More Related Content

PDF
ملزمة الرياضيات لشيخ الرياضيات - كامل موسى الناصري ![[ShaderX5] 4.4 Edge Masking and Per-Texel Depth Extent Propagation �For Compu...](https://cdn.slidesharecdn.com/ss_thumbnails/shaderx5-44-090608100020-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[ShaderX5] 4.4 Edge Masking and Per-Texel Depth Extent Propagation �For Compu... 
PDF

PDF
Gaztea Tech 2015: 4. GT Drawbot Control 
PDF
Cours de C++, en français, 2002 - Cours 1.3 
PDF
Comprendre la programmation fonctionnelle, Blend Web Mix le 02/11/2016 
PDF
Menguak Misteri Module Bundler 
PDF
More from Syoyo Fujita

PDF

KEY
DIY InfiniBand networking 
ZIP
MicroServer + InfiniBand + ZFS 
PDF

PDF

PDF
Docker + GCE + etcd + ray tracing 
PDF
Vertex Culling illustration at SBR07 
PDF

PDF

PDF
MUDA
- 1.
MUDA
Syoyo Fujita
twitter.com/syoyo
LT
2010/01/31
- 4.
- 5.
- 6.
HPU
• HPU =
• High-perfoemance Processing Unit
• Heterogeneous Processing Unit
• , GPGPU
• ,
•
• .
- 10.
• ...
• (SSE/AVX, etc)
•
• ->
- 11.
• HPU
• C/C++
• SIMD
• CUDA
• GPU (3.0 CUDA C -> LLVM(plang)
CPU )
• OpenCL
• ?
• .
- 12.
- 13.
MUDA
•
• CUDA, OpenCL, SSE/AVX, LLVM IR, etc.
•
• Windows, Linux, Mac, iPhone(ARM)
• , ISA
• DSL
- 14.
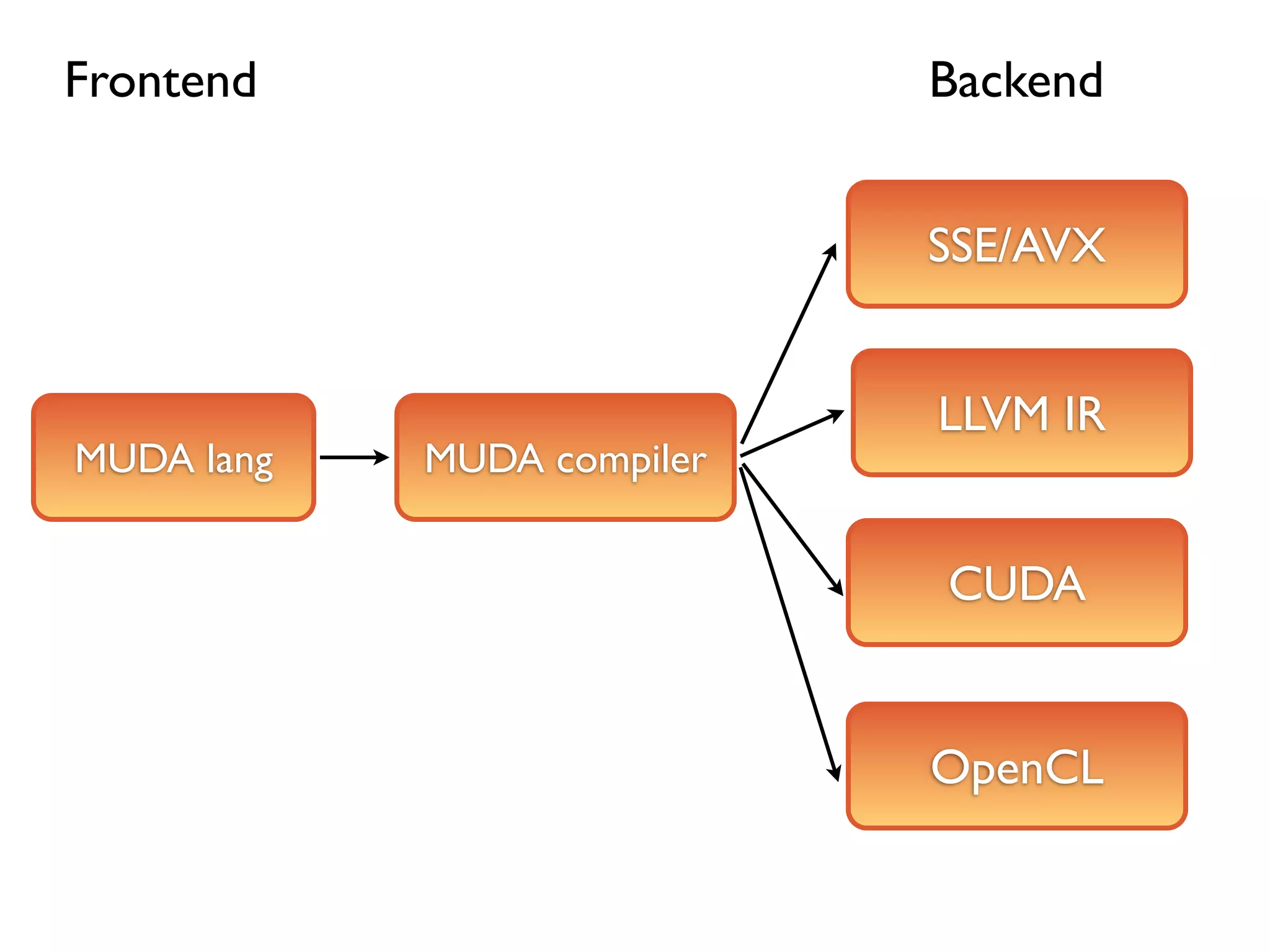
Frontend Backend
SSE/AVX
LLVM IR
MUDA lang MUDA compiler
CUDA
OpenCL
- 15.
void BlackScholesMUDA(
out vec retCall,
out vec retPut,
vec S, // Stock price
vec X, // Option strike
vec T, // Option years
vec R, // Riskfree rate
vec V) // Volatility rate
{
vec sqrtT = sqrt(T);
vec d1 = (log(S /. X) + (R + 0.5f * V * V) * T) /. (V * sqrtT);
vec d2 = d1 - V * sqrtT;
vec cnd_d1 = cndMUDA(d1);
vec cnd_d2 = cndMUDA(d2);
vec expRT = exp(-1.0f * R * T);
retCall = S * cnd_d1 - X * expRT * cnd_d2;
retPut = X * expRT * (1.0f - cnd_d2) - S * (1.0f - cnd_d1);
}
- 16.
void BlackScholesMUDA (float* retCall, float * retPut, const float * S,
const float * X, const float * T, const float * R, const float * V)
{
const __m128 S_ld_1 = _mm_loadu_ps(S + 0) ;
const __m128 X_ld_1 = _mm_loadu_ps(X + 0) ;
const __m128 T_ld_1 = _mm_loadu_ps(T + 0) ;
const __m128 R_ld_1 = _mm_loadu_ps(R + 0) ;
const __m128 V_ld_1 = _mm_loadu_ps(V + 0) ;
const __m128 t_vec78_1 = T_ld_1 ;
const __m128 t_vec77_1 = sqrtmu( (float *) &( t_vec78_1) ) ;
__m128 sqrtT_1 = t_vec77_1 ;
const __m128 t_vec79_1 = S_ld_1 ;
const __m128 t_vec80_1 = X_ld_1 ;
const __m128 Vect_vec80_rcp = _mm_rcp_ps( t_vec80_1) ;
...
- 17.
void
isect(dvec rox, dvecroy, dvec roz,
dvec rdx, dvec rdy, dvec rdz,
dvec v0x, dvec v0y, dvec v0z,
dvec e1x, dvec e1y, dvec e1z,
dvec e2x, dvec e2y, dvec e2z,
out dvec inoutMask,
out dvec inoutT,
out dvec inoutU,
out dvec inoutV)
{
dvec px, py, pz;
// p = d x e2
px = cross4(e2z, e2y, rdy, rdz);
py = cross4(e2x, e2z, rdz, rdx);
pz = cross4(e2y, e2x, rdx, rdy);
...
- 18.
MUDA_STATIC MUDA_INLINE __m256dcross4 (const double * a, const double *
b, const double * c, const double * d)
{
const __m256d a_ld_1 = _mm256_load_pd(a + 0) ;
const __m256d b_ld_1 = _mm256_load_pd(b + 0) ;
const __m256d c_ld_1 = _mm256_load_pd(c + 0) ;
const __m256d d_ld_1 = _mm256_load_pd(d + 0) ;
const __m256d t_dvec2_1 = a_ld_1 ;
const __m256d t_dvec1_1 = c_ld_1 ;
const __m256d t_dvec3_1 = _mm256_mul_pd(t_dvec2_1, t_dvec1_1) ;
const __m256d t_dvec4_1 = b_ld_1 ;
const __m256d t_dvec5_1 = d_ld_1 ;
const __m256d t_dvec6_1 = _mm256_mul_pd(t_dvec4_1, t_dvec5_1) ;
const __m256d t_dvec7_1 = _mm256_sub_pd(t_dvec3_1, t_dvec6_1) ;
return t_dvec7_1 ;
}
...
- 19.
define internal <4xdouble>@cross4 (<4xdouble> %a, <4xdouble> %b,
<4xdouble> %c
, <4xdouble> %d)
{
%a.addr = alloca <4xdouble> ;
store <4xdouble> %a, <4xdouble>* %a.addr ;
%b.addr = alloca <4xdouble> ;
store <4xdouble> %b, <4xdouble>* %b.addr ;
%c.addr = alloca <4xdouble> ;
store <4xdouble> %c, <4xdouble>* %c.addr ;
%d.addr = alloca <4xdouble> ;
store <4xdouble> %d, <4xdouble>* %d.addr ;
%t_dvec2 = load <4xdouble>* %a.addr ;
%t_dvec1 = load <4xdouble>* %c.addr ;
%t_dvec3 = mul <4xdouble> %t_dvec2 , %t_dvec1 ;
%t_dvec4 = load <4xdouble>* %b.addr ;
%t_dvec5 = load <4xdouble>* %d.addr ;
...
- 20.
MUDA runtime API
classMUDADevice
{
public:
MUDADevice(MUDADeviceTarget target);
~MUDADevice();
bool initialize();
int getNumDevices();
bool loadKernelSource(const char *filename, const char **headers,
const char *options);
MUDAKernel createKernel(const char *functionName);
MUDAMemory alloc(MUDAMemoryType memType, MUDAMemoryAttrib memAttrib,
size_t memSize);
bool write(int ID, MUDAMemory mem, size_t size, const void *ptr);
bool read(int deviceID, MUDAMemory mem, size_t size, void *ptr);
bool bindMemoryObject(MUDAKernel kernel, int argNum, MUDAMemory mem);
bool execute(int deviceID, MUDAKernel kernel, int dimension,
size_t sizeX,
size_t sizeY,
size_t sizeZ);
- 21.
- 22.
MUDA BlackScholes
• [Perf] CPU = 48.667000 (msec)
MUDA CPU
• 16.438244 MOps/sec
40
• [Perf] MUDA = 21.705400 (msec)
30
• 36.857188 MOps/sec
20
10
Better
0
2.16GHz C2D
- 23.
- 24.
OpenSource
• http://lucille.sourceforge.net/muda/
• MUDA .
• Haskell !
• MUDA (CUDA, OCL backend)
•
- 25.
•
•
• ISA,
• .. ... .. .....
• DSL !
- 26.
- 27.
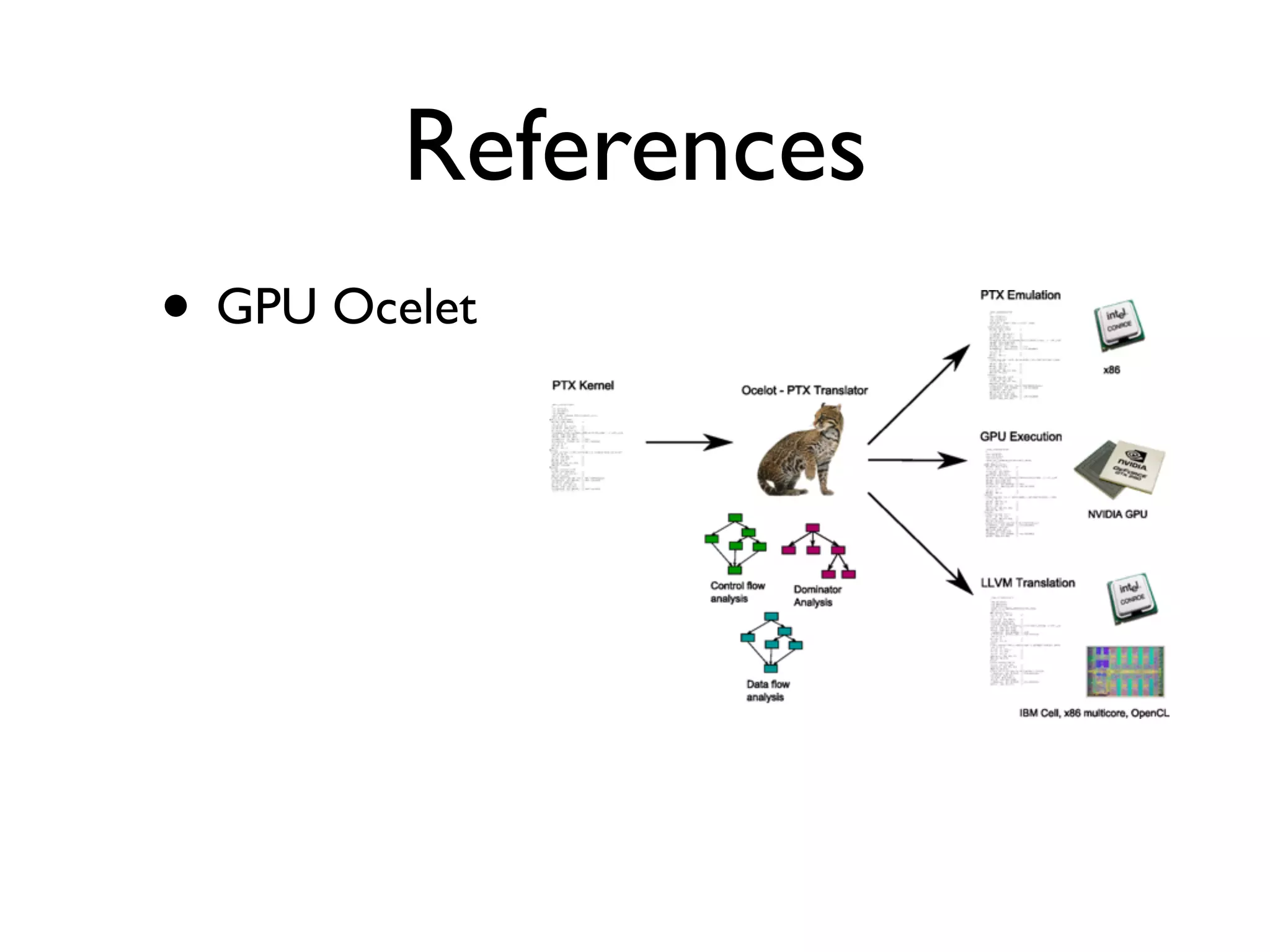
• MCUDA
•CUDA kernel CPU(x86)
.
• http://impact.crhc.illinois.edu/mcuda.php




















![MUDA BlackScholes
• [Perf] CPU = 48.667000 (msec)
MUDA CPU
• 16.438244 MOps/sec
40
• [Perf] MUDA = 21.705400 (msec)
30
• 36.857188 MOps/sec
20
10
Better
0
2.16GHz C2D](https://image.slidesharecdn.com/muda-100211080159-phpapp01/75/MUDA-22-2048.jpg)