Downloaded 33 times






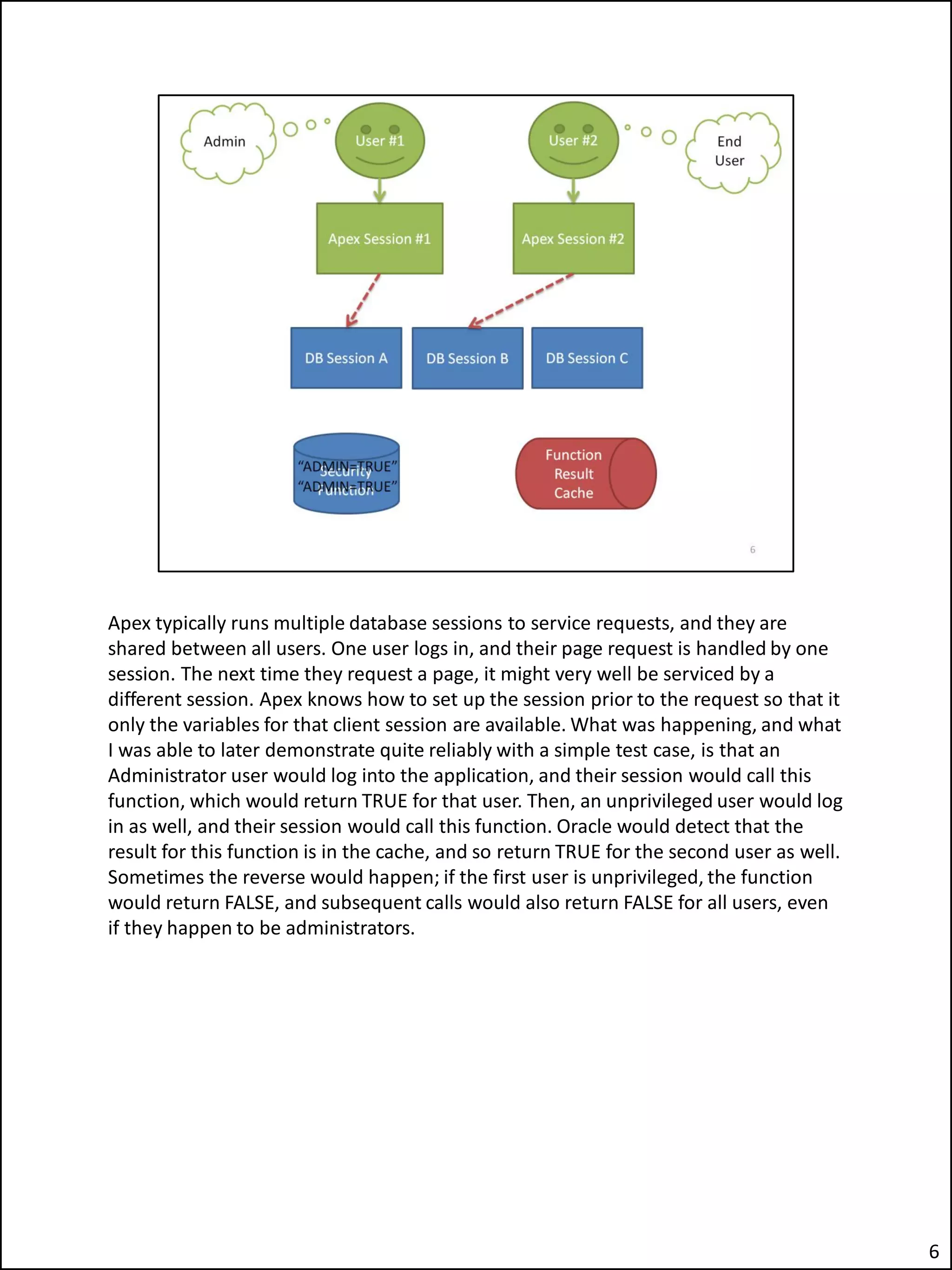











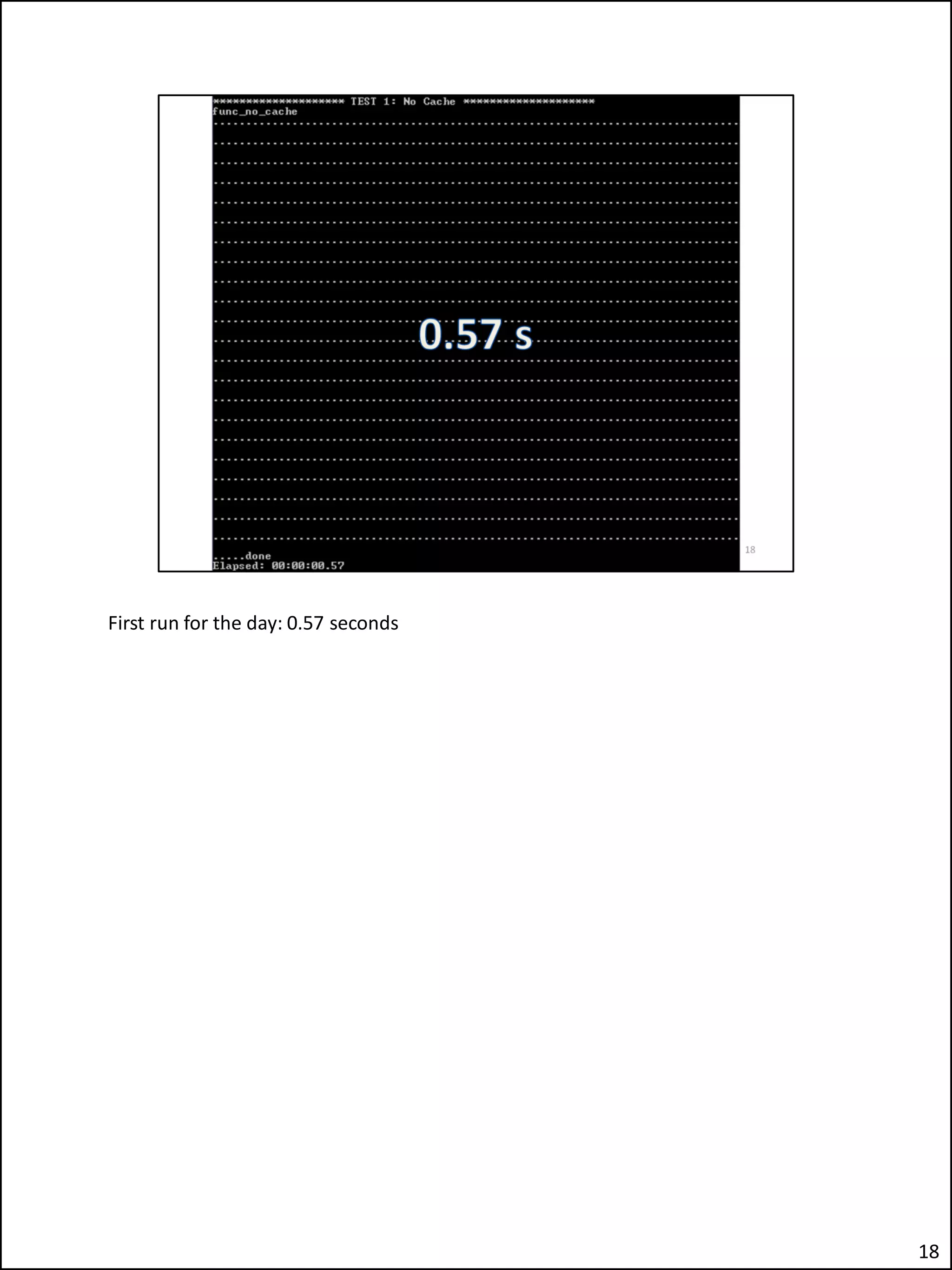













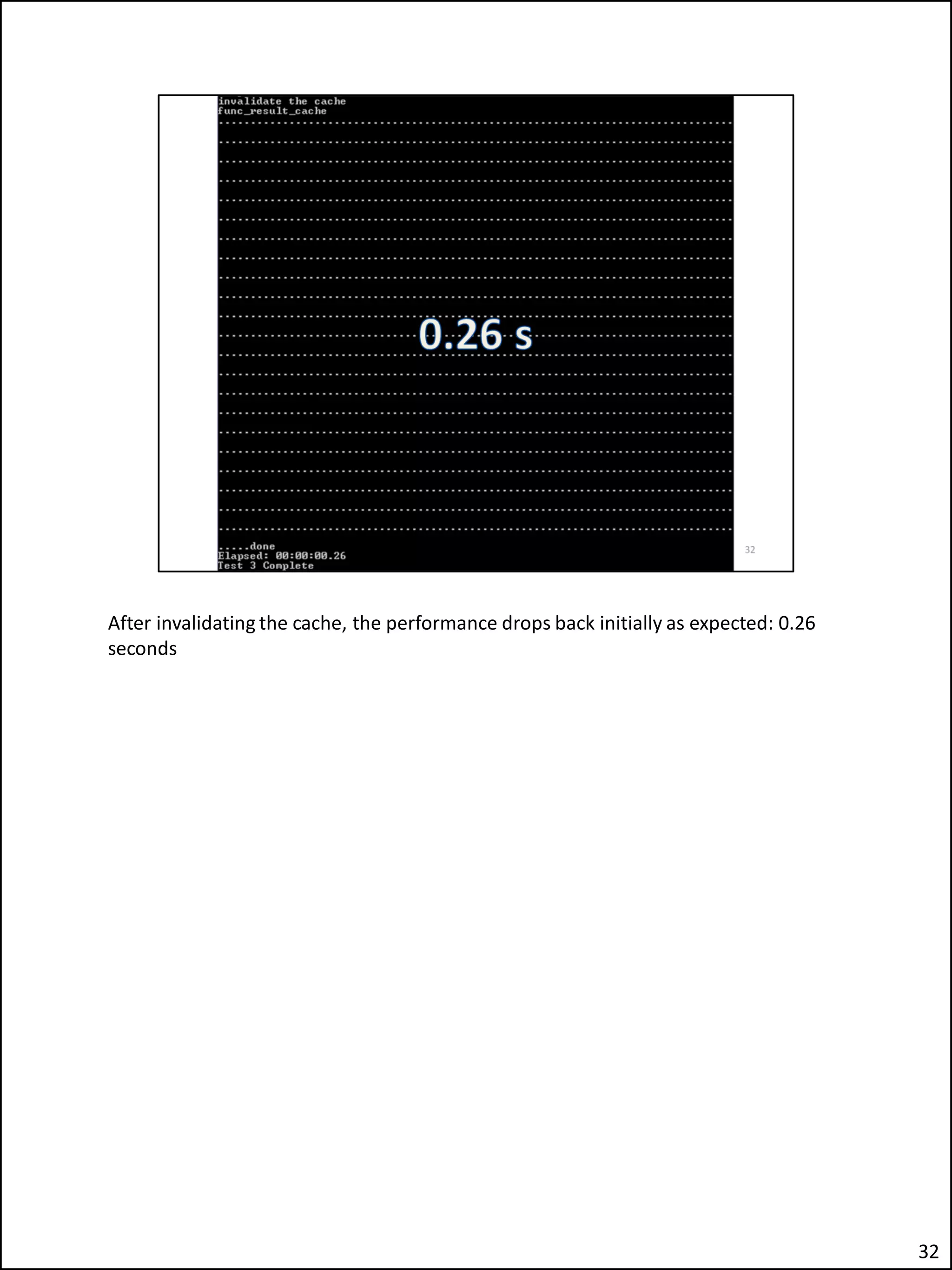
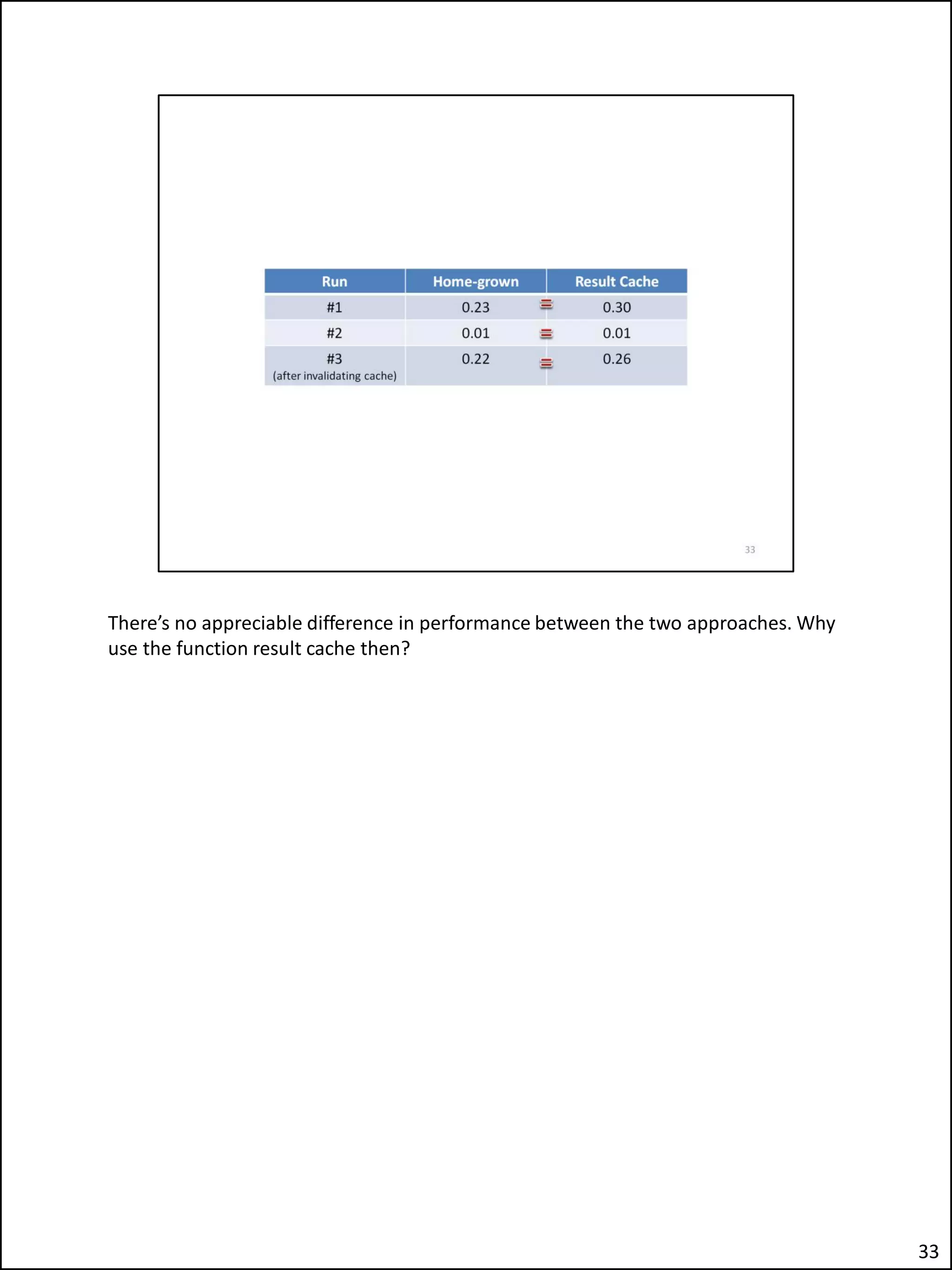



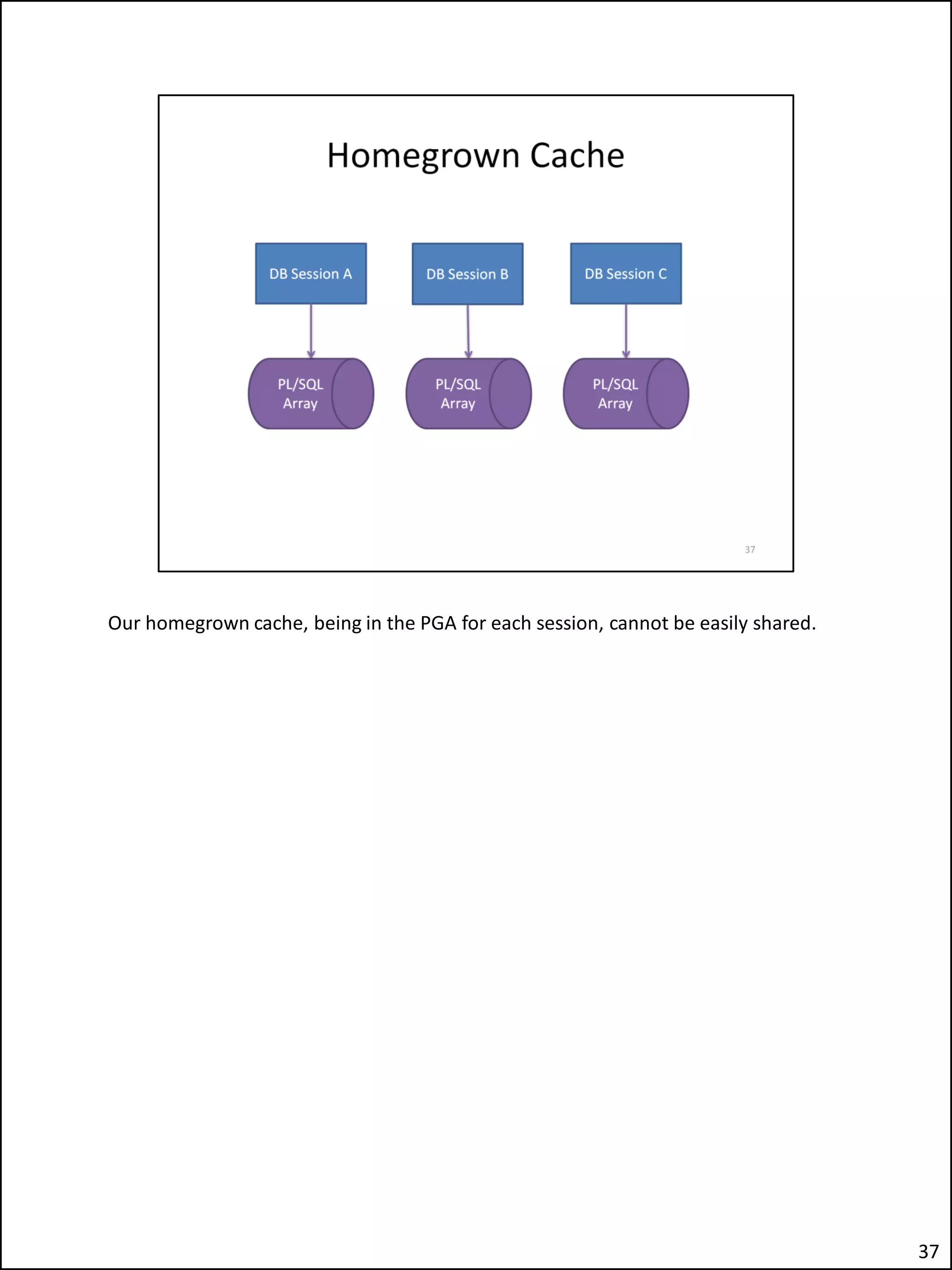




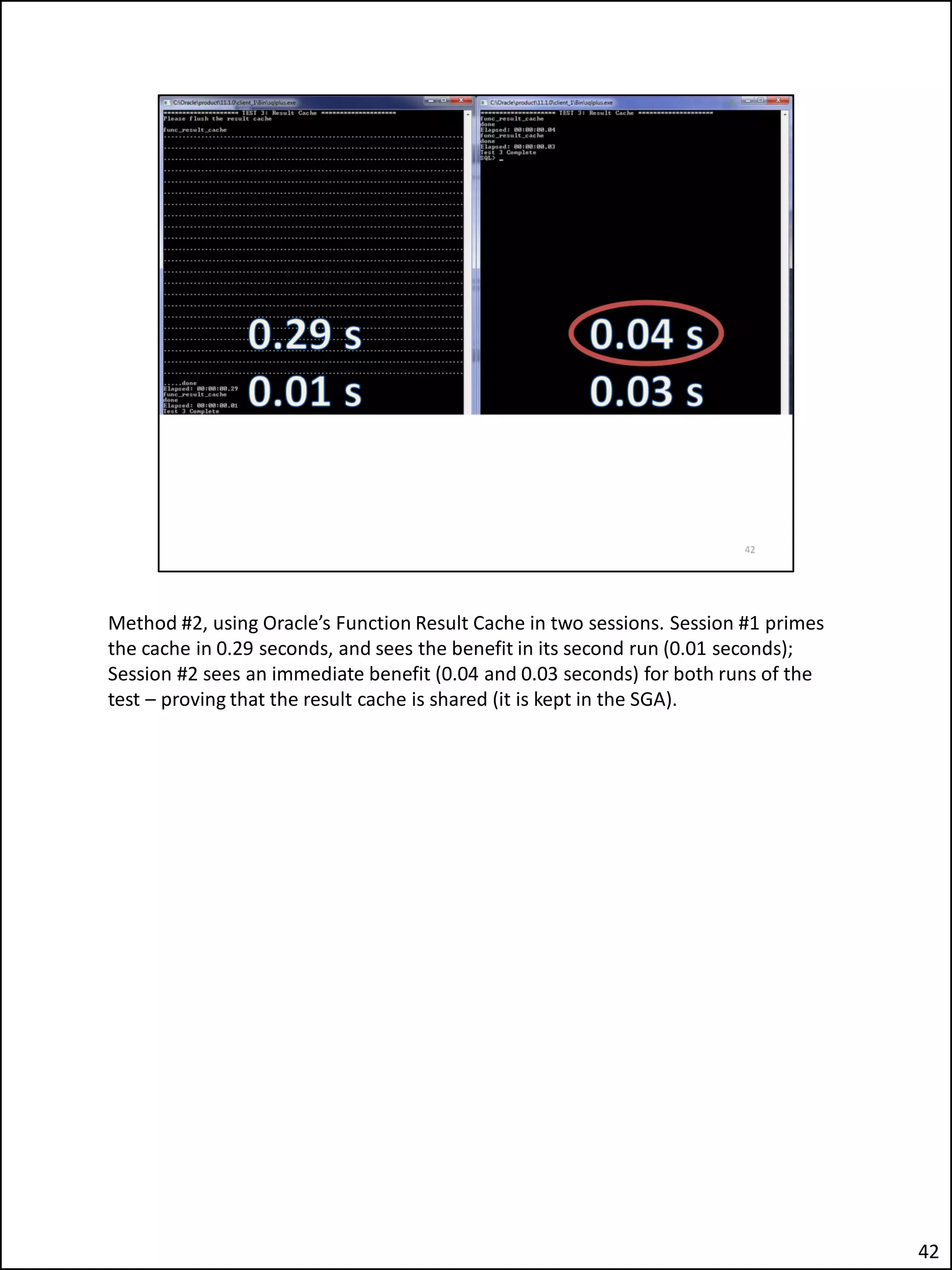
























The document describes an issue the author encountered where an Apex application's security checks seemed to fail intermittently. This allowed unauthorized users to sometimes see tabs and buttons they should not have access to. The author investigated and discovered the cause was the use of the Apex variable APP_USER in the database function checking users' roles. This caused the function result cache to return the wrong value for other users due to session sharing in Apex. The fix was adding a second parameter to the function.





















































