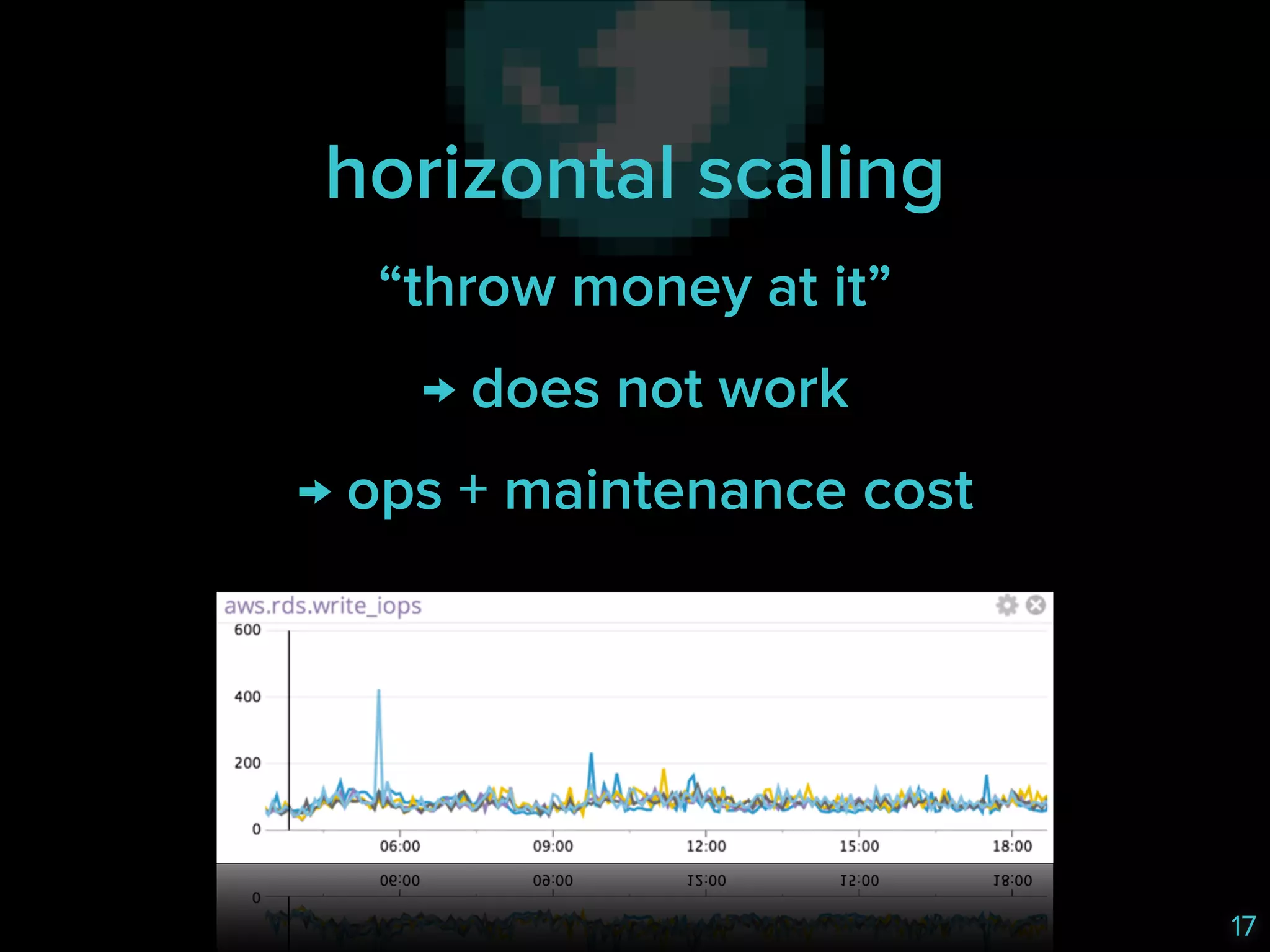
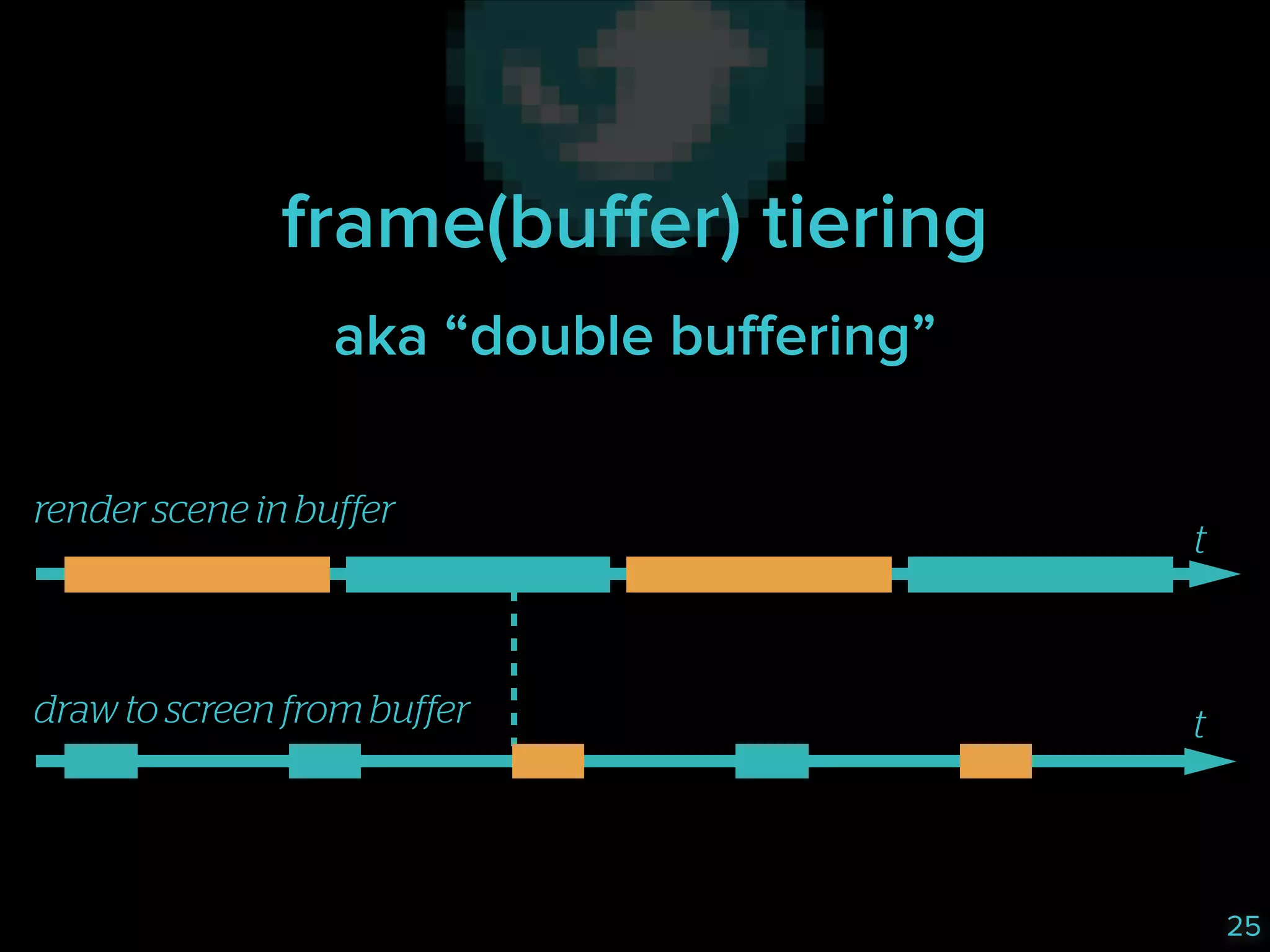
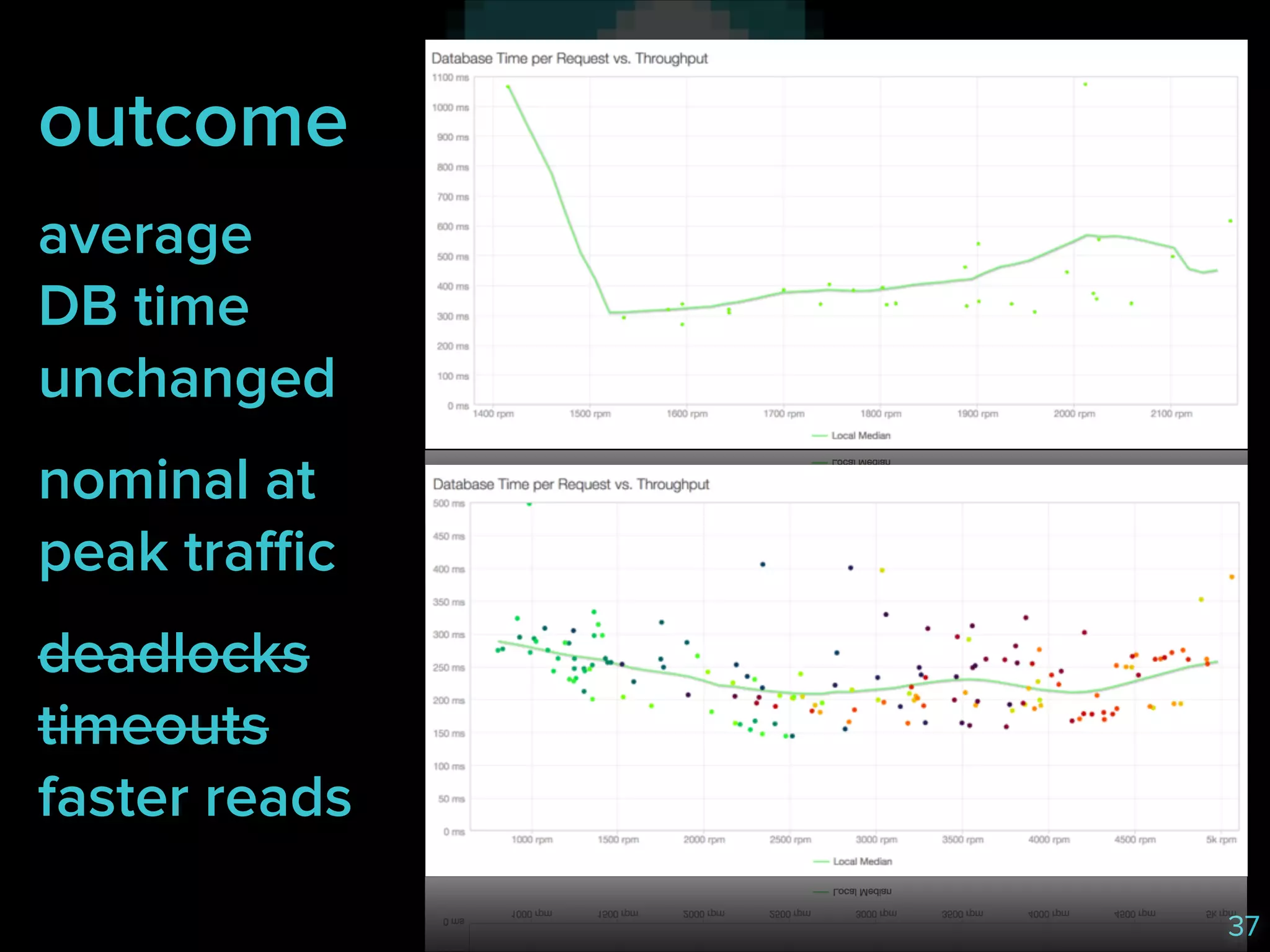
The document discusses the challenges faced by a database system, specifically focusing on data tiering in MySQL under high traffic conditions. It outlines issues like slow reads and writes due to contention and inefficiencies, while exploring potential solutions such as horizontal and vertical scaling, fine-tuning, and implementing a service for separating read and write operations. The outcome of these strategies resulted in improved performance during peak traffic without significant changes to average database time.


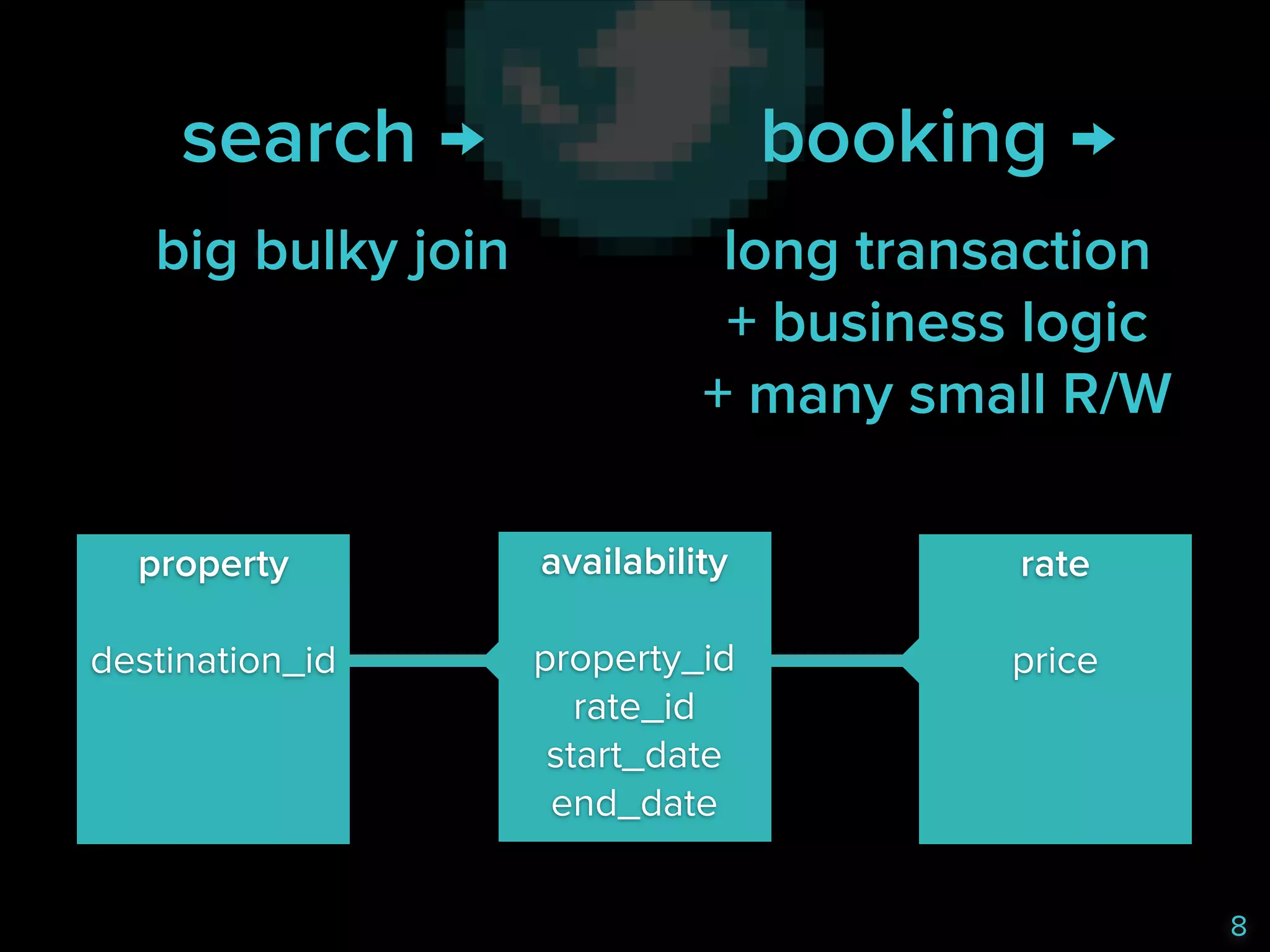
![search =
[destination, start date, end date]
↓
[ [property, price], … ]
property
availability
rate
!
!
!
destination_id
property_id
rate_id
start_date
end_date
price
7](https://image.slidesharecdn.com/2014-01-08datatiering-140113154512-phpapp01/75/Data-Tiering-Squeezing-Scale-out-of-MySQL-LRUG-Presentation-2014-01-13-6-2048.jpg)



















![syncing: schema
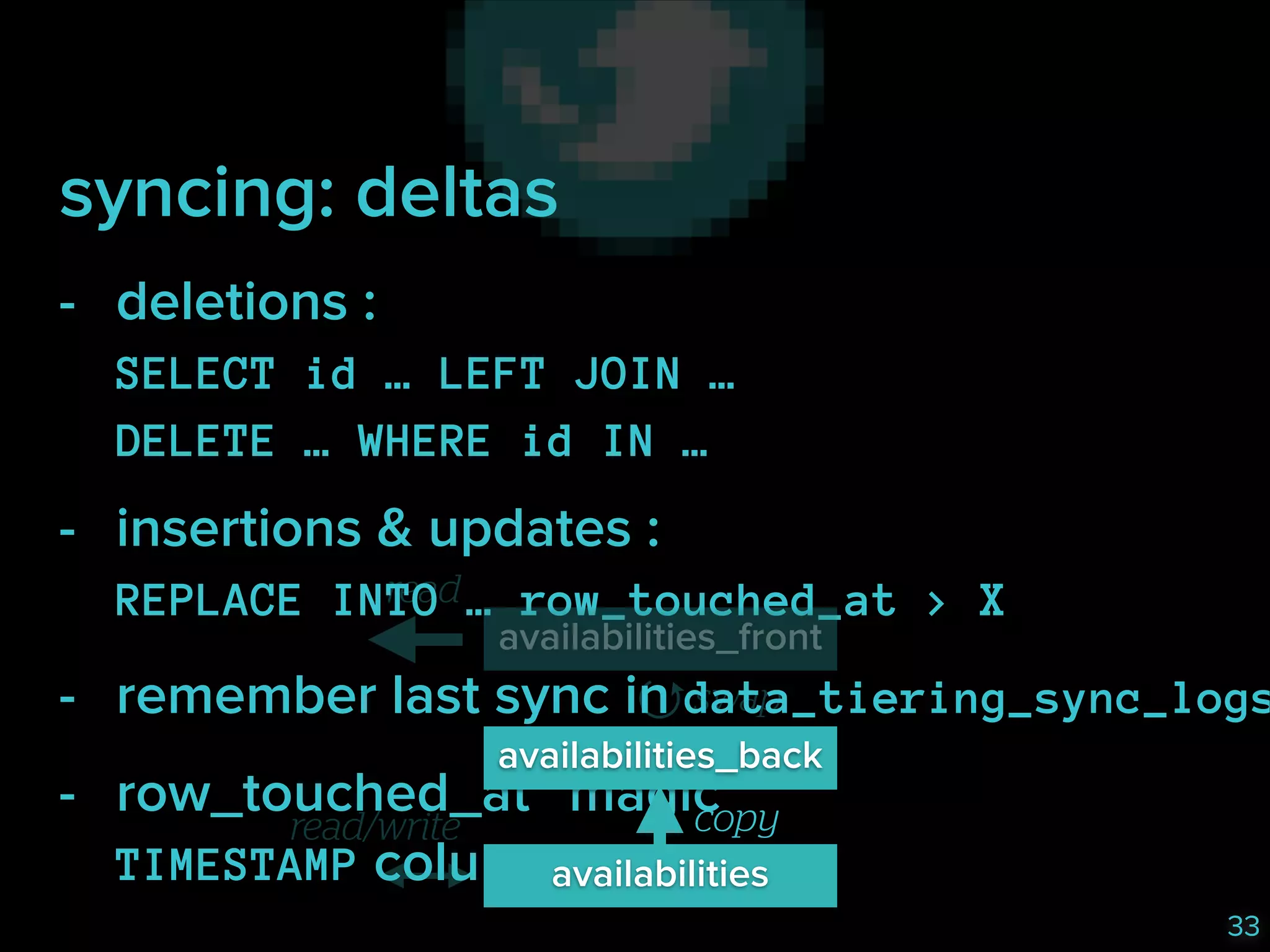
lazily (no migrations) :
- create missing /.*_[01]/ tables
- compare schemas with
SHOW CREATE TABLE
read
availabilities_front
swap
availabilities_back
read/write
copy
availabilities
31](https://image.slidesharecdn.com/2014-01-08datatiering-140113154512-phpapp01/75/Data-Tiering-Squeezing-Scale-out-of-MySQL-LRUG-Presentation-2014-01-13-30-2048.jpg)






















![[db tech showcase Tokyo 2017] A11: SQLite - The most used yet least appreciat...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-keynote-20170905-170911071000-thumbnail.jpg?width=640&height=640&fit=bounds)


















































