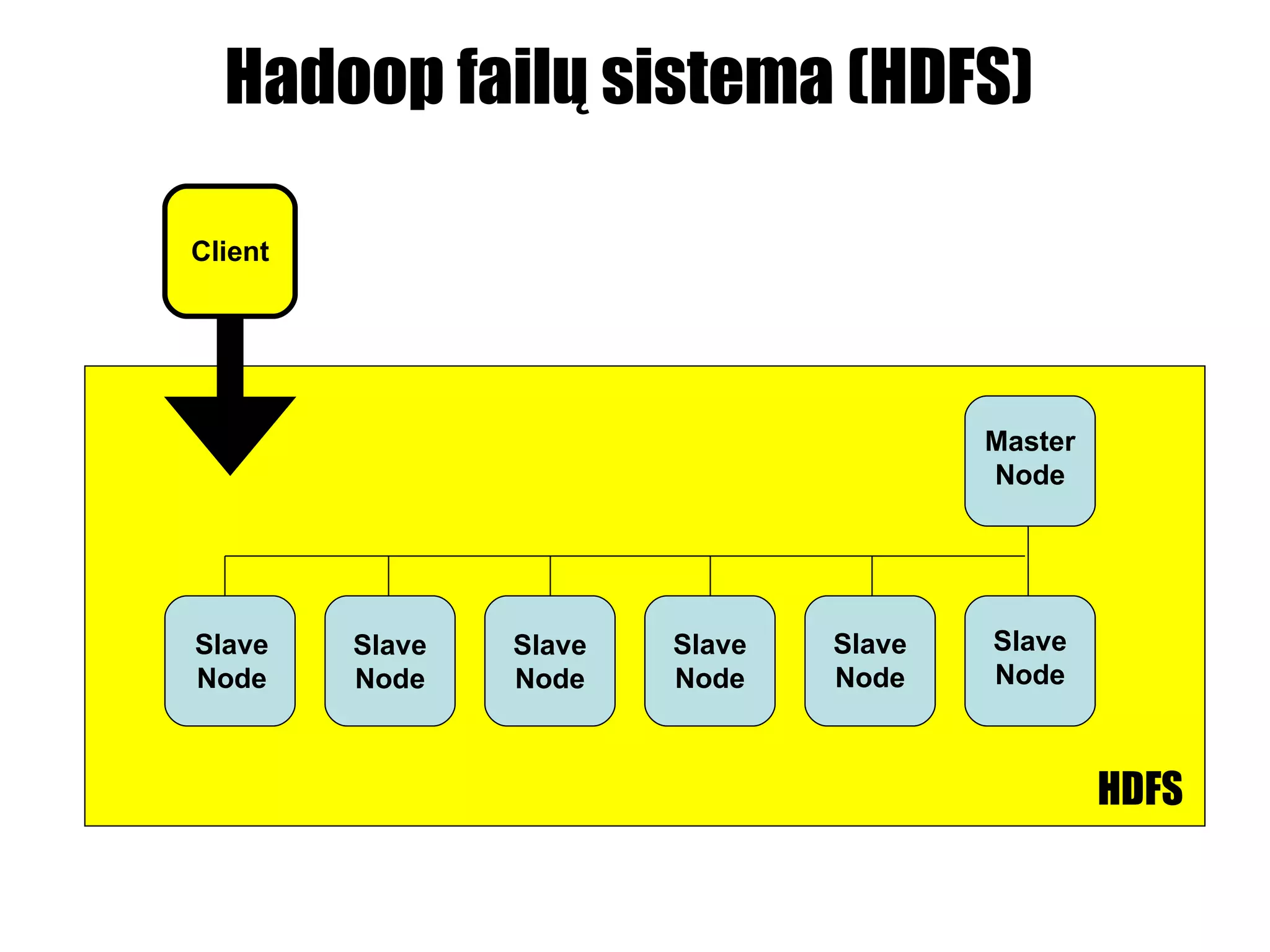
Problema Nr. 1Didelės apimties informaciją. Nuskaitymas ir įrašymas į kietąjį diską daug lėtesnis negu duomenų apdorojimo sparta.
3.
Sprendimas Vietoj vienoHDD naudoti 100, 1000… 1 HDD – 75Mb/s 1000 HDD – 75Gb/s Procesas prie duomenų, o ne duomenys prie proceso.
4.
Problema Nr. 2Reikia parašyti ne tik pačia aplikaciją, bet ir duomenų paskirstymo aplikaciją. Taigi, reikia būti dviejų sričių specialstu.
5.
Kas yra Hadoop?Hadoop yra atviro-kodo Google MapReduce implementacija, kurią sukūrė Apache. Naudojant Hadoop, high-level programuotoju i nereikia gilitnis į paskirst ymo sistemą (distributed computing) .
6.
Šiuo metu Hadoopnaudoja daugybė stambių įmonių, tarp kurių tokios kaip: Facebook, Amazon,Yahoo, IBM, veoh... Naudojama: Log ų procesingas Interneto crawlinimas ir indeksavimas Data warehousingas Pagrindiniai algoritmai: Entity-Reduce Sort Join Inverted Index
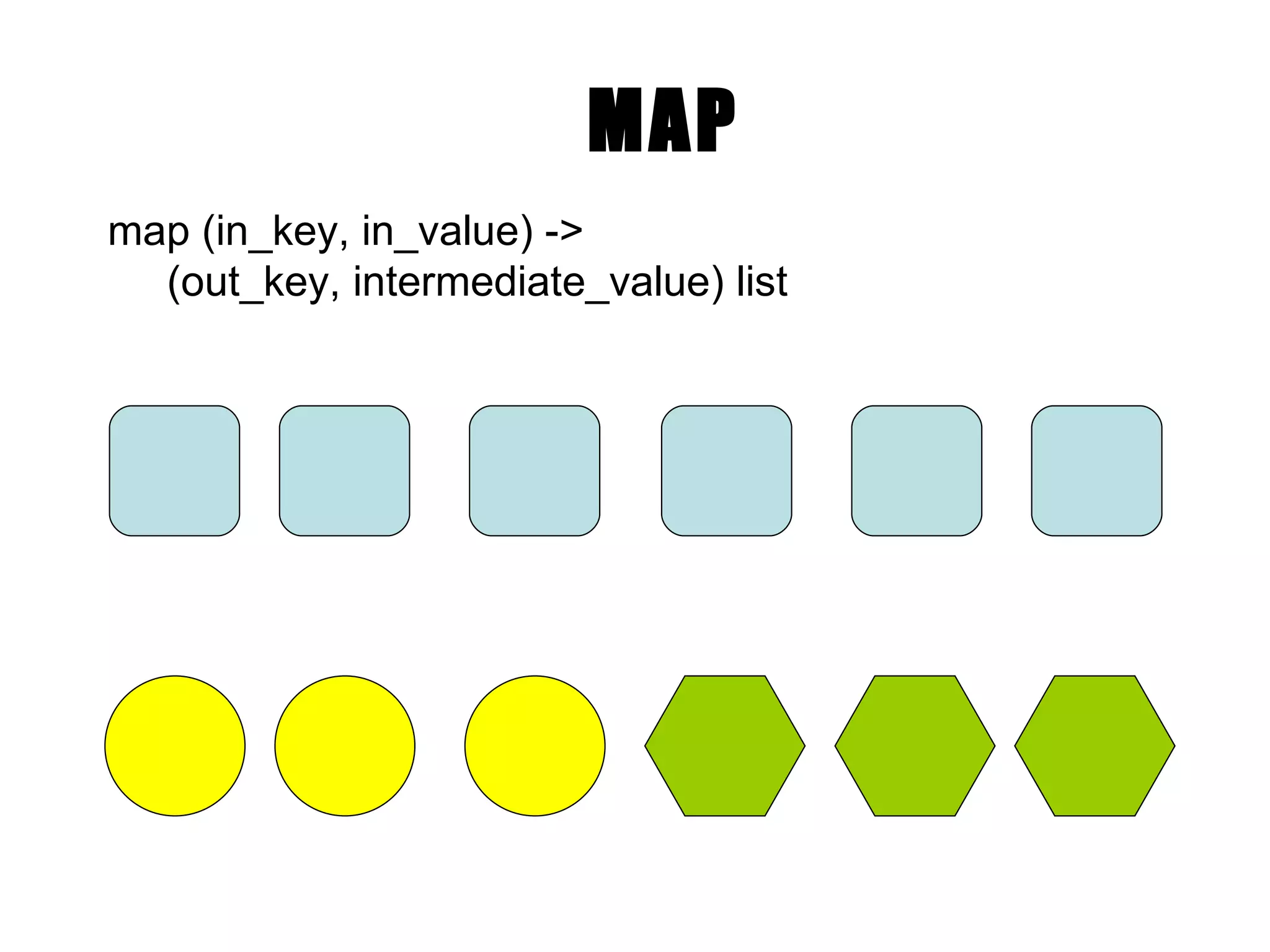
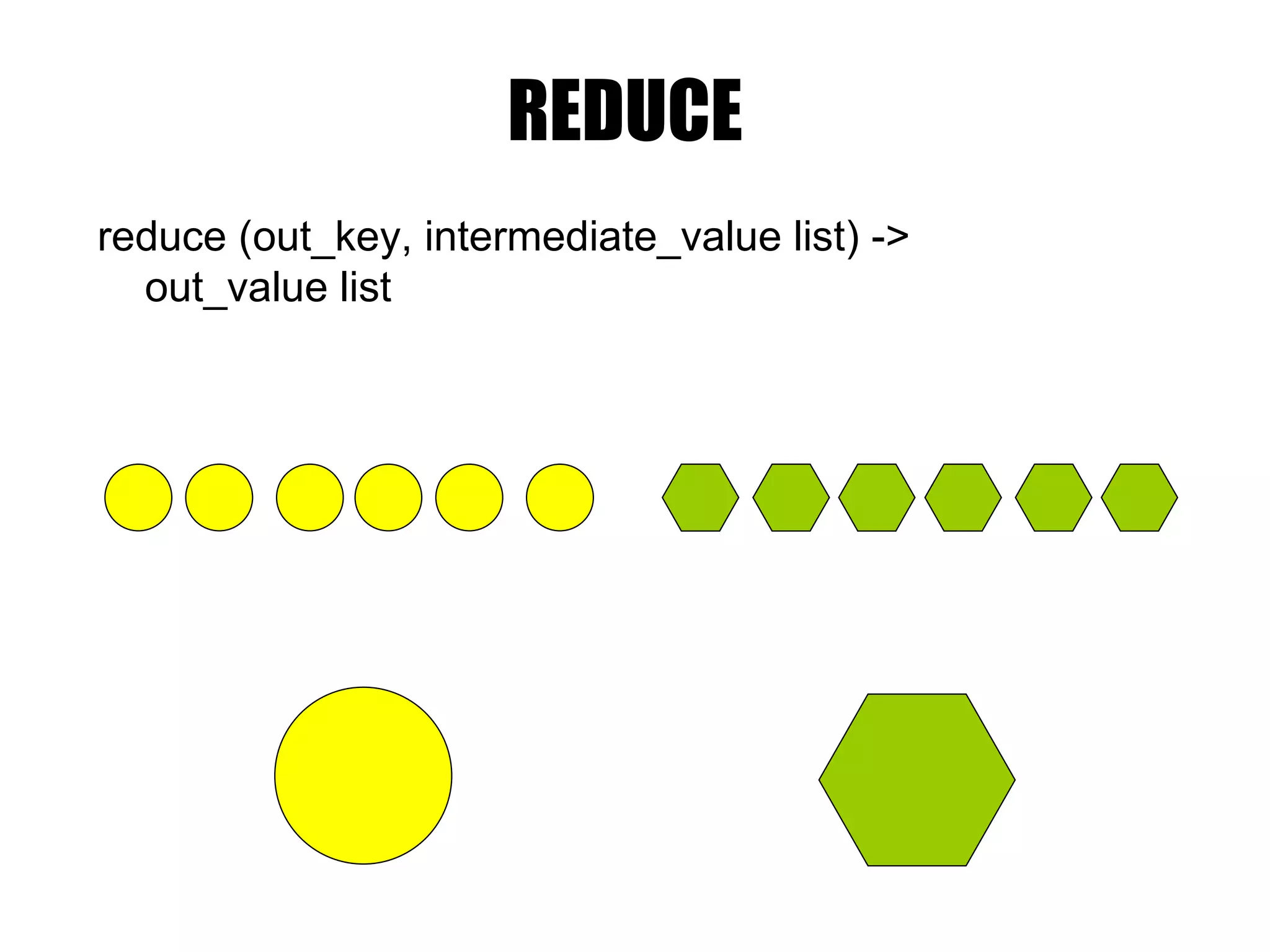
MapReduce MapReduce programaapdoroja duomenis esančius HDFS. MapReduce užduotį atlieka per du etapus Map ir Reduce. Kiekviename etape naudojama rakto ir reikšmės (key-value) įvestis ir įšvestis.
Pavyzdys : SumReducer let reduce(k , vals ) = sum = 0 foreach int v in vals: sum += v emit (k, sum) ( “a” [1,1] ) (“ a ”, 2 ) (“ m ”, [ 1 ]) (“ m ”, 1 ) (“ b ”, [ 1 ]) (“ b ”, 1 ) (“ p ”, [ 1 ]) (“ p ”, 1 ) (“ c ”, [ 1 ]) (“ c ”, 1 ) (“ r ”, [ 1 ]) (“ r ”, 1 )









![Pavyzdys : Sum Reducer let reduce(k , vals ) = sum = 0 foreach int v in vals: sum += v emit (k, sum) ( “a” [1,1] ) (“ a ”, 2 ) (“ m ”, [ 1 ]) (“ m ”, 1 ) (“ b ”, [ 1 ]) (“ b ”, 1 ) (“ p ”, [ 1 ]) (“ p ”, 1 ) (“ c ”, [ 1 ]) (“ c ”, 1 ) (“ r ”, [ 1 ]) (“ r ”, 1 )](https://image.slidesharecdn.com/hadoop-100205182923-phpapp02/75/Hadoop-12-2048.jpg)