Data models in precision agriculture: from IoT to big data analytics

Data models are abstract models that standardize data formats and relationships. In other words, data models describe the concepts that belong to a certain application domain (e.g., "Device" and "Farm" are concepts that belong to the "Agriculture" domain, and "Device" is also a concept in the domain of "Smart Cities"). Over the years, many data models (and ontologies) have been produced for the precision agriculture domain. On the one hand, such models provide standards for data transmission and representation. On the other hand, these models are not suited for (automated) data integration and analysis, which are core tasks in building decision support systems for precision agriculture ---digitalized systems that support farmers and technicians in making data-driven decisions. Following the advancements in big data technologies and internet of things systems, managing such systems is increasingly harder and requires not only standards to transmit and represent the data, but also to automatically integrate heterogeneous data into a uniform medium and to automate data analysis and fruition. While this is a well-known issue in the field of precision agriculture, where data models usually fuel data silos for ad-hoc independent applications (e.g., smart watering management, autonomous weeding systems, vegetation index computation), the synergy with computer science and database techniques could both answer these challenges and open novel research directions. In this poster, we (i) describe some of the state-of-the-art models for precision agriculture and their application (e.g., from the FIWARE ecosystem), (ii) factorize the limitations and issues of such models (e.g., inter-domain ambiguities, intra-domain inconsistency, wrong modeling practices), (iii) show how computer science techniques (e.g., entity resolution, data normalization, data provenance collection) can answer these issues, and (iv) introduce novel data-driven research directions for building unifying decision support systems.
Recommended
![[PhDThesis2021] - Augmenting the knowledge pyramid with unconventional data a...](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
More Related Content
Similar to Data models in precision agriculture: from IoT to big data analytics
Similar to Data models in precision agriculture: from IoT to big data analytics (20)
More from University of Bologna
More from University of Bologna (11)
Recently uploaded
Recently uploaded (20)
Data models in precision agriculture: from IoT to big data analytics
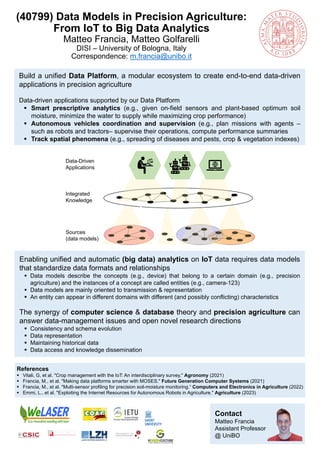
- 1. Contact Matteo Francia Assistant Professor @ UniBO (40799) Data Models in Precision Agriculture: From IoT to Big Data Analytics Matteo Francia, Matteo Golfarelli DISI – University of Bologna, Italy Correspondence: m.francia@unibo.it Enabling unified and automatic (big data) analytics on IoT data requires data models that standardize data formats and relationships ▪ Data models describe the concepts (e.g., device) that belong to a certain domain (e.g., precision agriculture) and the instances of a concept are called entities (e.g., camera-123) ▪ Data models are mainly oriented to transmission & representation ▪ An entity can appear in different domains with different (and possibly conflicting) characteristics The synergy of computer science & database theory and precision agriculture can answer data-management issues and open novel research directions ▪ Consistency and schema evolution ▪ Data representation ▪ Maintaining historical data ▪ Data access and knowledge dissemination Build a unified Data Platform, a modular ecosystem to create end-to-end data-driven applications in precision agriculture Data-driven applications supported by our Data Platform ▪ Smart prescriptive analytics (e.g., given on-field sensors and plant-based optimum soil moisture, minimize the water to supply while maximizing crop performance) ▪ Autonomous vehicles coordination and supervision (e.g., plan missions with agents – such as robots and tractors– supervise their operations, compute performance summaries ▪ Track spatial phenomena (e.g., spreading of diseases and pests, crop & vegetation indexes) References ▪ Vitali, G, et al. "Crop management with the IoT: An interdisciplinary survey." Agronomy (2021) ▪ Francia, M., et al. "Making data platforms smarter with MOSES." Future Generation Computer Systems (2021) ▪ Francia, M., et al. "Multi-sensor profiling for precision soil-moisture monitoring.“ Computers and Electronics in Agriculture (2022) ▪ Emmi, L., et al. "Exploiting the Internet Resources for Autonomous Robots in Agriculture." Agriculture (2023) Sources (data models) Integrated Knowledge Data-Driven Applications