제 9회 BOAZ 빅데이터 컨퍼런스 -트위터 트렌드 분석을 통한 신제품 개발
트위터 트렌드 분석을 통한 신제품 개발
-새로운 맛을 찾아서!
'신제품 개발은 해야겠고.. 아이디어는 안 떠오르고..'
더 이상의 아이디어 회의는 가라, 이젠 SNS에 무엇이든 물어보세요~
키워드별 트위터 데이터 텍스트 마이닝을 통해 다양한 아이디어가!
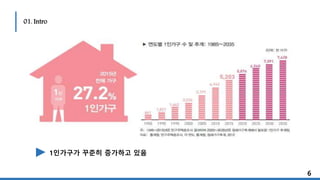
감성 분석을 통해 신제품에 대한 반응 예측까지!
03. 전처리
16
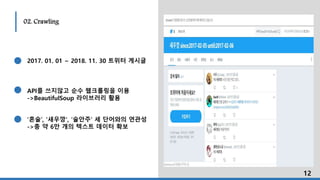
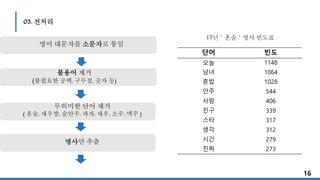
영어 대문자를소문자로 통일
무의미한 단어 제거
( 혼술, 새우깡, 술안주, 과자, 새우, 소주, 맥주 )
불용어 제거
(불필요한 공백, 구두점, 숫자 등)
명사만 추출
단어 빈도
오늘 1148
남녀 1064
혼밥 1028
안주 544
사람 406
친구 339
스타 317
생각 312
시간 279
진짜 273
17년'혼술'명사 빈도표
17.
03. 전처리
17
단어별 빈도표생성
두 글자 이상의 단어만 추출
음식 관련 단어만 추출
최종 빈도표 생성
단어 빈도
치즈 540
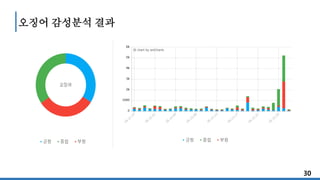
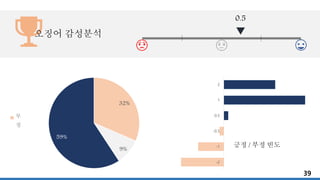
오징어 479
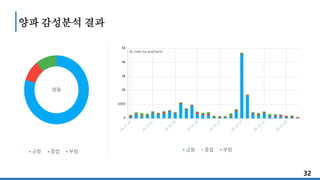
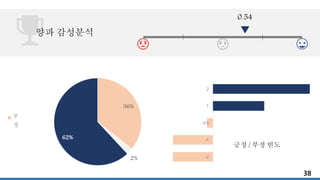
양파 450
치킨 406
땅콩 324
감자 310
튀김 303
김치 279
라면 258
깐풍 224
최종 음식 명사 빈도표
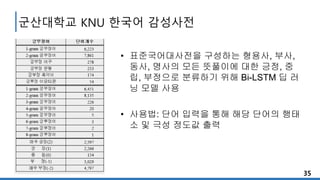
데이터 수집 주관성탐지
:사용자 주관이 드러난 곳만 도려내기 : 사용자의 감성을 좋고 싫고 양 극으로 보내기
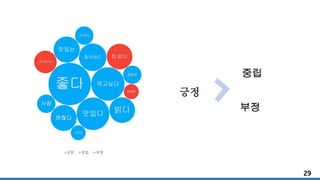
긍정 부정 중립 3가지로 분류
긍정 부정 단어를 정량화
각 단어에 점수 혹은 가중치 부여
전체 텍스트가 어디에 속하는지 분류
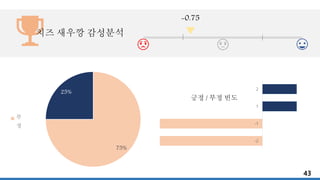
극성 탐지
25
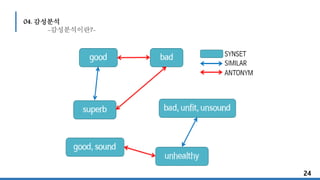
04. 감성분석
-감성분석의 3단계-
#24 예를 들어, 어떤 블로그 또는 문서에 대한 전반적인 동의 여부를 측정하거나 정치인에 대한 유권자들의 태도를 파악하는 데 감성 분석을 이용할 수 있습니다. 감성 데이터는 종종 소셜 미디어 서비스, 그리고 리뷰, 코멘트, 토론 그룹과 같은 SNS와 유사한 사용자 생성 콘텐츠에서 파생됩니다. 따라서 데이터 세트는 '빅 데이터'로 간주될 만큼 대규모로 성장하는 경향이 있습니다.
#36 Bi-LSTM 모델은 각 뜻풀이의 확률 값을 계산하여 최종적으로 300,000개에 달하는 뜻풀이를 긍정, 중립, 부정으로 분류하며, 긍정으로 분류된 뜻풀이 그룹에서 top-2500 긍정어 추출하며, 비슷한 방식으로 top-2500 부정어 추출 (상위 2,500개의 뜻풀이만을 대상으로 긍부정어를 찾는 이유는 2,500개 이상 넘어가면 기추출된 긍부정어들이 반복적으로 추출되기 때문)
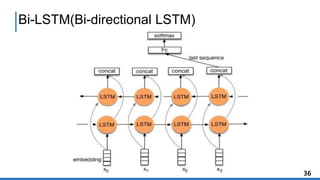
#37 LSTM은 RNN(Recurrent Neural Network)에서 발생하는
길이가 길어질수록 역전파(Back-propagation) 시 기울기
(Gradient) 값이 줄어들어 학습 능력이 떨어지는 것을
보완한 모델이다. Bi-LSTM은 순차적 데이터에서 좋은 성
능을 보이며 입력된 데이터에 대해 양방향으로 학습이
가능한 딥러닝 기법이다. 본 논문에서는 수작업과 감성
사전으로 분류한 데이터를 학습시키기 위해 양방향으로
입력 정보를 받을 수 있는 Bi-LSTM 모델을 사용하였다.
http://dilab.kunsan.ac.kr/pub/hclt18c.pdf




















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [토이스토리] : Wispy](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250803064626-64a49e3a-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [청진스] : Multi-Label Lung Sound Classification ba...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124724-469662d6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [직행복] : 실시간 로그 처리 기반 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801124036-52794fc9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [영웅호걸] : Context-Aware Real-time Sentiment based ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801123333-f123549e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중증외상센터] : 24시간 심전도 Holter 데이터 기반의 소아 PSVT 예측 모델 개발](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801122720-74dafab0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [아라보아즈] : 아라보아의 장기적 성장을 위한 DDDM 환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801031027-23699371-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [소크라데이터스] : 웨어러블 기기를 활용한 생체 신호 기반 감정 데이터 수집 및 감정 ...](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801030109-344e2af9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [땡큐쏘아마취] : 소마챗 : Agentic RAG 기반 소아마취 업무지원 챗봇](https://cdn.slidesharecdn.com/ss_thumbnails/25-1-250801025055-4240eed3-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 22회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SNOMED] : LangGraph 기반 OMOP CDM 매핑 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/25-1snomed-250801024253-89455097-thumbnail.jpg?width=640&height=640&fit=bounds)