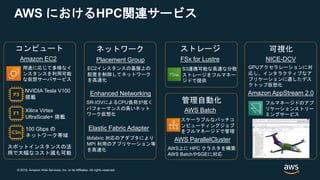
#6 AWS provides a wide breadth of services supporting compute-intensive workloads
[Quickly walk through them]
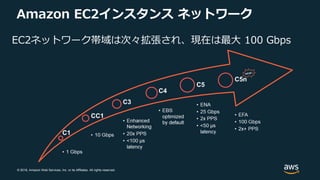
EFA network interface for compute instances
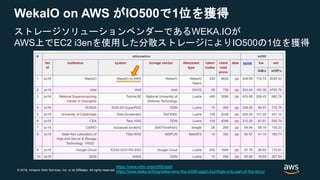
AWSでは、クラウド上でこのようなコンピュートインテンシブワークロードを実現するために、様々なサービスを提供しています。
こちらに一例を示していますが、EC2を主軸に、
最近では
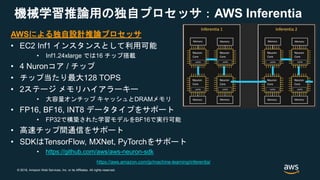
#10 Custom design based on high performance Systolic Array, Vector Engine and Stream processor to orchestrate traffic.
Two stage memory hierarchy with large on-chip cache and commodity DRAM.
Flexible to use with support for multiple data types: int8, FP16 and BF16 MIXED precision. Including FP32 auto-casting.
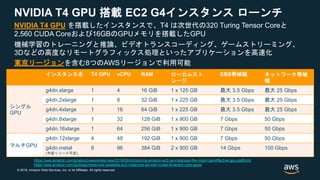
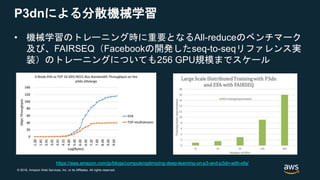
When we designed Inferentia, we wanted it to be powerful, low latency, easy to use, to give our customers choices in how they run Inference workloads in AWS. Powerful: We pushed more than 100 Tera Ops/sec in each one of these chips, at low power, which allowed us to pack up to 16 of them in a single instance to have more than 2 Peta Ops/sec. That’s 2X more than our biggest P3 machines easy to use: Inferentia natively integrate with TF, PT and MXNet, and most, if not all customers don’t need to change their neural network or change the framework they use if it one of the 3 most popular ones. Training wherever you want, ideally on an Ec2 P3/P3dn and bring the models. 2-4 lines of code change and you can use inferentia easy to use 2: another thing our customers told us that they like to keep training in 32-bit floating point - that gives best accuracy. but 32-bit is expensive and high power, and its really hard to move to lower 16-bit floating point or Integers. So Inferentia is the first ML accelerator in AWS cloud that can take a 32-bit trained model and run them at speed of 16-bit using BFloat16 model Latency: many of our customers also challenged us to push latency as low as possible, to allow use of ML with user-facing and interactive applications like voice assistant, or search. And as ML gets more sophisticated, models get bigger, and bigger models end up taking more time load and process adding to latency. Allows to build servers that cascade multiple chips together, and split these big ML inference models across multiple chips. When we spread it across chips, we could cache the models inside our large on-chip memory, and then we dont need to reload the model. For Natural Language Understanding Models like BERT, this would cut the latency by two thirds, while achieving same throughput
As models get more advanced and more accurate, their memory footprint increases, for example, BERT memory footprint is 680MByte. that can't fit into single chip, and almost every chip, inferentia or other will need to load the model from DRAM all the time. With Inferentia-CascadeMode, we are able to build distributed caching of the model across multiple chips so we won't need to access DRAM.
非公開情報?:48MBオンチップキャッシュ、256Gbps chip-to-chip interconnect
#11 他に…
~30 Billionトランジスタ
Dual SIMD units
ML向け命令セット(int8, fp16) *BF16はまだ
No NUMA concerns
1Tbit/s伸張圧縮アクセラレータ内蔵
圧縮15GB/s, 伸張11GB/s
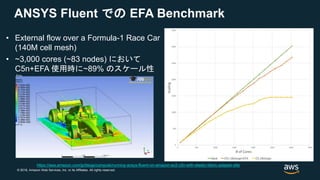
#21 Parallel tightly-coupled computing applications are typically based on MPI. Here is a notional diagram of how mpi applications work today on AWS. This is the “before” chart, without EFA. MPI is a standardized message passing interface. There are a variety of versions of MPI, such as Open MPI and Intel MPI. These two we will be talking about later in the webinar.
MPI is the networking library used by the application to provide point to point communication between the different cores on which an application is running. MPI is the bottom of the user portion of the stack and it talks to the kernel tcp/ip stack. Which is at the top of the kernel stack. The kernel stack then talks to the ENA network driver which communicates with the hardware.
#29 With Amazon FSx for Lustre, you get a fully managed Lustre parallel file system.
Because it’s a Lustre file system, it’s performance is ideal for compute-intensive workloads with high-throughput and low-latency needs, like high performance computing, machine learning workloads, and media processing/rendering workflows.
[Read through icons]
Data repositories: S3 + on-prem data stores
I’ll now talk about each of these in turn.

























![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
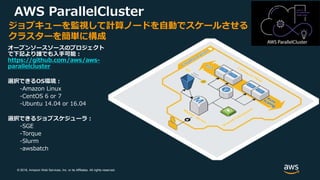
ParallelCluster 設定例
[aws]
aws_region_name = ap-northeast-1
[cluster slurm1]
master_instance_type = c5.large
compute_instance_type = c5.4xlarge
max_queue_size = 10
initial_queue_size = 0
scheduler = slurm
cluster_type = spot
33
configファイル例
https://docs.aws.amazon.com/ja_jp/parallelcluster/latest/ug/configuration.html
pcluster create コマンド実行](https://image.slidesharecdn.com/20191220jawshpcpublic-191223081534/85/JAWS-UG-HPC-17-HPC-on-AWS-2019-32-320.jpg)










![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
re:Invent前に発表されたCompute関連サービス
• 11/5 :C5dインスタンスにCascade Lakeを搭載した新しいインスタンスサイズが追加 [LINK]
• 11/6 :コンピューティング使用料を確約することで割引を提供するSavings Plansを発表 [LINK]
• 11/8 :Amazon EC2がMicrosoft SQL Server 2019をサポート [LINK]
• 11/8 :AWS BatchがM60ならびにT4 GPUを搭載するG3、G3s、G4インスタンスをサポート [LINK]
• 11/15:Elastic Fabric AdapterがIntel MPI 2019 (Update 6) ライブラリをサポート [LINK]
• 11/18:AMD EPYC “Rome” 搭載 c5a/c5adインスタンス [LINK]
• 11/18:ParallelCluster 2.5.0リリース [LINK]
• 11/19:EC2インスタンスメタデータに関するアップデート [LINK]
• 11/22:Amazon EC2のインスタンスタイプ検索機能 [LINK]
• 11/25:バースト可能なEC2インスタンスの一括設定 [LINK]
• 11/26:Elastic Inferenceがリソースタグに対応 [LINK]](https://image.slidesharecdn.com/20191220jawshpcpublic-191223081534/85/JAWS-UG-HPC-17-HPC-on-AWS-2019-46-320.jpg)
![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
最近のスポットインスタンス・起動サービス関連アップデート一
覧• 08/26:Managed Spot training in Amazon SageMaker [LINK]
• 09/27:ECS - Automated Draining for Spot Instances [LINK]
• 10/24:AWS Batch – 新しい配分戦略 [LINK]
• 11/07:Automated Draining for Spot Instance Nodes on Kubernetes [LINK]
• 11/20:EC2 Auto Scaling - Maximum Instance Lifetime [LINK]
• 11/20:EC2 Auto Scaling – Instance Weighting [LINK]
• 11/25:Auto Scaling - Private Linkをサポート [LINK]
• 11/25:Supporting Spot Instances in Elastic Beanstalk [LINK]
• 12/03:ECS - Capacity Providers [LINK]
• 12/03:Fargate Spot [LINK]](https://image.slidesharecdn.com/20191220jawshpcpublic-191223081534/85/JAWS-UG-HPC-17-HPC-on-AWS-2019-47-320.jpg)
















































![[AWSマイスターシリーズ] Amazon Elastic Compute Cloud HPC編](https://cdn.slidesharecdn.com/ss_thumbnails/20130731aws-meister-regenerate-ec2-hpc-public-130811200826-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS re:invent 2013 Report] AWS New EC2 Instance Types](https://cdn.slidesharecdn.com/ss_thumbnails/reportnewinstancetype-131209205331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









