Download as PDF, PPTX









![Intent Classification Techniques
• Preprocessing
• Tokenization (ckiptagger)
• Feature extraction
• Bag of Word (scikit-learn)
Vocabulary
[ “現在”, “台幣”,”美金”, “日圓”,“一
年期”, “定存”,“是”, “多少”]
現在美金一年期定存是多少
Text
現在 美金 一年期 定存 是 多少
Tokens
• Model
• Deep Neural Network
(DNN) (tensorflow)
[ 1 , 0 , 1 , 0 , 1 , 1 ]
Feature vector
Word Count encodingFeature engineering
Model Training](https://image.slidesharecdn.com/pycon-20190919-190920085441/85/slide-13-320.jpg)

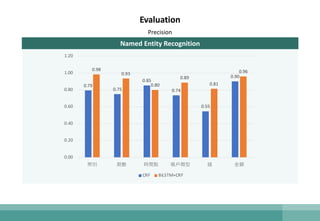
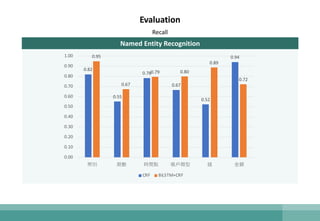
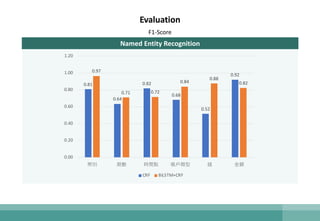

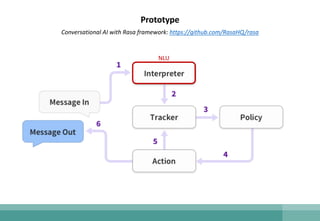
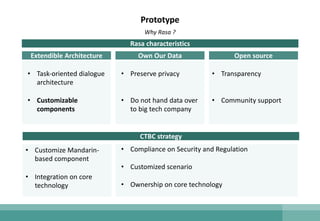
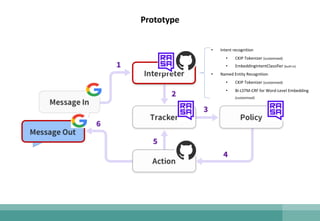






The document outlines the development of a natural language understanding (NLU) engine aimed at enhancing banking scenarios for Mandarin-speaking customers. It details the efforts of the AI group at CTBC Bank, particularly in implementing deep learning techniques for tasks such as intent recognition and named entity extraction, alongside their successful applications in anti-money laundering and fraud avoidance. The conclusions suggest that such NLU systems, utilizing advanced machine learning models, are crucial for building effective task-oriented dialogue systems.















































