

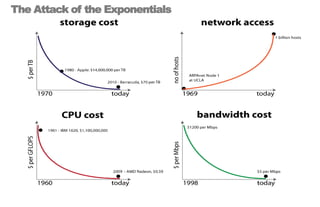

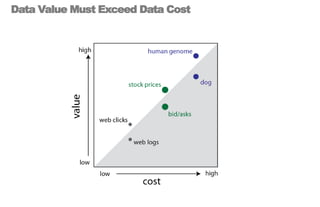
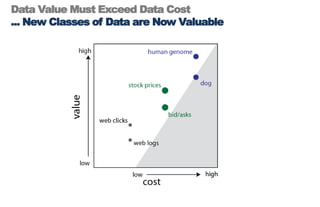
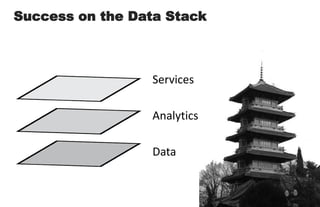
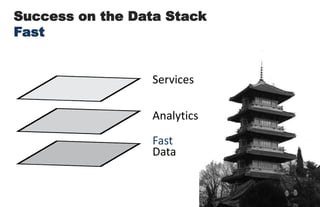
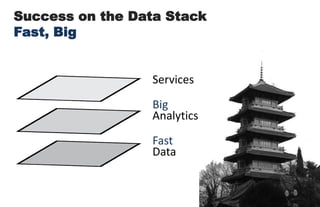
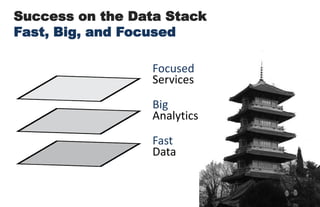



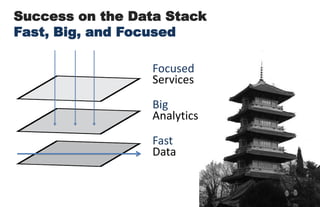


====================================================== 1. Building Data Start-ups: Fast, Big, and Focused ====================================================== * 2 parts today: (i) forces behind big data opportunity (ii) big data stack and how to compete with in * building a data start-up is a bit like Sumo Wrestling * data is heavy, has weight - we need agile strategies to succeed * today: talk about opportunities for data, strategies for success * in a nutshell: data start-ups must be fast, big, and focused ================================================ 2. The Big Data Opportunity ================================================ * it's a cliche by now: there is a mountain of data in this world * understanding these forces is critical to data start-up's strategy <transition>: what are some of the tectonic forces at work? ================================================ 3-4. Attack of the Exponentials ================================================ * these are something that i call 'attack of exponentials' * VCs like curves like [transition] * in the past few decades, the cost of storage, CPU, and bandwidth has been exponentially dropping, while network access has shot up * in 1980, a terabyte of storage cost $14 MILLION - today it's $47 dollars <transition>: exponential economics, together with two other forces ================================================ 5. Intersection of Three Forces ================================================ * ... form the inputs to this massive increase in data, the data singularity * sensor networks the phones, GPS devices, laptops, and instrumented spimes * cloud computing has democratized and made computing power & storage a utility ( "even if it turns out that the cloud is actually just some place in Virginia.") ================================================ 6-7. Data Value Must Exceed Data Cost ================================================ * the laws of economics have not changed: value must exceed cost * the upper left side of this graph shows data whose value exceeded its cost of collecting, storing, and computing over a decade ago * the human genome data cost $3 billion (in 2000) [shift slide] * but as the tide shifts, new classes of data are revealed as being valuable * the dog genome cost only $30 million (in 2005) * web log data used to be tossed; now it's cheap enough to collect, store, and compute over * i encourage all of you, think of a data source that was previously not collected, or not kept around, and mull the possibilities <transition>: with that, i would like to now talk about the emerging stack, and the strategies for being successful within it ================================================ 8-9, 10-11. Success on the Data Stack ================================================ * here is my vision of the emerging big data stack * at bottom is data - persistence layer - databases - the brawn * in the middle is analytics - the intelligence layer * at the top - services, what you all the brains and brawn [ transitions in quite succession ] * I argue that data start-ups, to succeed, must have == FAST data, BIG analytics, and FOCUSED services == * let's take each of these in turn, exploring the competitive axes at each layer starting from the bottom of the stack, data ================================================ 12. FAST ================================================ * as I said before, data is heavy * being able to move big data quickly is key * let's pull the data layer out of the stack & examine it ================================================ 13. Fast Data ================================================ * so we have the two competitive axes on the data layer * the first axis is scale: for data, the scaling issue has been solved. * Hadoop
![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





