Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
学 松崎
3,932 views
MySQL Casual Talks LT 20120627
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
Spring Boot + Doma + AngularJSで作るERP 〜JavaQneバージョン〜 #jqfk
by
学 松崎
PDF
Spring Boot + Doma + AngularJSで作るERP (LINE Fukuoka Meetup版)
by
学 松崎
PDF
Fukuokaphp vol12 talk_20140225
by
学 松崎
PDF
福岡Ruby会議01 20121201 LT
by
学 松崎
PDF
fukinfra Vol3 LT 20120629
by
学 松崎
PDF
クラウド・SaaS型 統合基幹業務システム 「CAM MACS」を支える PostgreSQL ~雲に乗ったゾウ~
by
学 松崎
PDF
OSC福岡2012 LT 20121208
by
学 松崎
PDF
MySQL Casual Talks in Fukuoka vol.2
by
学 松崎
Spring Boot + Doma + AngularJSで作るERP 〜JavaQneバージョン〜 #jqfk
by
学 松崎
Spring Boot + Doma + AngularJSで作るERP (LINE Fukuoka Meetup版)
by
学 松崎
Fukuokaphp vol12 talk_20140225
by
学 松崎
福岡Ruby会議01 20121201 LT
by
学 松崎
fukinfra Vol3 LT 20120629
by
学 松崎
クラウド・SaaS型 統合基幹業務システム 「CAM MACS」を支える PostgreSQL ~雲に乗ったゾウ~
by
学 松崎
OSC福岡2012 LT 20121208
by
学 松崎
MySQL Casual Talks in Fukuoka vol.2
by
学 松崎
Featured
PDF
2024 Trend Updates: What Really Works In SEO & Content Marketing
by
Search Engine Journal
PDF
Artificial Intelligence, Data and Competition – SCHREPEL – June 2024 OECD dis...
by
OECD Directorate for Financial and Enterprise Affairs
PDF
Storytelling For The Web: Integrate Storytelling in your Design Process
by
Chiara Aliotta
PDF
ChatGPT and the Future of Work - Clark Boyd
by
Clark Boyd
PDF
How Race, Age and Gender Shape Attitudes Towards Mental Health
by
ThinkNow
PDF
5 Public speaking tips from TED - Visualized summary
by
SpeakerHub
PPTX
How to Prepare For a Successful Job Search for 2024
by
Albert Qian
PDF
Social Media Marketing Trends 2024 // The Global Indie Insights
by
Kurio // The Social Media Age(ncy)
PDF
Product Design Trends in 2024 | Teenage Engineerings
by
Pixeldarts
PDF
Everything You Need To Know About ChatGPT
by
Expeed Software
PDF
PEPSICO Presentation to CAGNY Conference Feb 2024
by
Neil Kimberley
PDF
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...
by
SocialHRCamp
PDF
AI Trends in Creative Operations 2024 by Artwork Flow.pdf
by
marketingartwork
PDF
Google's Just Not That Into You: Understanding Core Updates & Search Intent
by
Lily Ray
PDF
Trends In Paid Search: Navigating The Digital Landscape In 2024
by
Search Engine Journal
PDF
2024 State of Marketing Report – by Hubspot
by
Marius Sescu
PDF
Skeleton Culture Code
by
Skeleton Technologies
PDF
How to have difficult conversations
by
Rajiv Jayarajah, MAppComm, ACC
PDF
Content Methodology: A Best Practices Report (Webinar)
by
contently
PDF
Getting into the tech field. what next
by
Tessa Mero
2024 Trend Updates: What Really Works In SEO & Content Marketing
by
Search Engine Journal
Artificial Intelligence, Data and Competition – SCHREPEL – June 2024 OECD dis...
by
OECD Directorate for Financial and Enterprise Affairs
Storytelling For The Web: Integrate Storytelling in your Design Process
by
Chiara Aliotta
ChatGPT and the Future of Work - Clark Boyd
by
Clark Boyd
How Race, Age and Gender Shape Attitudes Towards Mental Health
by
ThinkNow
5 Public speaking tips from TED - Visualized summary
by
SpeakerHub
How to Prepare For a Successful Job Search for 2024
by
Albert Qian
Social Media Marketing Trends 2024 // The Global Indie Insights
by
Kurio // The Social Media Age(ncy)
Product Design Trends in 2024 | Teenage Engineerings
by
Pixeldarts
Everything You Need To Know About ChatGPT
by
Expeed Software
PEPSICO Presentation to CAGNY Conference Feb 2024
by
Neil Kimberley
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...
by
SocialHRCamp
AI Trends in Creative Operations 2024 by Artwork Flow.pdf
by
marketingartwork
Google's Just Not That Into You: Understanding Core Updates & Search Intent
by
Lily Ray
Trends In Paid Search: Navigating The Digital Landscape In 2024
by
Search Engine Journal
2024 State of Marketing Report – by Hubspot
by
Marius Sescu
Skeleton Culture Code
by
Skeleton Technologies
How to have difficult conversations
by
Rajiv Jayarajah, MAppComm, ACC
Content Methodology: A Best Practices Report (Webinar)
by
contently
Getting into the tech field. what next
by
Tessa Mero
MySQL Casual Talks LT 20120627
1.
BKA JOINについて
MySQL Casual Talks @gumi福岡 2012/06/27
2.
自己紹介 名前: 松崎 学 所属:
株式会社キャム (SaaS型の経営管理システムを提供中) http://www.cam-net.co.jp/ Twitter: matsumana 最近のお仕事:Javaプログラマ(Rubyもほんの少し)、 インフラ 最近の興味: Scala, Ruby, Python, Play, Node.js, AWS, Hadoop, Asakusa Framework, MongoDB, Fluentd, Vyatta
3.
データベースと私 Oracle歴 14年 (7.1∼ on
Windows , Solaris, Linux) PostgreSQL歴 1.5年 (9.0∼ on Linux) MySQL歴 1ヶ月程 (今回のLTをきっかけに勉強を始めました)
4.
初学者ですが、 よろしくお願いします m(_ _)m http://www.flickr.com/photos/dapperscoo/166797625/
5.
JOINアルゴリズムあれこれ
SQL実行計画に出てくるアレです 片方のテーブルを外部表(駆動表)とし、 もう片方のテーブルをループで回してJOINする。 Nested Loop JOIN (要するに2重ループ) 外側のループ=外部表 内側のループ=内部表 まず、両方のテーブルをJOIN項目でソートして、 Merge JOIN 先頭から順次読み込んでJOINする。 まず、JOIN項目でHashテーブルを作成し、 Hash JOIN そのHashテーブルを元にJOINする。
6.
MySQLにはNested Loop Join しかない。 ※だから遅いという事では決してありません。 クエリ次第だと思います。
7.
しかし、 Block Nested
Loop Join が実装されているので、 特定の条件を満たせば、 内部表のループ回数が大幅に 減少する。
8.
MySQL 5.1 リファレンスマニュアル
抜粋 http://dev.mysql.com/doc/refman/5.1-olh/ja/nested- loop-joins.html ブロック入れ子ループ join アルゴリズム ブロック入れ子ループ (BNL、Block Nested-Loop) join アルゴリズム は、外側のループで読み取った行のバッファリングを使用して、内側 のループで必要となるテーブルの読み取り回数を減らします。たとえ ば、バッファーに 10 行を読み込み、このバッファーを次の内側ルー プに渡すと、内側ループで読み取る各行をバッファー内の 10 行すべ てと比較できます。これにより、内側のテーブルを読み取る必要のあ る回数が大幅に減少します。
9.
新しいJOINアルゴリズム登場! Batched Key
Access JOIN (BKA JOIN) 5.6.3 m6から利用可能。 5.6は2011/04にリリースされた、 まだDevelopment Releaseなバージョンです。 ※今日時点の最新は 「5.6.5 m8」
10.
BKA JOINとは? http://nippondanji.blogspot.jp/2011/10/ mysqlmysql-563-m6.html BKA JOINは変形NLJ(Nested
Loop JOIN)とも言うべきもので、内部表からのレコー ドのフェッチをひとつずつではなくまとめて行う。先に駆動表から結合するキーの 値をいくつかピックアップし、それを内部表に対してまとめて渡す。(Index Condition Pushdownする。)すると、内部表ではMRR(Multi Range Read)最適化に よってアクセスがソートされ、必要なレコードを最適な順序でフェッチすることに なり、JOINが高速化するというわけだ。 InnoDBやMyISAMでは、MRRによる高速化が見込めるのははセカンダリインデックス によるアクセス時だけである。(主キーでアクセスする場合には別段変わらな い。)従って内部表のセカンダリインデックスを使って結合する場合には高速化が 見込めるだろう。BKAが使われているかどうかは、EXPLAINでExtraフィールドを見れ ば分かる。
11.
http://nippondanji.blogspot.jp/2011/04/mysql-56.html
ICP (Index Condition Pushdown) これまでストレージエンジンからフェッチしたレコードをMySQLが 評価してWHERE句の条件による絞り込みを行っていたが、インデッ クスが貼られたカラムを用いた評価については、ストレージエンジン へ条件式を渡し(プッシュダウンし)、ストレージエンジン側で評価 を行わせることによってオーバーヘッドの低減をはかる。 MRR (Multi Range Read) セカンダリインデックスの条件に合致するレコードを複数フェッチす る場合、レコードはセカンダリインデックスとは無関係に並んでいる ため、多くのランダムI/Oが発生する。先にセカンダリインデックス のキーだけを読み取って、主キーの順にソートしてからレコードを フェッチすることにより、ランダムディスクI/Oの低減を期待できる。
12.
MySQL 5.6 Reference
Manual Batched Key Access Joins http://dev.mysql.com/doc/refman/5.6/en/bka- optimization.html Index Condition Pushdown Optimization http://dev.mysql.com/doc/refman/5.6/en/index- condition-pushdown-optimization.html Multi-Range Read Optimization http://dev.mysql.com/doc/refman/5.6/en/mrr- optimization.html
13.
要約すると BKA JOINは駆動表のJOINキーをバッファリングした 後、ストレージエンジンにまとめて送る。 内部表のフェッチはストレージエンジンで行われる。 ストレージエンジンとのやり取り回数が減るので、 オーバーヘッドが低減。 内部表はMRRにより最適な順番でフェッチされる ため、ランダムアクセスI/Oが低減。
14.
BNL JOINより だいぶ早そうですね!!
15.
BKA JONがICPとMRRの上に立脚しているイメージ
BKA JOIN ICP + MRR http://www.flickr.com/photos/robwithtwobs/310185817/
16.
お薦め書籍 本当はソースを理解して、内部までお話したかったのですが、
力不足でした・・・>< 興味のある方は sql/sql_select.cc あたりからぜひ読んでみてください。
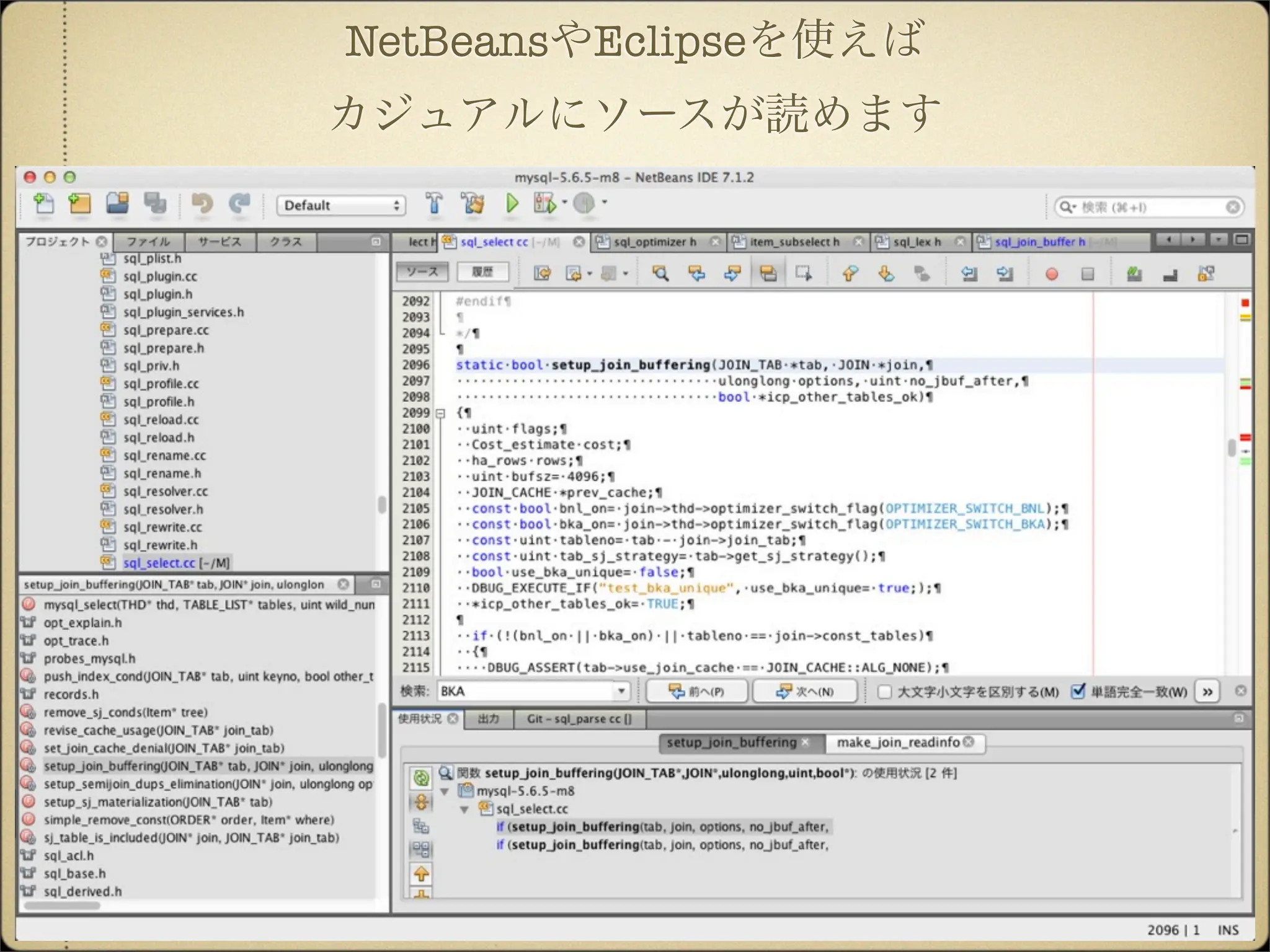
17.
NetBeansやEclipseを使えば カジュアルにソースが読めます
18.
まとめ
MySQLは ドキュメント、書籍、 ブログエントリが充実していて、 初学者でも取っ付きやすい カジュアルな データベースである。
19.
Facebookのグループにも
ぜひご参加ください 福岡インフラ勉強会 https://www.facebook.com/groups/100825430047874/
20.
ご清聴ありがとう ございました。
Download