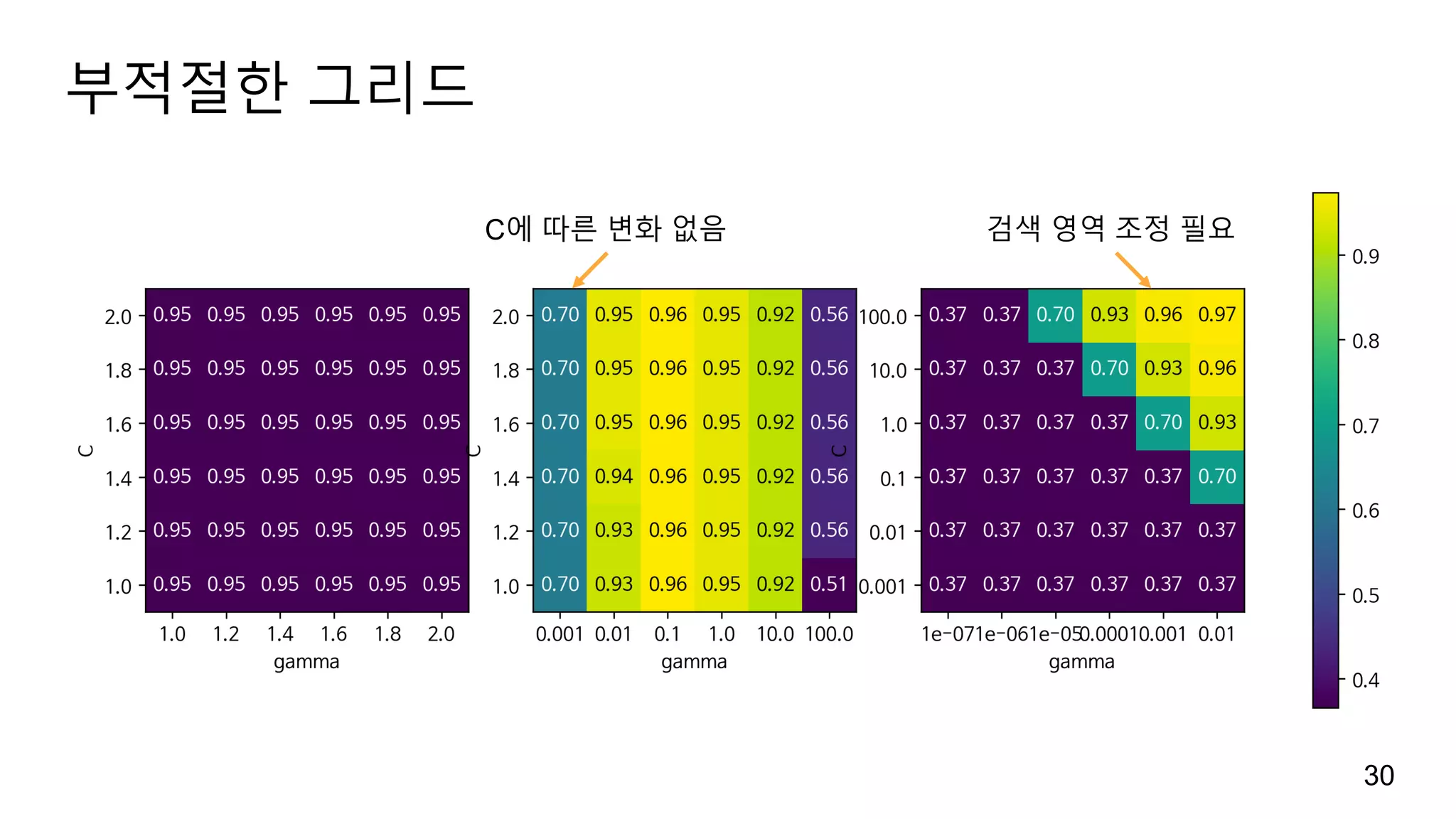
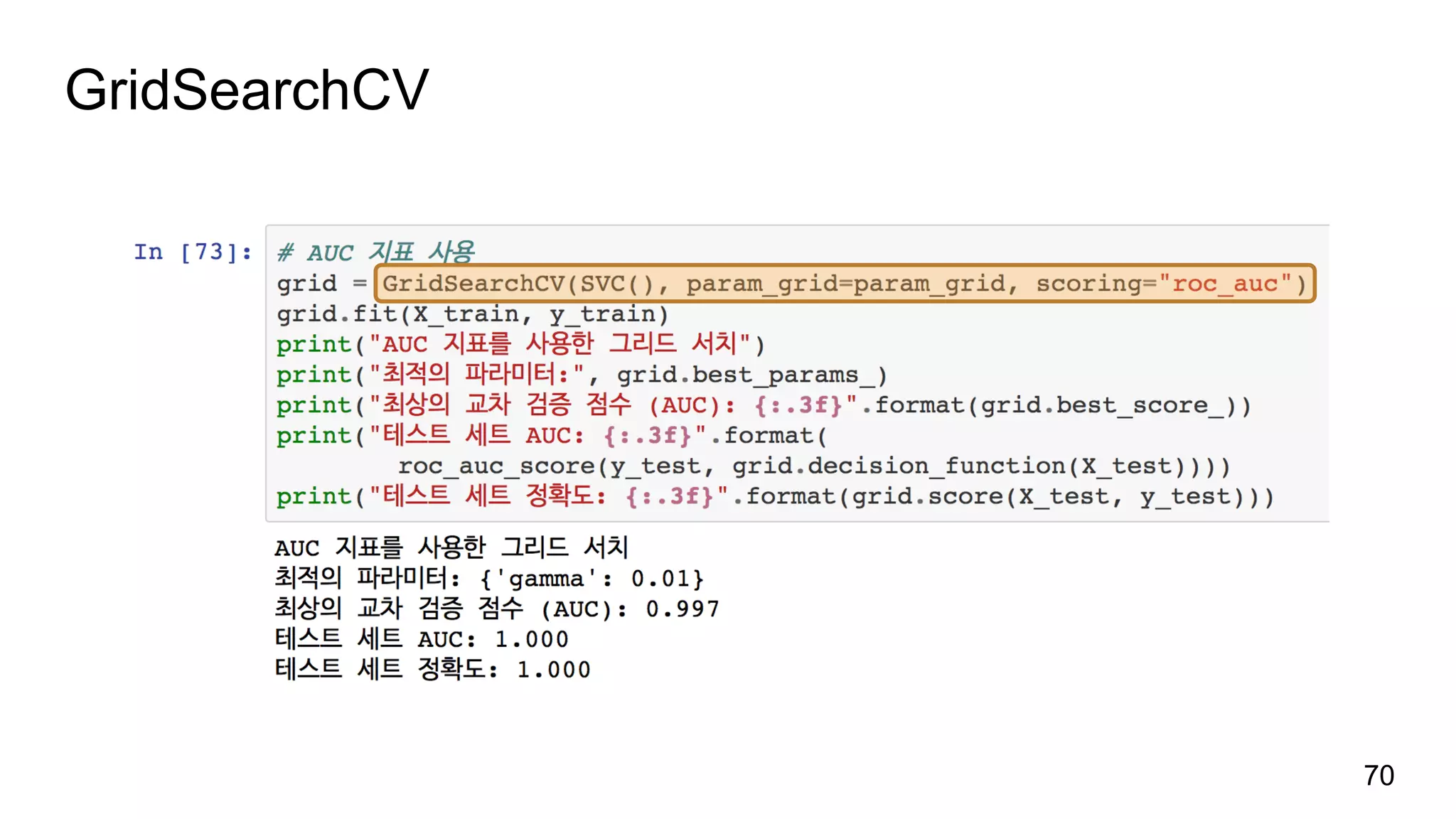
병렬화
그리드 서치는 연산에비용이 많이 들지만 매개변수 조합마다 쉽게 병렬화 가능
GridSearchCV와 cross_val_score의 n_jobs에 사용할 CPU 코어수를 지정할 수
습니다(기본 1, 최대 -1).
하지만 GridSearchCV와 RandomForestClassifier 같은 모델이 동시에 n_jobs
옵션을 사용할 수 없습니다(이중 fork로 데몬 프로세스가 되는 것을 방지).
마찬가지로 cross_val_score와 GridSearchCV도 동시에 n_jobs 옵션을 사용할 수
없습니다.
35
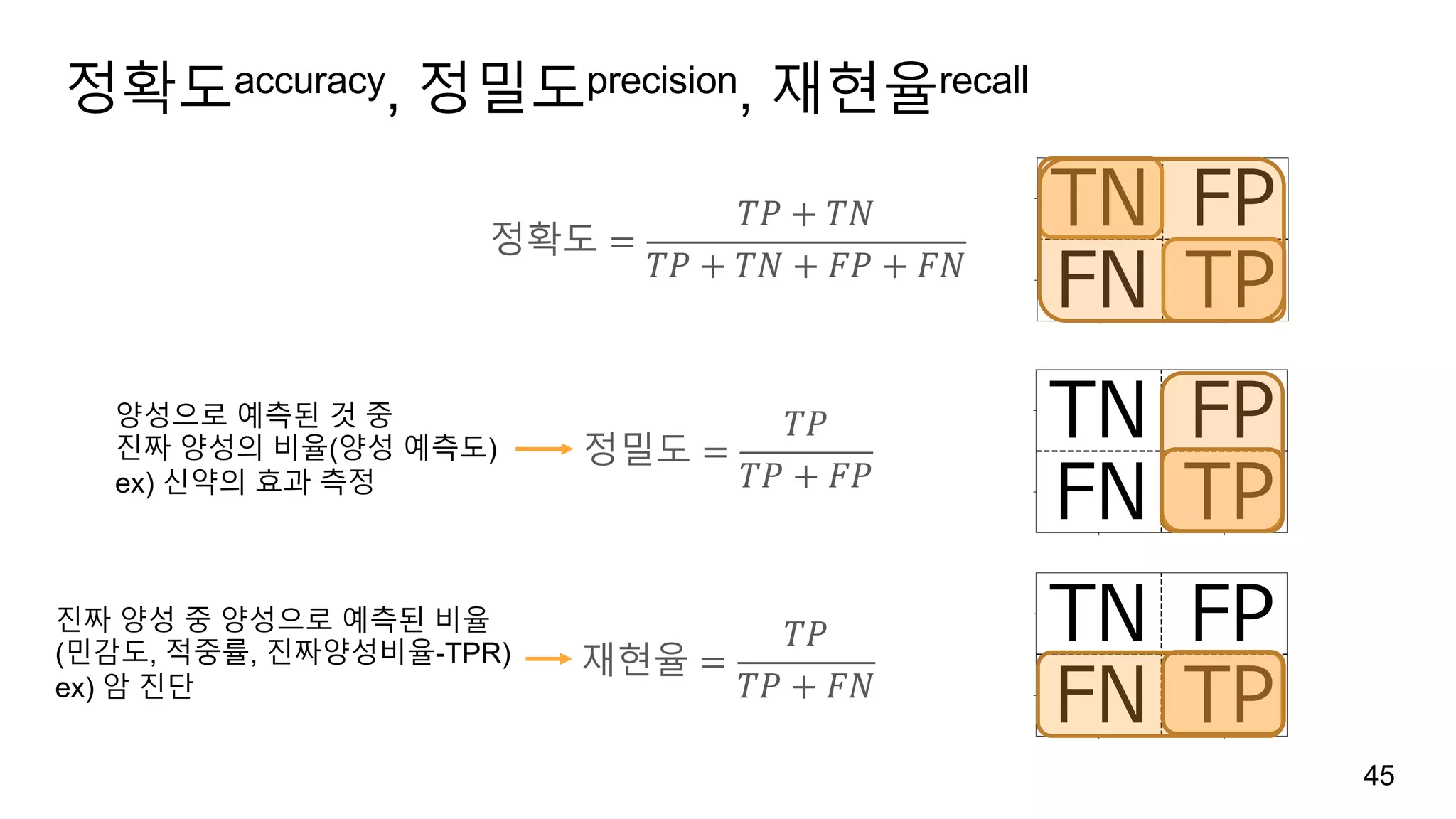
평가 지표
일반적으로 회귀:R2, 분류: 정확도를 사용합니다.
비즈니스 임팩트를 고려하여 목표를 설정합니다(교통사고 회수, 입원 환자수 등)
비즈니스 지표를 얻으려면 운영 시스템에 적용해야 알 수 있는 경우가 많으므로
대리할 수 있는 평가 지표를 사용합니다(보행자 이미지를 사용한 자율 주행 테스트)
시스템의 목표에 따라 방문 고객이 10% 늘어나는 모델을 찾을 수 있지만 매출은
15% 줄어들 수 있습니다(경우에 따라 고객이 아니라 매출을 비즈니스 지표로
삼아야 합니다).
37
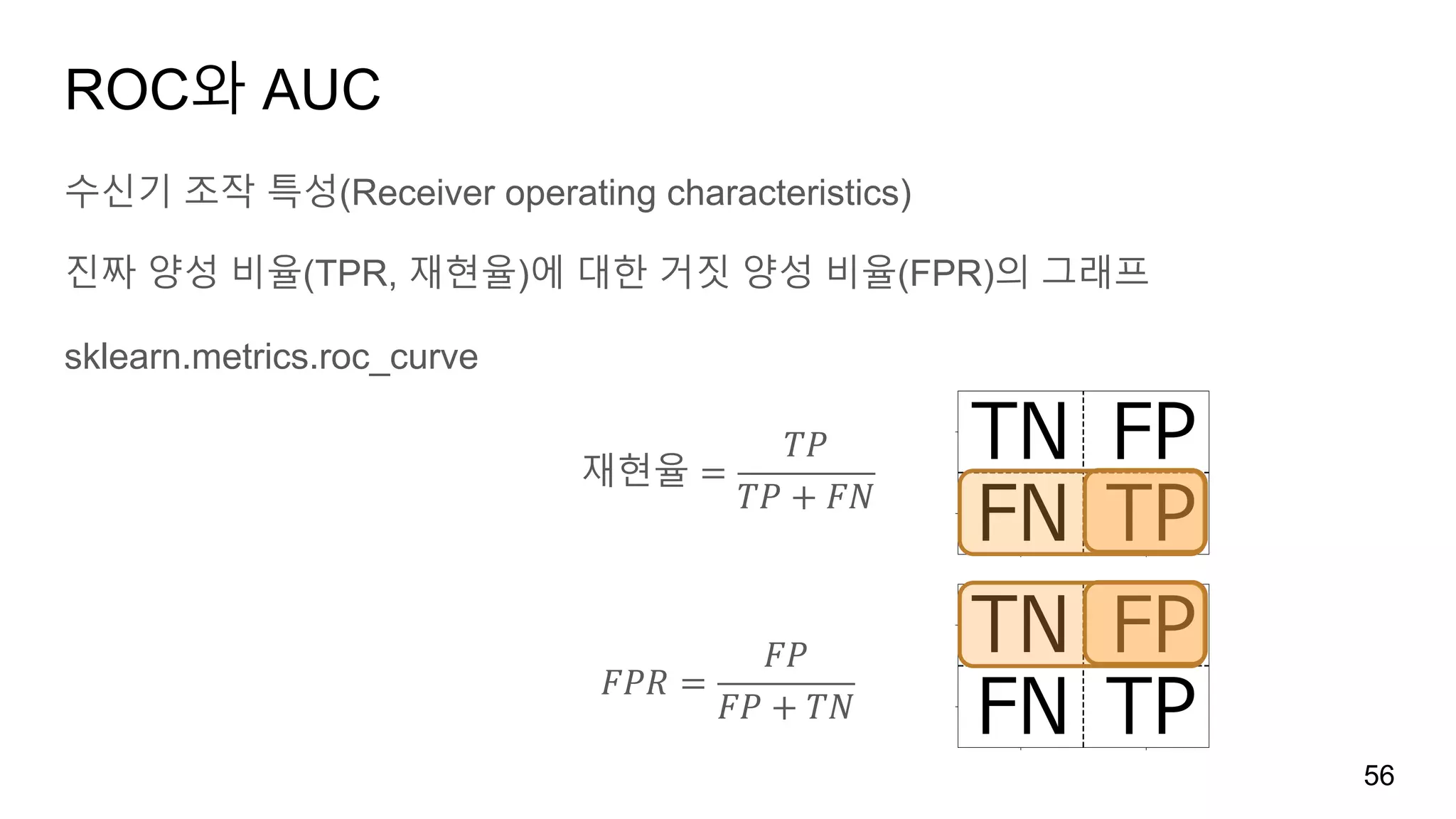
에러의 종류
양성 클래스(관심대상)와 음성 클래스로 나뉩니다.
암진단: 암(양성 테스트, 악성), 정상(음성 테스트)
양성 테스트(암)를 양성 클래스, 음성 테스트(정상)을 음성 클래스라 할 때
정상을 양성 클래스로 분류(거짓 양성false positive): 추가적인 검사 동반
암을 음성 클래스로 분류(거짓 음성false negative): 건강을 해침
거짓 양성을 타입 I 에러, 거짓 음성을 타입 II 에러라고도 합니다.
거짓 양성과 거짓 음성이 비슷한 경우는 드물며 오류를 비용으로 환산하여
비즈니스적인 판단을해야 합니다.
39
40.
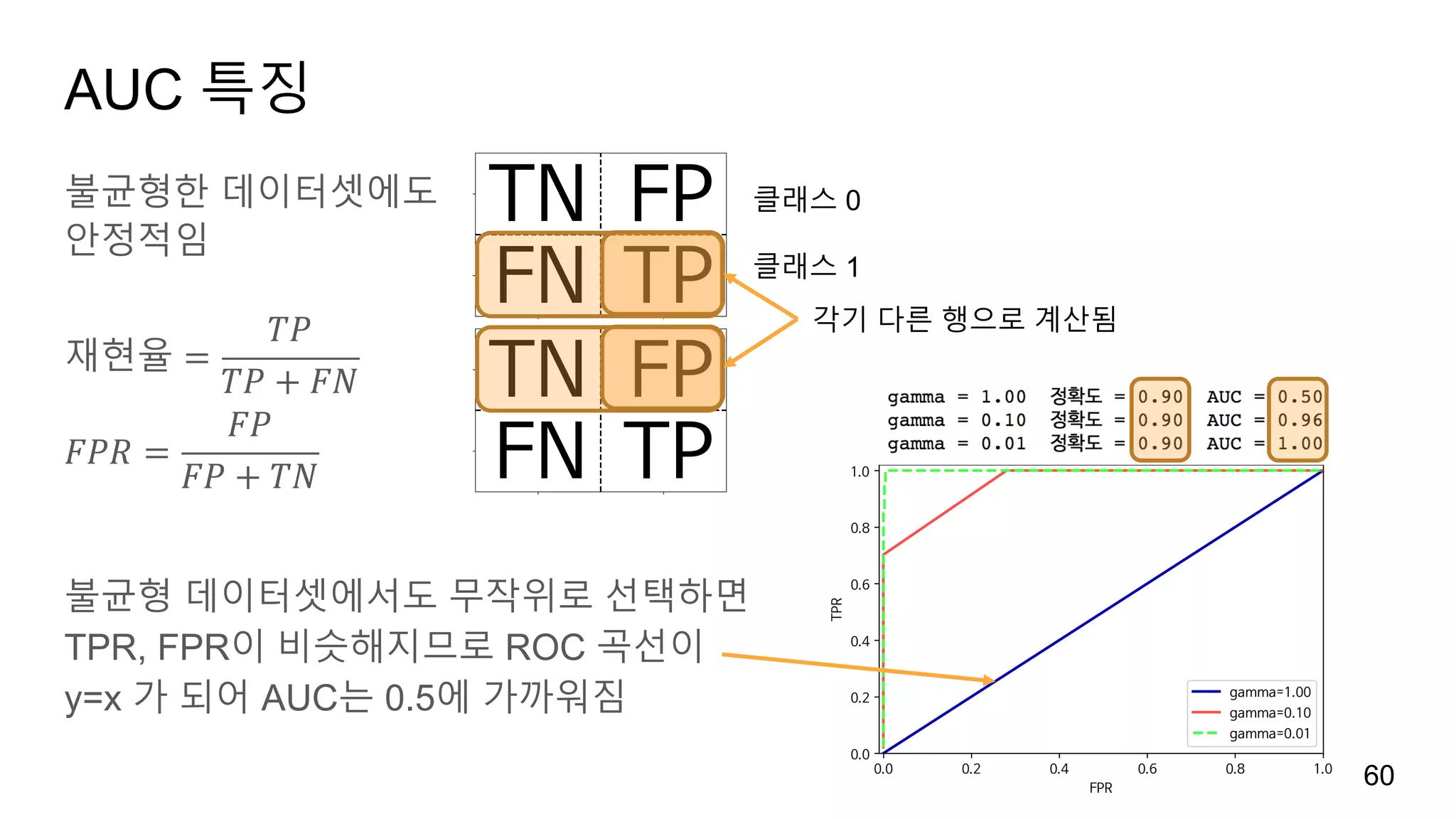
불균형 데이터셋
예) 광고노출 수와 클릭 수: 99 vs 1 (현실에서는 0.1% 미만입니다)
무조건 ‘클릭 아님’으로 예측하면 99%의 정확도를 가진 분류기가 됩니다.
불균형한 데이터셋에서는 정확도만으로는 모델이 진짜 좋은지 모릅니다.
40
숫자 9는 1, 나머지는 0인 타깃값
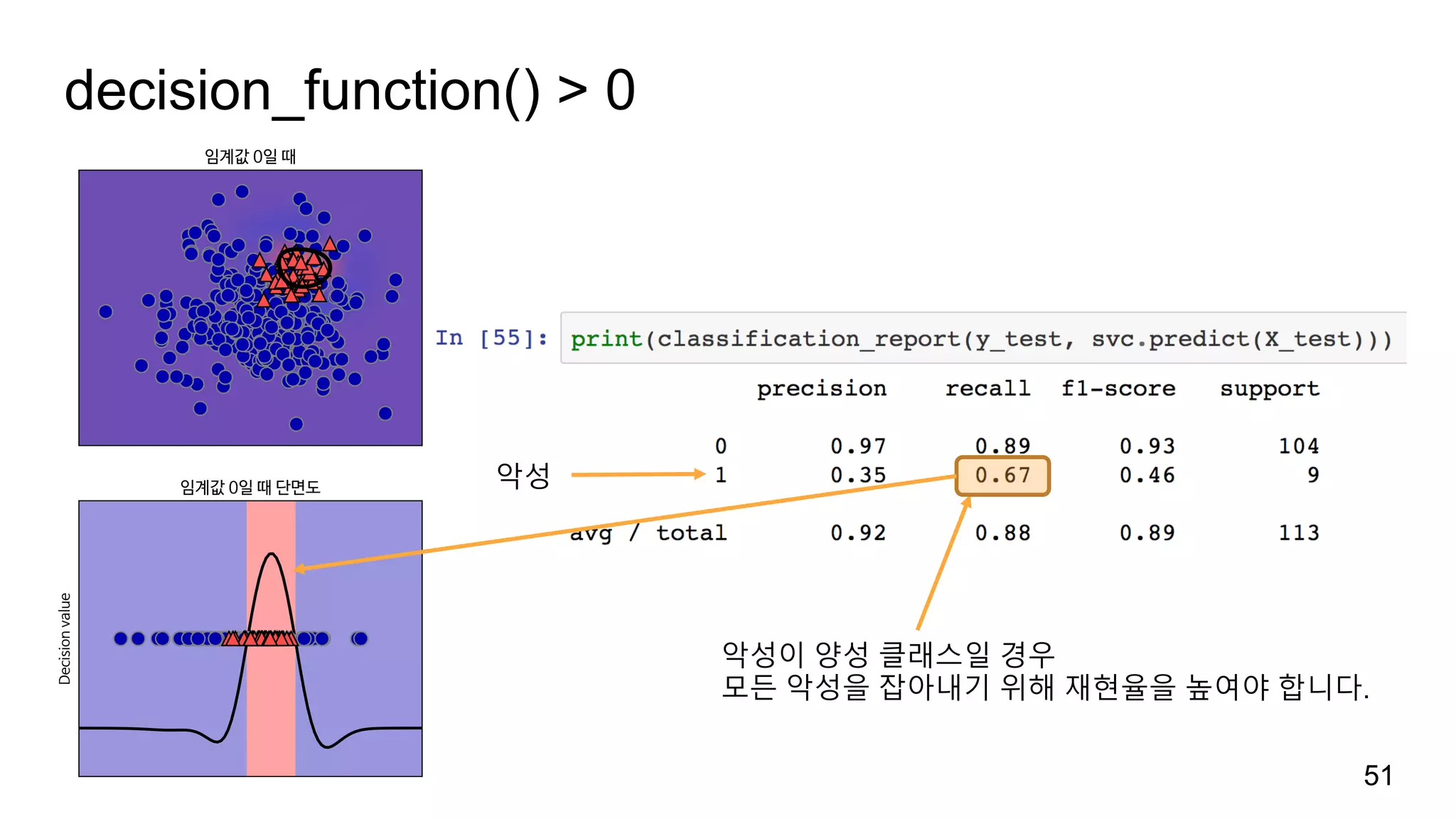
불확실성
decision_function()은 선형 판별식이0보다 크면 양성으로,
predict_proba()는 선형 판별식에 시그모이드 함수를 적용하여 0.5보다 크면
양성으로 판단합니다.
이 함수들의 반환값이 클수록 예측에 대한 확신이 높다고 간주할 수 있습니다.
50
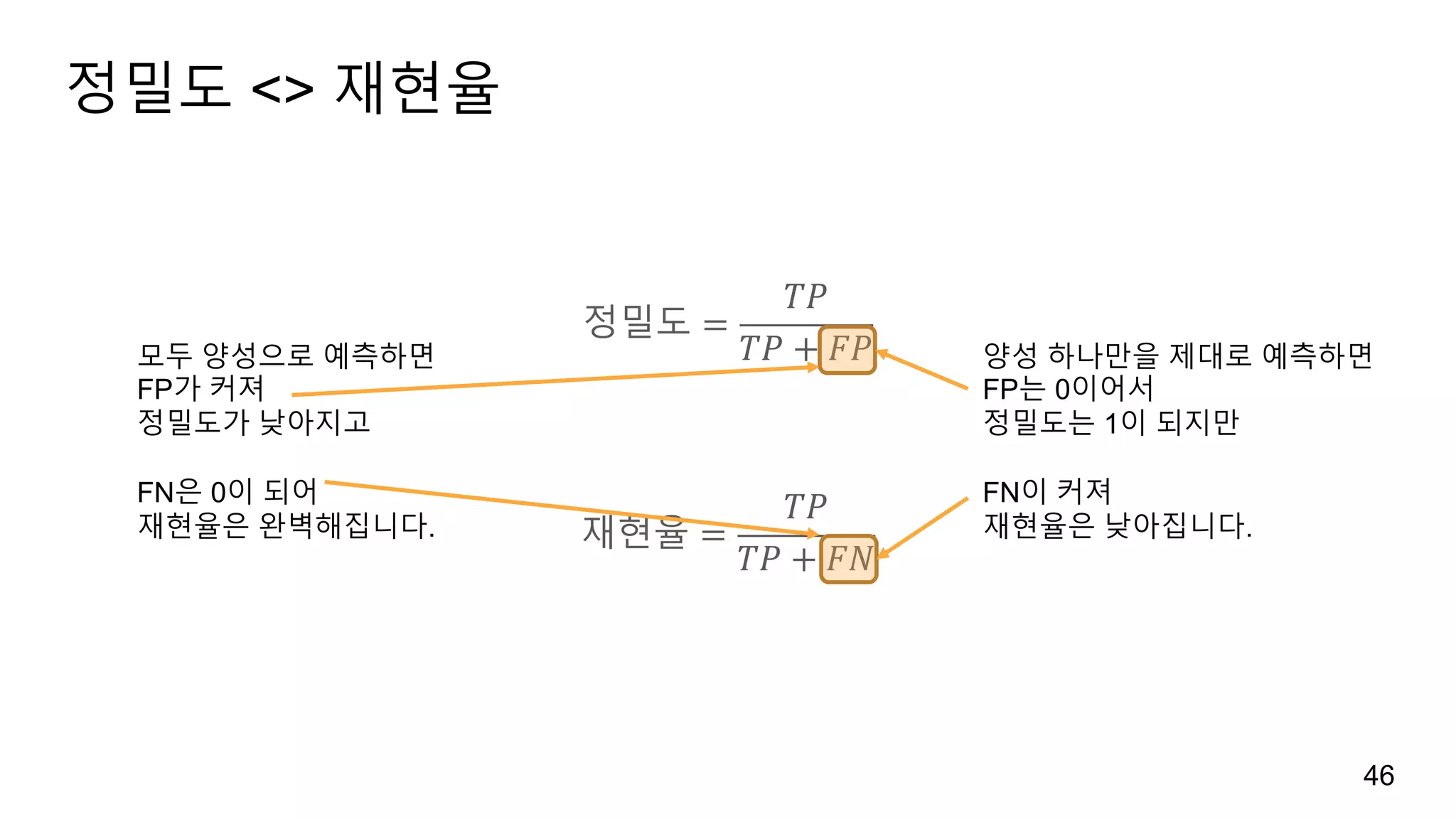
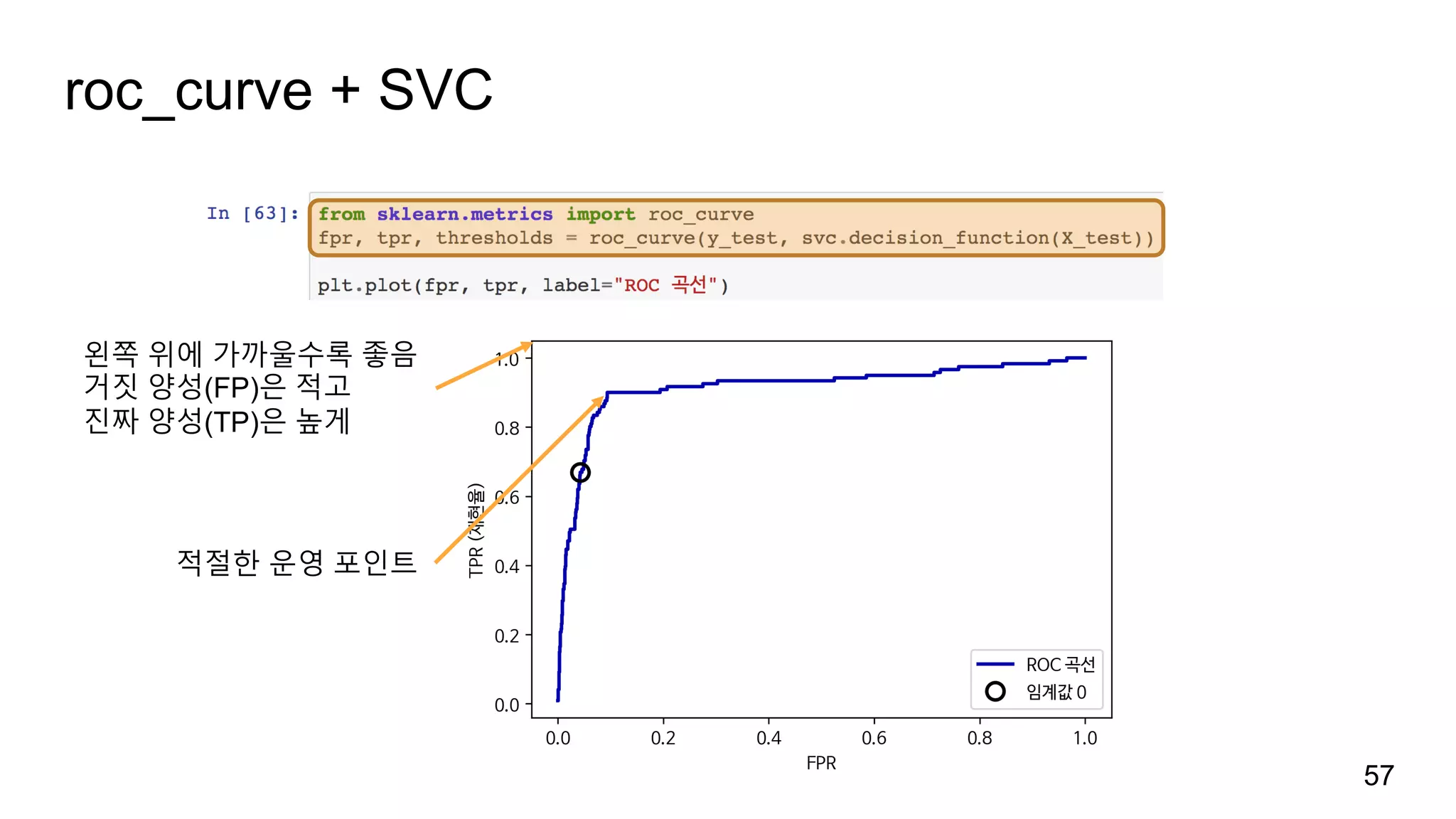
정밀도-재현율 곡선
정밀도와 재현율의트레이드 오프를 조정
decision_function과 predict_proba 함수를 이용하여 운영 포인트operating point 결정
53
decision_function의 각 단계
(0.75, 0.4)
(0.52, 0.4)
하나의 f1-점수 오른쪽 위에 가까울수록 좋음
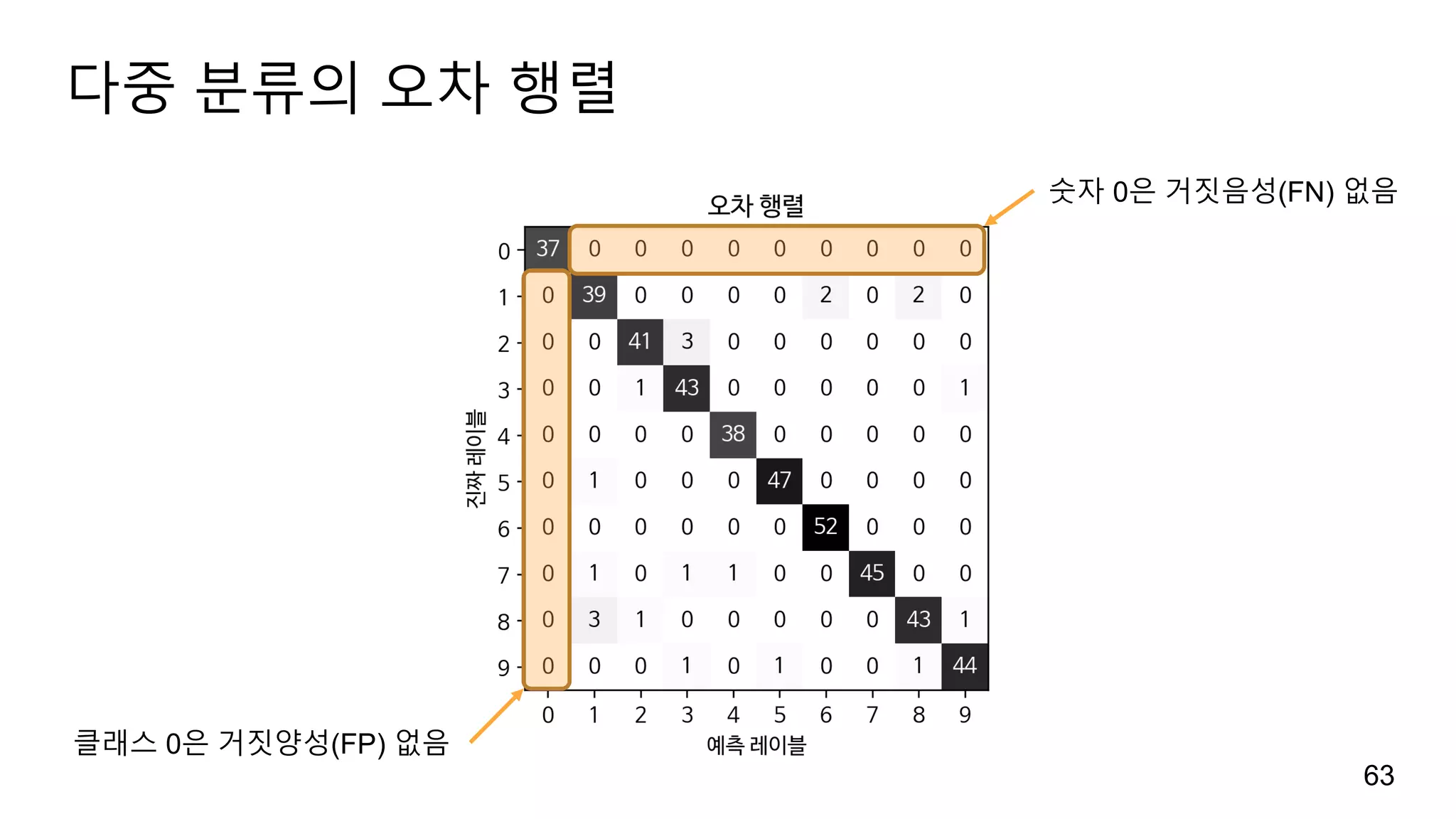
다중 분류 f1-점수
다중분류용 f1-점수는 한 클래스를 양성 클래스로 두고 나머지를 음성으로
간주하여 각 클래스마다 f1-점수를 계산합니다.
f1_score(y_test, pred, average=“...”)
• “macro”: 가중치 없이 평균을 냅니다.
• “weighted”: 클래스별 샘플 수로 가중치를 두어 평균을 냅니다.(분류 리포트)
• “micro”: 모든 클래스의 FP, FN, TP를 합하여 f1-점수를 계산합니다.
• “binary”: 이진 분류에 해당, 기본값.
65
중요한 주의 사항
교차검증을 해야 합니다.
훈련 데이터: 모델 학습
검증 데이터: 모델과 매개변수 선택
테스트 데이터: 모델 평가
모델 선택과 평가에 적절한 지표를 사용합니다.
높은 정확도를 가진 모델 à 비즈니스 목표에 맞는 모델
현실에서는 불균형한 데이터셋이 아주 많음
거짓 양성(FP)과 거짓 음성(FN)이 많은 영향을 미침
73







![교차 검증의 장점
train_test_split는 무작위로 데이터를 나누기 때문에 우연히 평가가 좋게 혹은
나쁘게 나올 수 있음
à모든 폴드가 테스트 대상이 되기 때문에 공평함
train_test_split는 보통 70%~80%를 훈련에 사용함
à 10겹 교차 검증은 90%를 훈련에 사용하기 때문에 정확한 평가를 얻음
모델이 훈련 데이터에 얼마나 민감한지 가늠할 수 있음
[1, 0.967, 0.933, 0.9, 1] à 90~100% Accuracy
[단점]: 데이터를 한 번 나누었을 때보다 k개의 모델을 만드므로 k배 느림
[주의]: cross_val_score는 교차 검증 동안 만든 모델을 반환하지 않습니다!
9](https://image.slidesharecdn.com/5-170918143917/75/5-model-evaluation-and-improvement-9-2048.jpg)

![분류와 기본 KFold()
13
StratifiedKFold(n_splits=3): [0.961, 0.922, 0.958]](https://image.slidesharecdn.com/5-170918143917/75/5-model-evaluation-and-improvement-13-2048.jpg)


































































![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)








![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)







![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)



![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 9장 텐서플로 시작하기](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181127072259-thumbnail.jpg?width=640&height=640&fit=bounds)




