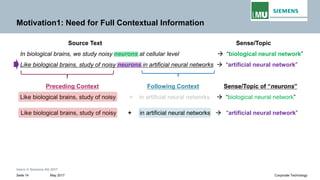
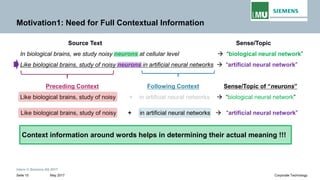
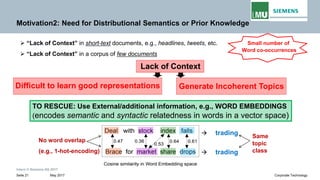
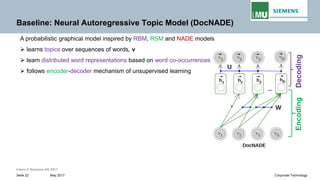
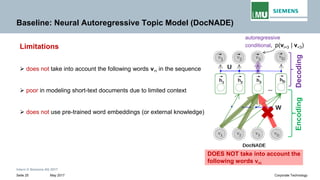
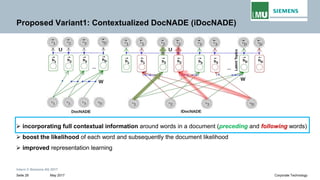
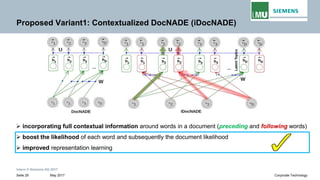
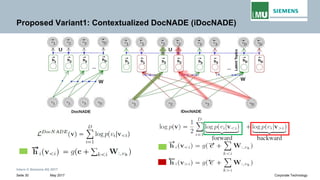
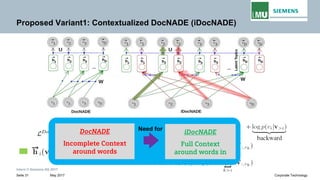
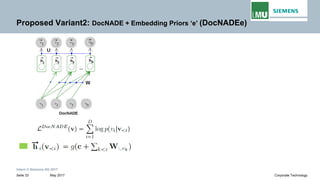
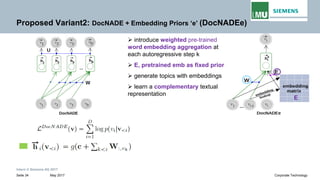
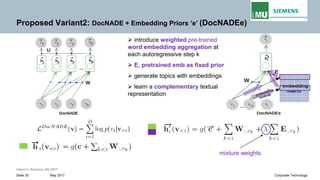
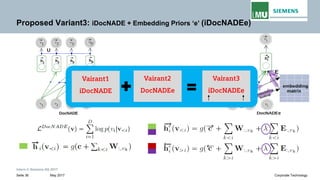
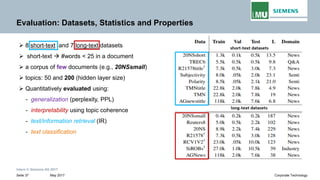
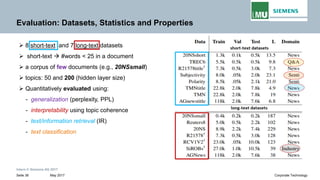
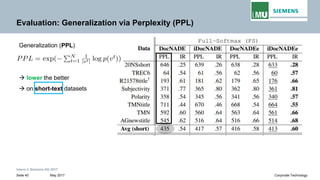
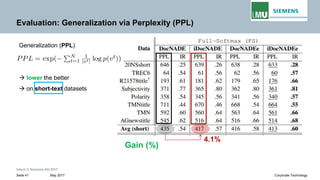
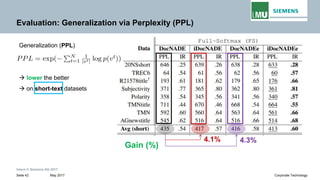
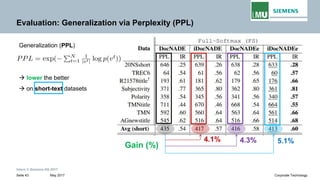
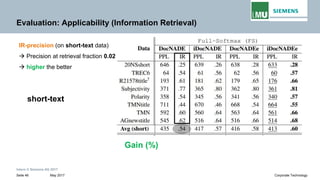
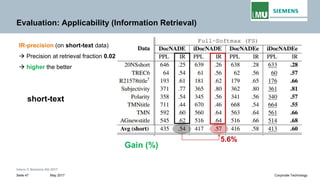
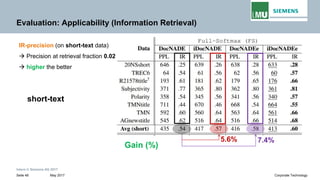
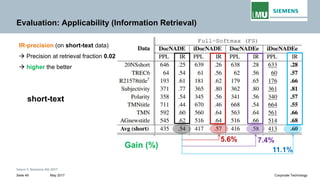
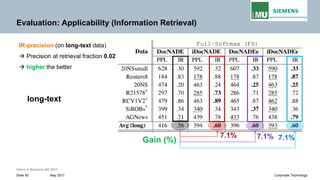
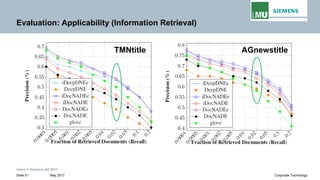
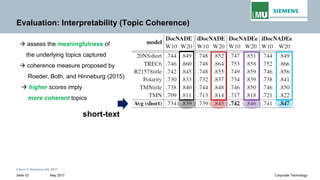
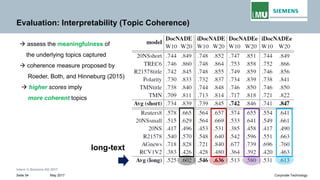
The document discusses advancements in neural autoregressive topic models, particularly focusing on contextual awareness and distributional semantics to enhance topic modeling for both short and long texts. It introduces proposed enhancements to the baseline model, DocNade, which include incorporating contextual information and word embeddings to improve topic coherence and evaluate the effectiveness of these models. Evaluations demonstrate benefits in generalization and information retrieval across various datasets.